













深入了解MySQL 5.5分區(qū)功能增強(qiáng)
原創(chuàng)【51CTO經(jīng)典譯文】MySQL 5.5的發(fā)布帶來了許多增強(qiáng)的功能,雖然已經(jīng)報(bào)道了很多增強(qiáng)功能,如半同步復(fù)制,但大家卻忽略了分區(qū)方面的增強(qiáng),有時(shí)甚至還對其真正意義產(chǎn)生了誤解,在這篇文章中,我們希望解釋一下這些很酷的增強(qiáng),特別是我們大多數(shù)人還沒有完全理解的地方。51CTO向您推薦《MySQL數(shù)據(jù)庫入門與精通教程》。

圖 1 大家還沒注意到我MySQL的分區(qū)功能也很強(qiáng)了哦
非整數(shù)列分區(qū)
任何使用過分區(qū)的人應(yīng)該都遇到過不少問題,特別是面對非整數(shù)列分區(qū)時(shí),MySQL 5.1只能處理整數(shù)列分區(qū),如果你想在日期或字符串列上進(jìn)行分區(qū),你不得不使用函數(shù)對其進(jìn)行轉(zhuǎn)換。
MySQL 5.5中新增了兩類分區(qū)方法,RANG和LIST分區(qū)法,同時(shí)在新的函數(shù)中增加了一個(gè)COLUMNS關(guān)鍵詞。我們假設(shè)有這樣一個(gè)表:
- CREATE TABLE expenses (
- expense_date DATE NOT NULL,
- category VARCHAR(30),
- amount DECIMAL (10,3)
- );
如果你想使用MySQL 5.1中的分區(qū)類型,那你必須將類型轉(zhuǎn)換成整數(shù),需要使用一個(gè)額外的查找表,到了MySQL 5.5中,你可以不用再進(jìn)行類型轉(zhuǎn)換了,如:
- ALTER TABLE expenses
- PARTITION BY LIST COLUMNS (category)
- (
- PARTITION p01 VALUES IN ( 'lodging', 'food'),
- PARTITION p02 VALUES IN ( 'flights', 'ground transportation'),
- PARTITION p03 VALUES IN ( 'leisure', 'customer entertainment'),
- PARTITION p04 VALUES IN ( 'communications'),
- PARTITION p05 VALUES IN ( 'fees')
- );
這樣的分區(qū)語句除了更加易讀外,對數(shù)據(jù)的組織和管理也非常清晰,上面的例子只對category列進(jìn)行分區(qū)。
在MySQL 5.1中使用分區(qū)另一個(gè)讓人頭痛的問題是date類型(即日期列),你不能直接使用它們,必須使用YEAR或TO_DAYS轉(zhuǎn)換這些列,如:
- /* 在MySQL 5.1中*/
- CREATE TABLE t2
- (
- dt DATE
- )
- PARTITION BY RANGE (TO_DAYS(dt))
- (
- PARTITION p01 VALUES LESS THAN (TO_DAYS('2007-01-01')),
- PARTITION p02 VALUES LESS THAN (TO_DAYS('2008-01-01')),
- PARTITION p03 VALUES LESS THAN (TO_DAYS('2009-01-01')),
- PARTITION p04 VALUES LESS THAN (MAXVALUE));
- SHOW CREATE TABLE t2 \G
- *************************** 1. row ***************************
- Table: t2
- Create Table: CREATE TABLE `t2` (
- `dt` date DEFAULT NULL
- ) ENGINE=MyISAM DEFAULT CHARSET=latin1
- /*!50100 PARTITION BY RANGE (TO_DAYS(dt))
- (PARTITION p01 VALUES LESS THAN (733042) ENGINE = MyISAM,
- PARTITION p02 VALUES LESS THAN (733407) ENGINE = MyISAM,
- PARTITION p03 VALUES LESS THAN (733773) ENGINE = MyISAM,
