十三個(gè)強(qiáng)大的Linux性能監(jiān)測(cè)工具
Linux系統(tǒng)下,大多數(shù)的性能監(jiān)測(cè)工具保存在/proc目錄下。這里我們將Linux AS 和 SUSE LINUX EnterpriseServer中的命令行及圖形方式下的性能監(jiān)測(cè)工具做概括性介紹。這些工具有些在系統(tǒng)工具盤(pán)里,有些可以從網(wǎng)上下載。sar,iostat,和pstat這三個(gè)工具在distributionCD里,也可以從網(wǎng)上下載,網(wǎng)址是http://perso.wanadoo.fr/sebastien.godard/。
51CTO推薦:Linux監(jiān)控工具的展覽館
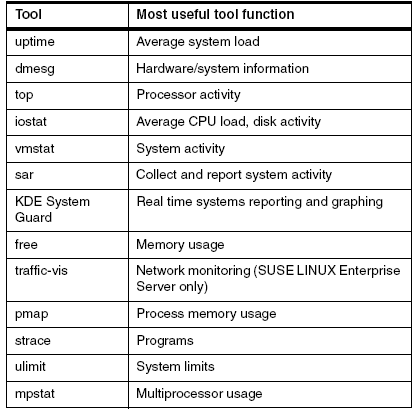
表--Linux性能監(jiān)測(cè)工具
這些工具提供了IBM Director Capacity Manager之外的一些功能,能夠在某個(gè)時(shí)間段內(nèi)對(duì)系統(tǒng)性能進(jìn)行監(jiān)測(cè)。IBM Director適用于多種操作系統(tǒng)平臺(tái),從而使得異構(gòu)環(huán)境下數(shù)據(jù)的收集和分析更容易。下面分三部分逐個(gè)介紹每個(gè)命令。
#p#
1、uptime
uptime命令用于查看服務(wù)器運(yùn)行了多長(zhǎng)時(shí)間以及有多少個(gè)用戶(hù)登錄,快速獲知服務(wù)器的負(fù)荷情況。
uptime的輸出包含一項(xiàng)內(nèi)容是load average,顯示了最近1-,5-,15分鐘的負(fù)荷情況。它的值代表等待CPU處理的進(jìn)程數(shù),如果CPU沒(méi)有時(shí)間處理這些進(jìn)程,load average值會(huì)升高;反之則會(huì)降低。
load average的***值是1,說(shuō)明每個(gè)進(jìn)程都可以馬上處理并且沒(méi)有CPU cycles被丟失。對(duì)于單CPU的機(jī)器,1或者2是可以接受的值;對(duì)于多路CPU的機(jī)器,load average值可能在8到10之間。
也可以使用uptime命令來(lái)判斷網(wǎng)絡(luò)性能。例如,某個(gè)網(wǎng)絡(luò)應(yīng)用性能很低,通過(guò)運(yùn)行uptime查看服務(wù)器的負(fù)荷是否很高,如果不是,那么問(wèn)題應(yīng)該是網(wǎng)絡(luò)方面造成的。
下邊是uptime的輸出樣式
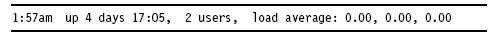
2、dmesg
dmesg命令主要用來(lái)顯示內(nèi)核信息。使用dmesg可以有效診斷機(jī)器硬件故障或者添加硬件出現(xiàn)的問(wèn)題。
另外,使用dmesg可以確定您的服務(wù)器安裝了那些硬件。每次系統(tǒng)重啟,系統(tǒng)都會(huì)檢查所有硬件并將信息記錄下來(lái)。執(zhí)行/bin/dmesg命令可以查看該記錄。
下邊是dmesg的輸出樣式

#p#
3、top
top命令顯示處理器的活動(dòng)狀況。缺省情況下,顯示占用CPU最多的任務(wù),并且每隔5秒鐘做一次刷新。
3.1 Process priority and nice levels
Process priority的數(shù)值決定了CPU處理進(jìn)程的順序。LIUNX內(nèi)核會(huì)根據(jù)需要調(diào)整該數(shù)值的大小。nicevalue局限于priority。priority的值不能低于nice value(nicevalue值越低,優(yōu)先級(jí)越高)。您不可以直接修改Process priority的值,但是可以通過(guò)調(diào)整nicelevel值來(lái)間接地改變Process priority值,然而這一方法并不是所有時(shí)候都可用。如果某個(gè)進(jìn)程運(yùn)行異常的慢,可以通過(guò)降低nicelevel為該進(jìn)程分配更多的CPU。
Linux 支持的 nice levels 由19 (優(yōu)先級(jí)低)到-20 (優(yōu)先級(jí)高),缺省值為0。
執(zhí)行/bin/ps命令可以查看到當(dāng)前進(jìn)程的情況。
4、iostat
