













用DB2 pureXML執行不區分大小寫的高效搜索
根據定義,XML 元素和屬性的值是區分大小寫的。例如,如果搜索值為 “Paris” 的
下面的示例幫助您更清楚地理解不區分大小寫的搜索。清單 1 定義一個包含一個 INTEGER 列和一個 XML 列的表,并在表中插入 7 行。每行包含一個小的客戶文檔,其中包含 XML 元素
此元素中的值在大小寫方面并不一致。一些值是全大寫的,一些是全小寫的,其他是大小寫混合的(首字母大寫)。如果數據來自不同的應用程序,而這些應用程序采用不同的大小寫數據輸入規則,就會出現這種情況。
清單 1. 示例表和數據
CREATE TABLE customer (id INTEGER, xmldoc XML);
INSERT INTO customer (id, xmldoc)
VALUES (1,'<Customer id="1"><city>PARIS</city></Customer>'),
(2,'<Customer id="2"><city>Tokyo</city></Customer>'),
(3,'<Customer id="3"><city>tokyo</city></Customer>'),
(4,'<Customer id="4"><city>PARIS</city></Customer>'),
(5,'<Customer id="5"><city>paris</city></Customer>'),
(6,'<Customer id="6"><city>Delhi</city></Customer>'),
(7,'<Customer id="7"><city>Paris</city></Customer>'); |
如果一個應用程序查詢這些 XML 文檔,尋找某一城市的客戶,那么很可能需要不區分大小寫的搜索。例如,可能希望找到 Paris 的所有客戶,也就是希望獲取第 1、4、5 和 7 行。但是,如果搜索值 “Paris”,那么只會返回第 7 行。要想獲取所需的所有四行,可以使用 XQuery 函數 fn:upper-case() 把 city 元素值轉換為大寫并與 “PARIS” 做比較。清單 2 中的查詢就采用這種方式,它會返回 Paris 的所有四個客戶。
清單 2. 選擇 Paris 的客戶
|
如果查詢通過一個參數標志提供搜索值,那么這個參數也應該轉換為大寫,見 清單 3。這個參數標志(“?”)的類型為 VARCHAR(15) 并作為變量 “c” 傳遞給 XQuery 謂詞。
清單 3. 使用參數標志選擇客戶
|
圖 1 顯示以上示例查詢的輸出。
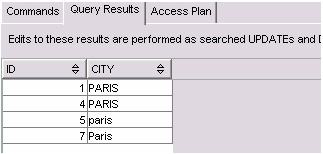
圖 1. 示例查詢的結果
如果只查詢少量數據,或者查詢還包含其他選擇性謂詞,使得大寫謂詞只應用于很小的中間結果集,那么這種方式效果還不錯。問題是如果使用包含 fn:upper-case() 函數的謂詞,就不會使用 DB2 中的 XML 索引。因此,這種方式不適用于大量數據。
要想避免使用 fn:upper-case() 函數并利用 XML 索引加快查詢,就需要創建不區分大小寫的數據庫。
創建不區分大小寫的 DB2 數據庫
DB2 從 Version 9.5 Fixpack 1 開始支持感知地區的 Unicode 排序規則。這使我們能夠忽略大小寫和/或重音符號。要想創建對于所有字符串比較不區分大小寫的數據庫,需要使用排序規則 UCA500R1,見 清單 4。
清單 4. 創建不區分大小寫的數據庫
|
字符串 UCA500R1_LEN_S2 究竟意味著什么?UCA500R1 指定此數據庫使用基于 Unicode 5.0.0 標準的默認 Unicode Collation Algorithm(UCA)。因為默認的 UCA 不能同時覆蓋 Unicode 支持的每種語言的排序規則序列,所以可以使用可選屬性定制字符的次序。屬性以下劃線(_)分隔。UCA500R1 關鍵字加上所有屬性構成一個 UCA 排序規則名。