- PARTITION p04 VALUES LESS THAN MAXVALUE ENGINE = MyISAM) */
看上去非常糟糕,當(dāng)然也有變通辦法,但麻煩確實(shí)不少。使用YEAR或TO_DAYS定義一個(gè)分區(qū)的確讓人費(fèi)解,查詢時(shí)不得不使用赤裸列,因?yàn)榧恿撕瘮?shù)的查詢不能識別分區(qū)。
但在MySQL 5.5中情況發(fā)生了很大的變化,現(xiàn)在在日期列上可以直接分區(qū),并且方法也很簡單。
- /*在MySQL 5.5中*/
- CREATE TABLE t2
- (
- dt DATE
- )
- PARTITION BY RANGE COLUMNS (dt)
- (
- PARTITION p01 VALUES LESS THAN ('2007-01-01'),
- PARTITION p02 VALUES LESS THAN ('2008-01-01'),
- PARTITION p03 VALUES LESS THAN ('2009-01-01'),
- PARTITION p04 VALUES LESS THAN (MAXVALUE));
- SHOW CREATE TABLE t2 \G
- *************************** 1. row ***************************
- Table: t2
- Create Table: CREATE TABLE `t2` (
- `dt` date DEFAULT NULL
- ) ENGINE=MyISAM DEFAULT CHARSET=latin1
- /*!50500 PARTITION BY RANGE COLUMNS(dt)
- (PARTITION p01 VALUES LESS THAN ('2007-01-01') ENGINE = MyISAM,
- PARTITION p02 VALUES LESS THAN ('2008-01-01') ENGINE = MyISAM,
- PARTITION p03 VALUES LESS THAN ('2009-01-01') ENGINE = MyISAM,
- PARTITION p04 VALUES LESS THAN (MAXVALUE) ENGINE = MyISAM) */
在這里,通過函數(shù)定義和通過列查詢之間沒有沖突,因?yàn)槭前戳卸x的,我們在定義中插入的值是保留的。
多列分區(qū)
COLUMNS關(guān)鍵字現(xiàn)在允許字符串和日期列作為分區(qū)定義列,同時(shí)還允許使用多個(gè)列定義一個(gè)分區(qū),你可能在官方文檔中已經(jīng)看到了一些例子,如:
- CREATE TABLE p1 (
- a INT,
- b INT,
- c INT
- )
- PARTITION BY RANGE COLUMNS (a,b)
- (
- PARTITION p01 VALUES LESS THAN (10,20),
- PARTITION p02 VALUES LESS THAN (20,30),
- PARTITION p03 VALUES LESS THAN (30,40),
- PARTITION p04 VALUES LESS THAN (40,MAXVALUE),
- PARTITION p05 VALUES LESS THAN (MAXVALUE,MAXVALUE)
- );
- CREATE TABLE p2 (
- a INT,
- b INT,
- c INT
- )
- PARTITION BY RANGE COLUMNS (a,b)
- (
- PARTITION p01 VALUES LESS THAN (10,10),
- PARTITION p02 VALUES LESS THAN (10,20),
- PARTITION p03 VALUES LESS THAN (10,30),
- PARTITION p04 VALUES LESS THAN (10,MAXVALUE),
- PARTITION p05 VALUES LESS THAN (MAXVALUE,MAXVALUE)
- )
同樣還有PARTITION BY RANGE COLUMNS (a,b,c)等其它例子。由于我很長時(shí)間都在使用MySQL 5.1的分區(qū),我對多列分區(qū)的含義不太了解,LESS THAN (10,10)是什么意思?如果下一個(gè)分區(qū)是LESS THAN (10,20)會發(fā)生什么?相反,如果是(20,30)又會如何?