iostat由Red Hat Enterprise Linux AS發(fā)布。同時(shí)iostat也是Sysstat的一部分,可以下載到,網(wǎng)址是http://perso.wanadoo.fr/sebastien.godard/
執(zhí)行iostat命令可以從系統(tǒng)啟動(dòng)之后的CPU平均時(shí)間,類(lèi)似于uptime。除此之外,iostat還對(duì)創(chuàng)建一個(gè)服務(wù)器磁盤(pán)子系統(tǒng)的活動(dòng)報(bào)告。該報(bào)告包含兩部分:CPU使用情況和磁盤(pán)使用情況。
下邊是iostat的輸出樣式
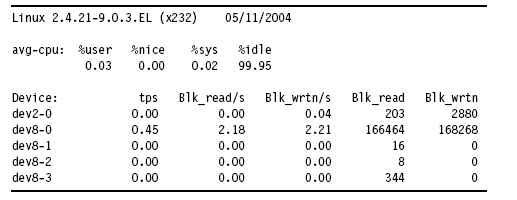
CPU占用情況包括四塊內(nèi)容
%user:顯示user level (applications)時(shí),CPU的占用情況。
%nice:顯示user level在nice priority時(shí),CPU的占用情況。
%sys:顯示system level (kernel)時(shí),CPU的占用情況。
%idle: 顯示CPU空閑時(shí)間所占比例。
磁盤(pán)使用報(bào)告分成以下幾個(gè)部分:
Device: 塊設(shè)備的名字
tps: 該設(shè)備每秒I/O傳輸?shù)拇螖?shù)。多個(gè)I/O請(qǐng)求可以組合為一個(gè),每個(gè)I/O請(qǐng)求傳輸?shù)淖止?jié)數(shù)不同,因此可以將多個(gè)I/O請(qǐng)求合并為一個(gè)。
Blk_read/s, Blk_wrtn/s: 表示從該設(shè)備每秒讀寫(xiě)的數(shù)據(jù)塊數(shù)量。塊的大小可以不同,如1024, 2048 或 4048字節(jié),這取決于partition的大小。
例如,執(zhí)行下列命令獲得設(shè)備/dev/sda1 的數(shù)據(jù)塊大小:
dumpe2fs -h /dev/sda1 |grep -F "Block size"
輸出結(jié)果如下
dumpe2fs 1.34 (25-Jul-2003)
Block size: 1024
Blk_read, Blk_wrtn: 指示自從系統(tǒng)啟動(dòng)之后數(shù)據(jù)塊讀/寫(xiě)的合計(jì)數(shù)。
#p#
5、vmstat
vmstat提供了processes, memory, paging, block I/O, traps和CPU的活動(dòng)狀況.
下邊是vmstat的輸出樣式
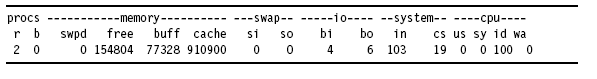
各輸出列的含義:
Process
– r: 等待runtime的進(jìn)程數(shù)
– b: 在不可打斷的休眠狀態(tài)下的進(jìn)程數(shù)
Memory
– swpd: 虛擬內(nèi)存使用量(KB)
– free: 閑置內(nèi)存使用量(KB)
– buff: 被當(dāng)做buffer使用的內(nèi)存量(KB)
Swap
– si: swap到磁盤(pán)的內(nèi)存量(KBps)
– so: 從磁盤(pán)swap出去的內(nèi)存量(KBps)
IO
– bi: Blocks sent to a block device (blocks/s).
– bo: Blocks received from a block device (blocks/s).
System
– in: The number of interrupts per second, including the clock.
– cs: The number of context switches per second.
CPU (these are percentages of total CPU time)
- us: Time spent running non-kernel code (user time, including nice time).
– sy: Time spent running kernel code (system time).
– id: Time spent idle. Prior to Linux 2.5.41, this included IO-wait time.
– wa: Time spent waiting for IO. Prior to Linux 2.5.41, this appeared as zero.
