













詳解通過結合文件系統給數據庫瘦身
作者:雨中漫步的太陽
通過文件系統給數據庫瘦身,就是將數據庫中的大數據,不參與搜索的數據通過文件流的方式序列化到硬盤的某個位置的瘦身方法。本文作者希望通過本文,起到拋磚引玉的作用。
通過文件系統給數據庫瘦身,就是將數據庫中的大數據,不參與搜索的數據通過文件流的方式序列化到硬盤的某個位置,存儲位置使用hash路徑,即通過數據庫表主鍵生成hashcode 然后兩兩切分實現一個hash路徑,保證一個目錄下面的子文件和文件個數最多198個,保證了系統的檢索速度.
這里的大數據舉一個例子就是,比如公司表中,一般都有公司簡介,但是公司簡介這個列的內容量比這個整條數據的體積都大,而公司簡介根本不參與搜索,列表等操作,我們就可以講這個數據提出來,放到文件系統中,等需要的時候我們再把它讀取出來,如果修改了就重新保存.
程序實現的目標和目的就是這樣了.
由于公司使用Ibatis作為數據庫層的處理框架,接下來的任務就是修改Ibatis源代碼實現上述目標.
至于如何修改Ibatis,我會后續寫文章來介紹. 這里我們先討論下這個方案的可行性
為了一個更直接的印象,先看看具體的效果

數據庫的字段

這里可以看到 數據字段只有四個,比對象少了兩個字段
那兩個字段就會被存儲到文件系統中

執行了插入操作,以下是日志文件

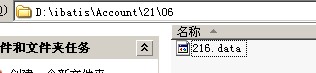
對應的文件系統中的文件

用二進制的方式打開這個文件可以看到

讀取單條數據
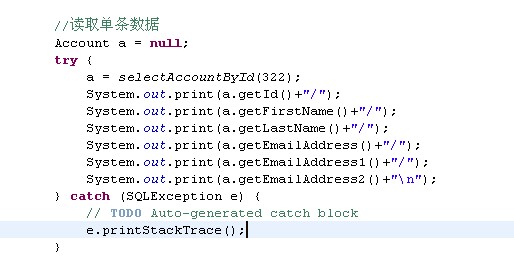
讀取結果

雖然程序使用java寫的,但是Ibatis也有.net版本基本應該差不多,而我更加喜歡博客園的活躍,就發到這里了 ,大家討論下 這樣做到底有沒有好處
【編輯推薦】
責任編輯:彭凡
來源:
cnblogs