所有這些問題都需要一個(gè)答案,在回答之前,他們需要更好地理解我們在做什么。
開始時(shí)可能有些混亂,當(dāng)所有分區(qū)有一個(gè)不同范圍的值時(shí),實(shí)際上,它只是在表的一個(gè)列上進(jìn)行了分區(qū),但事實(shí)并非如此,在下面的例子中:
- CREATE TABLE p1_single (
- a INT,
- b INT,
- c INT
- )
- PARTITION BY RANGE COLUMNS (a)
- (
- PARTITION p01 VALUES LESS THAN (10),
- PARTITION p02 VALUES LESS THAN (20),
- PARTITION p03 VALUES LESS THAN (30),
- PARTITION p04 VALUES LESS THAN (40),
- PARTITION p05 VALUES LESS THAN (MAXVALUE)
- );
它和前面的表p1不一樣,如果你在表p1中插入(10,1,1),它將會進(jìn)入***個(gè)分區(qū),相反,在表p1_single中,它將會進(jìn)入第二個(gè)分區(qū),其原因是(10,1)小于(10,10),如果你僅僅關(guān)注***個(gè)值,你還沒有意識到你在比較一個(gè)元組,而不是一個(gè)單一的值。
現(xiàn)在我們來分析一下最難懂的地方,當(dāng)你需要確定某一行應(yīng)該放在哪里時(shí)會發(fā)生什么?你是如何確定類似(10,9) < (10,10)這種運(yùn)算的值的?答案其實(shí)很簡單,當(dāng)你對它們進(jìn)行排序時(shí),使用相同的方法計(jì)算兩條記錄的值。
- a=10
- b=9
- (a,b) < (10,10) ?
- # evaluates to:
- (a < 10)
- OR
- ((a = 10) AND ( b < 10))
- # which translates to:
- (10 < 10)
- OR
- ((10 = 10) AND ( 9 < 10))
如果有三列,表達(dá)式會更長,但不會更復(fù)雜。你首先在***個(gè)項(xiàng)目上測試小于運(yùn)算,如果有兩個(gè)或更多的分區(qū)與之匹配,接著就測試第二個(gè)項(xiàng)目,如果不止一個(gè)候選分區(qū),那還需要測試第三個(gè)項(xiàng)目。
下圖所顯示的內(nèi)容表示將遍歷三條記錄插入到使用以下代碼定義的分區(qū)中:
(10,10),
(10,20),
(10,30),
(10, MAXVALUE)
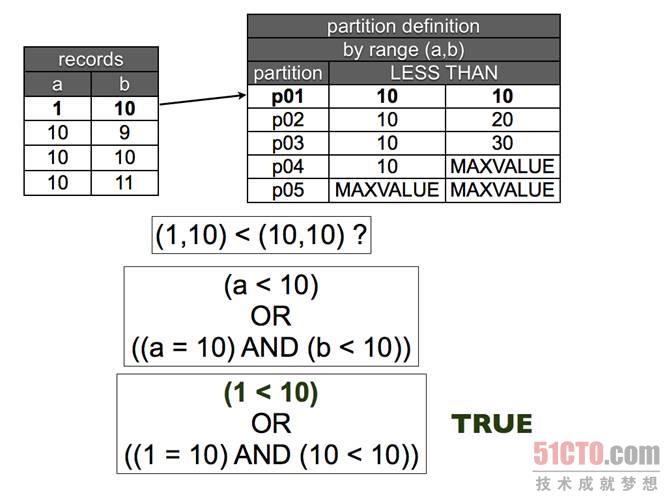
圖 2 元組比較。當(dāng)***個(gè)值小于分區(qū)定義的***個(gè)范圍時(shí),那么該行將屬于這里了。
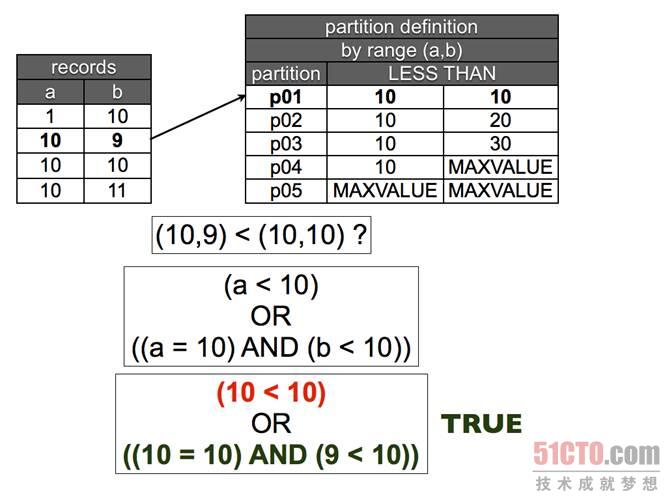
圖 3 元組比較。當(dāng)***個(gè)值等于分區(qū)定義的***個(gè)范圍,我們需要比較第二個(gè)項(xiàng)目,如果它小于第二個(gè)范圍,那么該行將屬于這里了。
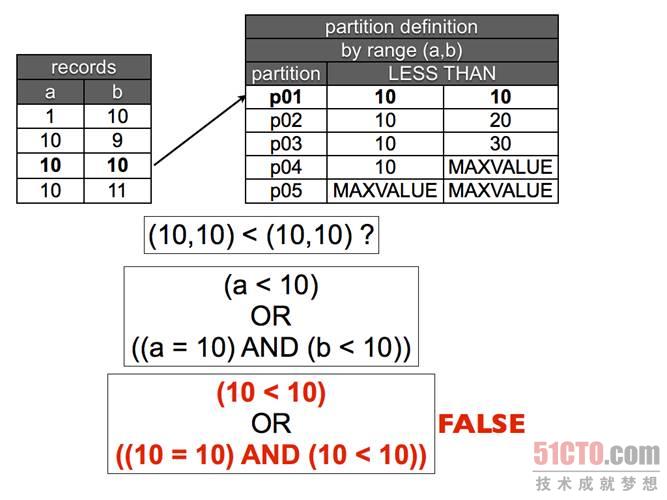
圖 4 元組比較。當(dāng)***個(gè)值和第二個(gè)值等于他們對應(yīng)的范圍時(shí),如果元組不小于定義的范圍,那么它就不屬于這里,繼續(xù)下一步。
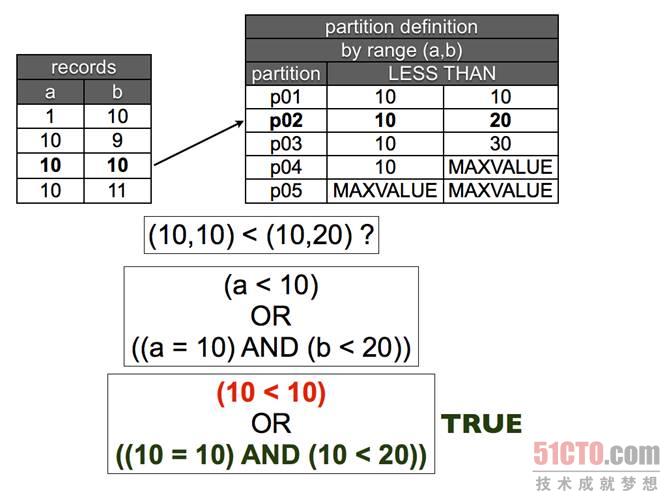
圖 5 元組比較。在下一個(gè)范圍時(shí),***個(gè)項(xiàng)目是等于,第二個(gè)項(xiàng)目是小于,因此元組更小,那么該行就屬于這里了。
在這些圖的幫助下,我們對插入一條記錄到多列分區(qū)表的步驟有了更深的了解,這些都是理論上的,為了幫助你更好地掌握新功能,我們再來看一個(gè)更高級一點(diǎn)的例子,對于比較務(wù)實(shí)的讀者更有意義,下面是表的定義腳本:
- CREATE TABLE employees (
- emp_no int(11) NOT NULL,
- birth_date date NOT NULL,
- first_name varchar(14) NOT NULL,
- last_name varchar(16) NOT NULL,
- gender char(1) DEFAULT NULL,
- hire_date date NOT NULL