6 sar
sar是Red Hat Enterprise Linux AS發(fā)行的一個(gè)工具,同時(shí)也是Sysstat工具集的命令之一,可以從以下網(wǎng)址下載:http://perso.wanadoo.fr/sebastien.godard/
sar用于收集、報(bào)告或者保存系統(tǒng)活動(dòng)信息。sar由三個(gè)應(yīng)用組成:sar顯示數(shù)據(jù)、sar1和sar2用于收集和保存數(shù)據(jù)。
使用sar1和sar2,系統(tǒng)能夠配置成自動(dòng)抓取信息和日志,以備分析使用。配置舉例:在/etc/crontab中添加如下幾行內(nèi)容

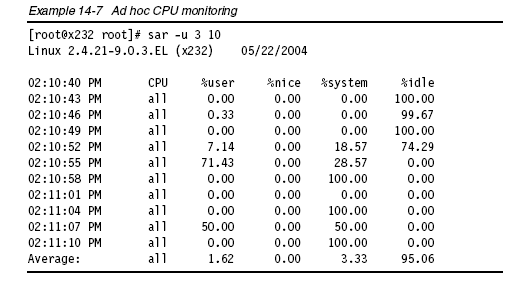
同樣的,你也可以在命令行方式下使用sar運(yùn)行實(shí)時(shí)報(bào)告。如圖所示:
從收集的信息中,可以得到詳細(xì)的CPU使用情況(%user, %nice, %system, %idle)、內(nèi)存頁(yè)面調(diào)度、網(wǎng)絡(luò)I/O、進(jìn)程活動(dòng)、塊設(shè)備活動(dòng)、以及interrupts/second
#p#
7 KDE System Guard
KDE System Guard (KSysguard) 指KDE任務(wù)管理和性能監(jiān)視。監(jiān)視本地及遠(yuǎn)程客戶(hù)端/服務(wù)器架構(gòu)體系的中的主機(jī)。
如圖14-1
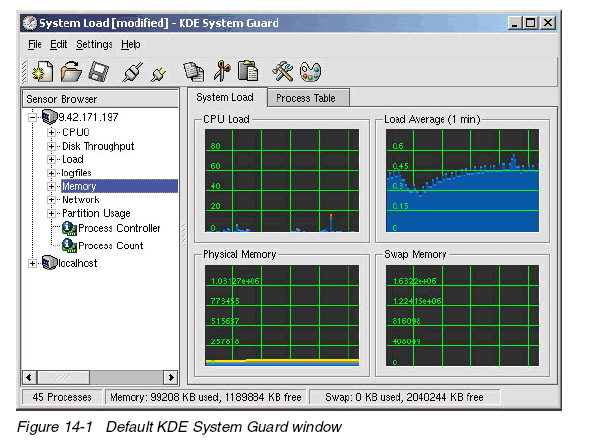
如圖所示,使用傳感器獲取顯示的信息。傳感器可以返回簡(jiǎn)單的數(shù)值或者復(fù)雜的表格信息。
對(duì)于每一種類(lèi)型的信息,提供了一個(gè)或者更多顯示。并以工作表的形式獨(dú)立保存。
每個(gè)傳感器監(jiān)視一個(gè)部件。所有顯示的傳感器均可以用鼠標(biāo)拖拽。有三個(gè)選擇
1可以刪除和替換某個(gè)傳感器
2可以編輯修改行數(shù)和列數(shù)
3可以建立新的工作表并選擇所需的傳感器
如圖14-2
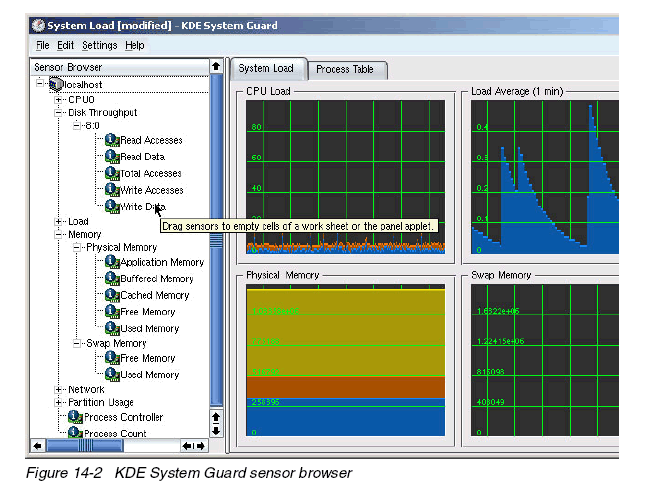
7.1 Work space
如圖14-2所示,有兩個(gè)tabs:System Load和Process Table
System Load
該工作表中有四個(gè)傳感器視窗:CPU Load, Load Average (1 Minute), Physical Memory, 和 Swap Memory.