清單 4 中使用的排序規則名包含兩個屬性:LEN 和 S2。LEN 是 L(語言)和 EN(英語的 ISO 639-1 語言編碼)的組合。第二個屬性 S2 指定強度級別,這決定在字符串排序或比較時是否考慮大小寫或重音符號。在 清單 4 中使用強度級別 2,所以 “PARIS” 和 “paris” 是相等的。下面是其他有效值的示例:
UCA500R1_LEN_S1 導致 "cliche" = "Cliche" = "cliché"
UCA500R1_LEN_S2 導致 "cliche" = "Cliche" < "cliché"
UCA500R1_LEN_S3 導致 "cliche" < "Cliche" < "cliché"
在 DB2 Information Center 中可以找到可以作為 UCA 排序規則名的所有組合(參見 參考資料)。
在不區分大小寫的數據庫中查詢 XML 數據
因為此數據庫使用排序規則名 UCA500R1 和強度級別 2,所以現在可以簡化前面的查詢,去掉 fn:upper-case() 函數(清單 5),就像所有數據都是大寫的一樣。無論搜索字符串是 “Paris” 或 “PARIS” 還是其他任何大小寫組合,結果都是相同的。
清單 5. 選擇 Paris 的客戶
|
圖 2. 示例查詢的結果
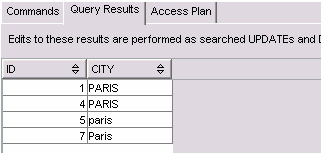
如果通過添加 ORDER BY 子句按提取的 city 值排序,那么結果集仍然是相同的:PARIS、paris 和 Paris 被當作相同的值。
為了高效地查詢此數據,尤其是在表中行數很大的情況下,應該用 XPath /Customer/city 創建一個 XML 索引,見 清單 6:
清單 6. 創建 XML 索引
|
現在,如果用 Visual Explain 或 db2exfmt 解釋此查詢,就會看到這個不區分大小寫的搜索使用了索引:
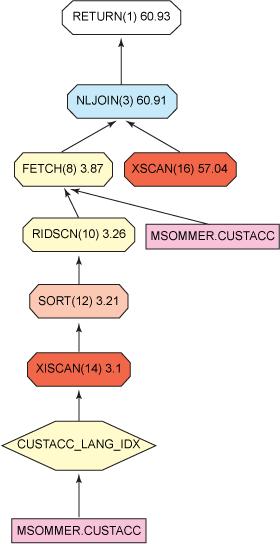
圖 3. 在不區分大小寫的數據庫中查詢 Paris 的所有客戶的 Explain Plan
本節介紹的方法有一個潛在的缺點:整個數據庫中所有表中的所有列中的所有數據都是不區分大小寫的。不可能以區分大小寫的方式處理特定的表或列。要么都區分大小寫,要么都不區分。
注意,不區分大小寫只應用于元素和屬性值,而不應用于標記名本身。XML 標記和路徑表達式仍然是區分大小寫的。例如,XPath 表達式 /Customer/city(小寫 “c”)和 /Customer/City(大寫 “C”)是不同的。后者不匹配示例數據中的任何元素,因為示例數據中的
性能
在數據庫中使用定制的排序規則可能影響查詢性能,因為在選擇更寬松的 UCA 設置時,匹配的字符串數量可能會增加。換句話說,在不區分大小寫的數據庫中,字符串比較的開銷可能會略微增加。為了查明區分大小寫的和不區分大小寫的數據庫之間的性能差異,我們創建了一個常規數據庫(區分大小寫)和一個不區分大小寫的數據庫。然后,插入來自 TPoX 基準測試的 20,000 個 CustAcc 文檔并在這兩個數據庫中對各種查詢進行測試。
對于只涉及少量到中等數量的行的查詢,兩個測試數據庫之間的性能差異可以忽略不計。我們發現涉及大量行的查詢的性能差異比較大,比如對所有 20,000 個 XML 文檔進行全表掃描并對每個文檔比較字符串。在不區分大小寫的數據庫中,這種查詢花費的時間增加了 5% 到 8%。因此,實現不區分大小寫的搜索需要付出的代價并不大。
結束語
以不區分大小寫的方式搜索 DB 2 數據有多種方法,比如使用生成的列(請參見 參考資料)。盡管這些方法都適合關系數據,但是不適合查詢 XML 數據。以不區分大小寫的方式處理 XML 數據的最佳方法是用定制的 Unicode 排序規則創建數據庫。這使數據庫中的所有字符串值比較都采用不區分大小寫的方式,避免妨礙使用 XML 索引和關系索引。由于不區分大小寫或重音符號,會增加匹配的字符串,但是增加的開銷非常低。
【編輯推薦】