- ) ENGINE=MyISAM
- PARTITION BY RANGE COLUMNS(gender,hire_date)
- (PARTITION p01 VALUES LESS THAN ('F','1990-01-01') ,
- PARTITION p02 VALUES LESS THAN ('F','2000-01-01') ,
- PARTITION p03 VALUES LESS THAN ('F',MAXVALUE) ,
- PARTITION p04 VALUES LESS THAN ('M','1990-01-01') ,
- PARTITION p05 VALUES LESS THAN ('M','2000-01-01') ,
- PARTITION p06 VALUES LESS THAN ('M',MAXVALUE) ,
- PARTITION p07 VALUES LESS THAN (MAXVALUE,MAXVALUE)
和上面的例子不同,這個(gè)例子更好理解,***個(gè)分區(qū)用來存儲雇傭于1990年以前的女職員,第二個(gè)分區(qū)存儲股用于1990-2000年之間的女職員,第三個(gè)分區(qū)存儲所有剩下的女職員。對于分區(qū)p04到p06,我們策略是一樣的,只不過存儲的是男職員。***一個(gè)分區(qū)是控制情況。
看完后你可能要問,我怎么知道某一行存儲在那個(gè)分區(qū)中的?有兩個(gè)辦法,***個(gè)辦法是使用與分區(qū)定義相同的條件作為查詢條件進(jìn)行查詢。
- SELECT
- CASE
- WHEN gender = 'F' AND hire_date < '1990-01-01'
- THEN 'p1'
- WHEN gender = 'F' AND hire_date < '2000-01-01'
- THEN 'p2'
- WHEN gender = 'F' AND hire_date < '2999-01-01'
- THEN 'p3'
- WHEN gender = 'M' AND hire_date < '1990-01-01'
- THEN 'p4'
- WHEN gender = 'M' AND hire_date < '2000-01-01'
- THEN 'p5'
- WHEN gender = 'M' AND hire_date < '2999-01-01'
- THEN 'p6'
- ELSE
- 'p7'
- END as p,
- COUNT(*) AS rows
- FROM employees
- GROUP BY p;
- +------+-------+
- | p | rows |
- +------+-------+
- | p1 | 66212 |
- | p2 | 53832 |
- | p3 | 7 |
- | p4 | 98585 |
- | p5 | 81382 |
- | p6 | 6 |
- +------+-------+
如果表是MyISAM或ARCHIVE,你可以信任由INFORMATION_SCHEMA提供的統(tǒng)計(jì)信息。
- SELECT
- partition_name part,
- partition_expression expr,
- partition_description descr,
- table_rows
- FROM
- INFORMATION_SCHEMA.partitions
- WHERE
- TABLE_SCHEMA = schema()
- AND TABLE_NAME='employees';
- +------+------------------+-------------------+------------+
- | part | expr | descr | table_rows |
- +------+------------------+-------------------+------------+
- | p01 | gender,hire_date | 'F','1990-01-01' | 66212 |
- | p02 | gender,hire_date | 'F','2000-01-01' | 53832 |
- | p03 | gender,hire_date | 'F',MAXVALUE | 7 |
- | p04 | gender,hire_date | 'M','1990-01-01' | 98585 |
- | p05 | gender,hire_date | 'M','2000-01-01' | 81382 |