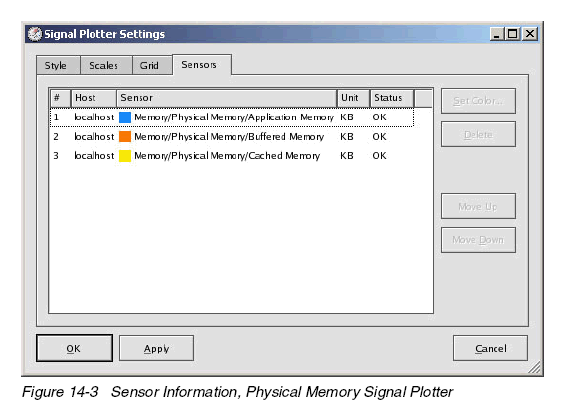
從Physical Memory window可以看到,同一個(gè)window中可以顯示多個(gè)傳感器。在圖上移動(dòng)鼠標(biāo),根據(jù)所出現(xiàn)的描述信息可以知道哪個(gè)傳感器正被監(jiān)視。也可以點(diǎn)鼠標(biāo)右鍵該圖并選擇Properties--Sensors,如圖14-3所示。
Process Table
圖14-4
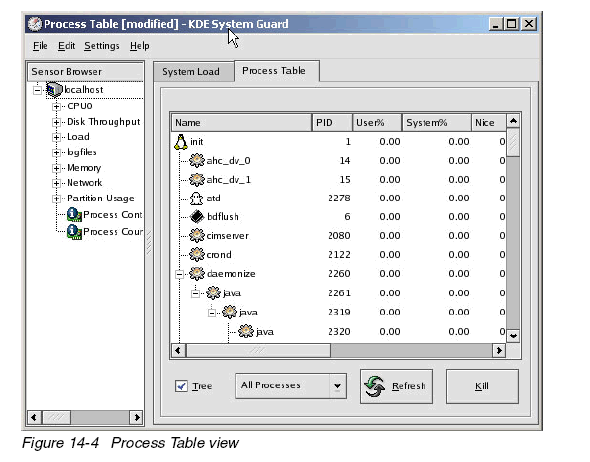
點(diǎn)擊Process Table顯示所有執(zhí)行的進(jìn)程。缺省情況下,按照System CPU utilization排序,也可以簡(jiǎn)單地通過(guò)鼠標(biāo)點(diǎn)擊相應(yīng)項(xiàng)改變排序的方式。
定制一個(gè)work sheet
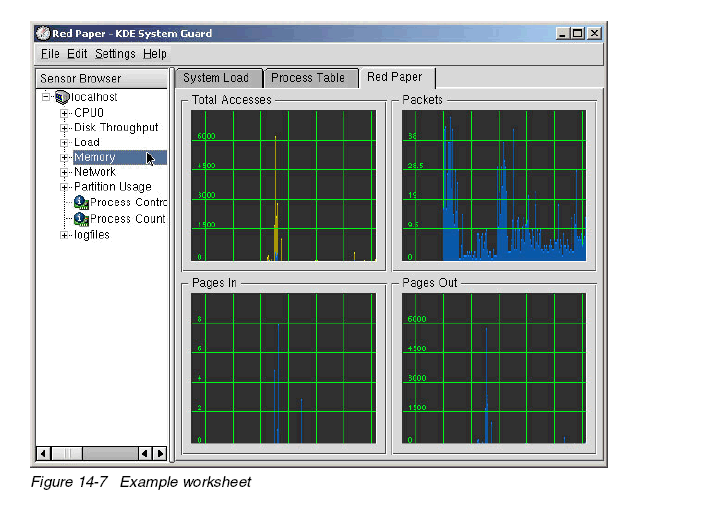
指導(dǎo)定制創(chuàng)建一個(gè)如圖14-7所示的work sheet
1. 選擇File-> New ,如圖 14-5
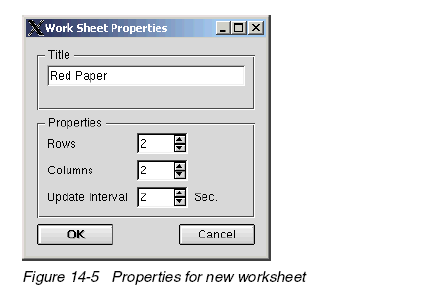
2. 輸入標(biāo)題以及行列數(shù);即最多的監(jiān)視窗口數(shù),這里為四個(gè)。如圖14-6
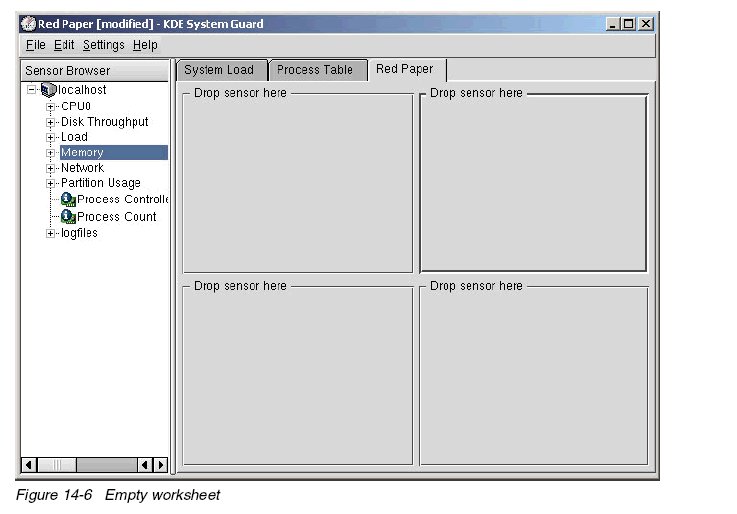
注:最短2秒更新間隔
3. 現(xiàn)在只需簡(jiǎn)單將傳感器從左惻拖拽到右惻的窗口中。顯示可選項(xiàng)為
– Signal Plotter. 顯示一個(gè)或者多個(gè)傳感器,如果有多個(gè),則分層顯示。如果顯示屏足夠大,以網(wǎng)格方式顯示。
缺省情況下,為自動(dòng)排列方式,***和最小值自動(dòng)設(shè)置。如果要修改***最小值,首先要關(guān)閉自動(dòng)排列方式。
– Multimeter. 以數(shù)字方式顯示傳感器的值。在屬性對(duì)話(huà)框中,可以改變上限和下限。超過(guò)限制時(shí),顯示警告色。
– BarGraph. 將傳感器的值顯示為dancing bars. 同Multimeter一樣,在屬性對(duì)話(huà)框中,可以改變上限和下限。超過(guò)限制時(shí),顯示警告色。