- | p06 | gender,hire_date | 'M',MAXVALUE | 6 |
- | p07 | gender,hire_date | MAXVALUE,MAXVALUE | 0 |
- +------+------------------+-------------------+------------+
如果存儲引擎是InnoDB,上面的值就是一個(gè)近似值,如果你需要確切的值,那你就不能信任它們。
另一個(gè)問題是它的性能,這些增強(qiáng)觸發(fā)了分區(qū)修整嗎?答案毫不含糊,是的。與MySQL 5.1有所不同,在5.1中日期分區(qū)只能與兩個(gè)函數(shù)工作,在MySQL 5.5中,任何使用了COLUMNS關(guān)鍵字定義的分區(qū)都可以使用分區(qū)修整,下面還是測試一下吧。
- select count(*) from employees where gender='F' and hire_date < '1990-01-01';
- +----------+
- | count(*) |
- +----------+
- | 66212 |
- +----------+
- 1 row in set (0.05 sec)
- explain partitions select count(*) from employees where gender='F' and hire_date < '1990-01-01'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: employees
- partitions: p01
- type: ALL
- possible_keys: NULL
- key: NULL
- key_len: NULL
- ref: NULL
- rows: 300024
- Extra: Using where
使用定義***個(gè)分區(qū)的條件,我們獲得了一個(gè)非常優(yōu)化的查詢,不僅如此,部分條件也將從分區(qū)修整中受益。
- select count(*) from employees where gender='F';
- +----------+
- | count(*) |
- +----------+
- | 120051 |
- +----------+
- 1 row in set (0.12 sec)
- explain partitions select count(*) from employees where gender='F'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: employees
- partitions: p01,p02,p03,p04
- type: ALL
- possible_keys: NULL
- key: NULL
- key_len: NULL
- ref: NULL
- rows: 300024
- Extra: Using where
它和復(fù)合索引的算法一樣,如果你的條件指的是索引最左邊的部分,MySQL將會使用它。與此類似,如果你的條件指的是分區(qū)定義最左邊的部分,MySQL將會盡可能修整。它和復(fù)合索引一起出現(xiàn),如果你只使用最右邊的條件,分區(qū)修整不會工作。
- select count(*) from employees where hire_date < '1990-01-01';
- +----------+
- | count(*) |
- +----------+
- | 164797 |
- +----------+
- 1 row in set (0.18 sec)
- explain partitions select count(*) from employees where hire_date < '1990-01-01'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: employees
- partitions: p01,p02,p03,p04,p05,p06,p07
- type: ALL
- possible_keys: NULL
- key: NULL
- key_len: NULL
- ref: NULL
- rows: 300024
- Extra: Using where
如果不用分區(qū)定義的***部分,使用分區(qū)定義的第二部分,那么將會發(fā)生全表掃描,在設(shè)計(jì)分區(qū)和編寫查詢時(shí)要緊記這一條。
可用性增強(qiáng):truncate分區(qū)
分區(qū)最吸引人的一個(gè)功能是瞬間移除大量記錄的能力,DBA都喜歡將歷史記錄存儲到按日期分區(qū)的分區(qū)表中,這樣可以定期刪除過時(shí)的歷史數(shù)據(jù),這種方法相當(dāng)管用,假設(shè)***個(gè)分區(qū)存儲的是最舊的歷史記錄,那么你可以直接刪除***個(gè)分區(qū),然后再在末尾建立一個(gè)新分區(qū)保存最近的歷史記錄,這樣循環(huán)下去就可以實(shí)現(xiàn)歷史記錄的快速清除。
但當(dāng)你需要移除分區(qū)中的部分?jǐn)?shù)據(jù)時(shí),事情就不是那么簡單了,刪除分區(qū)沒有問題,但如果是清空分區(qū),就很頭痛了,要移除分區(qū)中的所有數(shù)據(jù),但需要保留分區(qū)本身,你可以:
使用DELETE語句,但我們知道DELETE語句的性能都很差。
使用DROP PARTITION語句,緊跟著一個(gè)EORGANIZE PARTITIONS語句重新創(chuàng)建分區(qū),但這樣做比前一個(gè)方法的成本要高出許多。
MySQL 5.5引入了TRUNCATE PARTITION,它和DROP PARTITION語句有些類似,但它保留了分區(qū)本身,也就是說分區(qū)還可以重復(fù)利用。TRUNCATE PARTITION應(yīng)該是DBA工具箱中的必備工具。
更多微調(diào)功能:TO_SECONDS
分區(qū)增強(qiáng)包有一個(gè)新的函數(shù)處理DATE和DATETIME列,使用TO_SECONDS函數(shù),你可以將日期/時(shí)間列轉(zhuǎn)換成自0年以來的秒數(shù),如果你想使用小于1天的間隔進(jìn)行分區(qū),那么這個(gè)函數(shù)就可以幫到你。
TO_SECONDS會觸發(fā)分區(qū)修整,與TO_DAYS不同,它可以反過來使用,就是FROM_DAYS,對于TO_SECONDS就沒有這樣的反向函數(shù)了,但要自己動手DIY一個(gè)也不是難事。
- drop function if exists from_seconds;
- delimiter //
- create function from_seconds (secs bigint)
- returns DATETIME
- begin
- declare days INT;
- declare secs_per_day INT;
- DECLARE ZH INT;
- DECLARE ZM INT;
- DECLARE ZS INT;
- set secs_per_day = 60 * 60 * 24;
- set days = floor(secs / secs_per_day);
- set secs = secs - (secs_per_day * days);
- set ZH = floor(secs / 3600);
- set ZM = floor(secs / 60) - ZH * 60;
- set ZS = secs - (ZH * 3600 + ZM * 60);
- return CAST(CONCAT(FROM_DAYS(days), ' ', ZH, ':', ZM, ':', ZS) as DATETIME);
- end //
- delimiter ;
有了這些新武器,我們可以有把握地創(chuàng)建一個(gè)小于1天的臨時(shí)分區(qū),如:
- CREATE TABLE t2 (
- dt datetime
- )
- PARTITION BY RANGE (to_seconds(dt))
- (
- PARTITION p01 VALUES LESS THAN (to_seconds('2009-11-30 08:00:00')) ,
- PARTITION p02 VALUES LESS THAN (to_seconds('2009-11-30 16:00:00')) ,
- PARTITION p03 VALUES LESS THAN (to_seconds('2009-12-01 00:00:00')) ,
- PARTITION p04 VALUES LESS THAN (to_seconds('2009-12-01 08:00:00')) ,
- PARTITION p05 VALUES LESS THAN (to_seconds('2009-12-01 16:00:00')) ,
- PARTITION p06 VALUES LESS THAN (MAXVALUE)
- );
- show create table t2\G
- *************************** 1. row ***************************
- Table: t2
- Create Table: CREATE TABLE `t2` (
- `dt` datetime DEFAULT NULL
- ) ENGINE=MyISAM DEFAULT CHARSET=latin1
- /*!50500 PARTITION BY RANGE (to_seconds(dt))
- (PARTITION p01 VALUES LESS THAN (63426787200) ENGINE = MyISAM,
- PARTITION p02 VALUES LESS THAN (63426816000) ENGINE = MyISAM,
- PARTITION p03 VALUES LESS THAN (63426844800) ENGINE = MyISAM,
- PARTITION p04 VALUES LESS THAN (63426873600) ENGINE = MyISAM,
- PARTITION p05 VALUES LESS THAN (63426902400) ENGINE = MyISAM,
- PARTITION p06 VALUES LESS THAN MAXVALUE ENGINE = MyISAM) */
因?yàn)槲覀儧]有使用COLUMNS關(guān)鍵字,我們也不能使用它,因?yàn)樗恢С只旌狭泻秃瘮?shù),表定義中的記錄值就是TO_SECONDS函數(shù)的計(jì)算結(jié)果。
但我們還是要感謝新的函數(shù),我們可以反推這個(gè)值,換算成一個(gè)更容易讀懂的日期。
- select
- partition_name part,
- partition_expression expr,
- from_seconds(partition_description) descr,
- table_rows
- FROM
- INFORMATION_SCHEMA.partitions
- WHERE
- TABLE_SCHEMA = 'test'
- AND TABLE_NAME='t2';
- +------+----------------+---------------------+------------+
- | part | expr | descr | table_rows |
- +------+----------------+---------------------+------------+
- | p01 | to_seconds(dt) | 2009-11-30 08:00:00 | 0 |
- | p02 | to_seconds(dt) | 2009-11-30 16:00:00 | 0 |
- | p03 | to_seconds(dt) | 2009-12-01 00:00:00 | 0 |
- | p04 | to_seconds(dt) | 2009-12-01 08:00:00 | 0 |
- | p05 | to_seconds(dt) | 2009-12-01 16:00:00 | 0 |
- | p06 | to_seconds(dt) | 0000-00-00 00:00:00 | 0 |
- +------+----------------+---------------------+------------+
總結(jié)
MySQL 5.5對分區(qū)用戶絕對是個(gè)好消息,雖然沒有提供直接的性能增強(qiáng)的方法(如果你按響應(yīng)時(shí)間評估性能),但更易于使用的增強(qiáng)功能,以及TRUNCATE PARTITION命令都可以為DBA節(jié)省大量的時(shí)間,有時(shí)對最終用戶亦如此。
這些增強(qiáng)的功能可能會在下一個(gè)里程碑發(fā)布時(shí)得到更新,最終版本預(yù)計(jì)會在2010年年中發(fā)布,屆時(shí)所有分區(qū)用戶都可以嘗試一下!
原文出處:http://dev.mysql.com/tech-resources/articles/mysql_55_partitioning.html
原文名:A deep look at MySQL 5.5 partitioning enhancements
作者:Giuseppe
【編輯推薦】