– Sensor Logger :Sensor Logger不顯示任何值,而是將上述信息記錄到某個(gè)文件中, 并加入日期和時(shí)間。對(duì)每個(gè)傳感器,你必須定義一個(gè)日志文件、記錄日志的時(shí)間間隔、以及是否報(bào)警。
4.點(diǎn)File -> Save,保存worksheet.
如需獲取更多KDE System Guard信息,訪(fǎng)問(wèn):http://docs.kde.org/en/3.2/kdebase/ksysgaurd
注:work sheet被保存在用戶(hù)目錄中,其他管理員可能無(wú)法訪(fǎng)問(wèn)。
#p#
8 free
/bin/free命令顯示所有空閑的和使用的內(nèi)存數(shù)量,包括swap。同時(shí)也包含內(nèi)核使用的緩存。

9 Traffic-vis
Traffic-vis是一套測(cè)定哪些主機(jī)在IP網(wǎng)進(jìn)行通信、通信的目標(biāo)主機(jī)以及傳輸?shù)臄?shù)據(jù)量。并輸出純文本、HTML或者GIF格式的報(bào)告。
注:Traffic-vis僅僅適用于SUSE LINUX ENTERPRISE SERVER。
如下命令用來(lái)收集網(wǎng)口eth0的信息:
traffic-collector -i eth0 -s /root/output_traffic-collector
可以使用killall命令來(lái)控制該進(jìn)程。如果要將報(bào)告寫(xiě)入磁盤(pán),可使用如下命令:
killall -SIGUSR1 traffic-collector
要停止對(duì)信息的收集,執(zhí)行如下命令:killall -SIGTERM traffic-collector
注意,不要忘記執(zhí)行***一條命令,否則會(huì)因?yàn)閮?nèi)存占用而影響性能。
可以根據(jù)packets, bytes, TCP連接數(shù)對(duì)輸出進(jìn)行排序,根據(jù)每項(xiàng)的總數(shù)或者收/發(fā)的數(shù)量進(jìn)行。
例如根據(jù)主機(jī)上packets的收/發(fā)數(shù)量排序,執(zhí)行命令:
traffic-sort -i output_traffic-collector -o output_traffic-sort -Hp
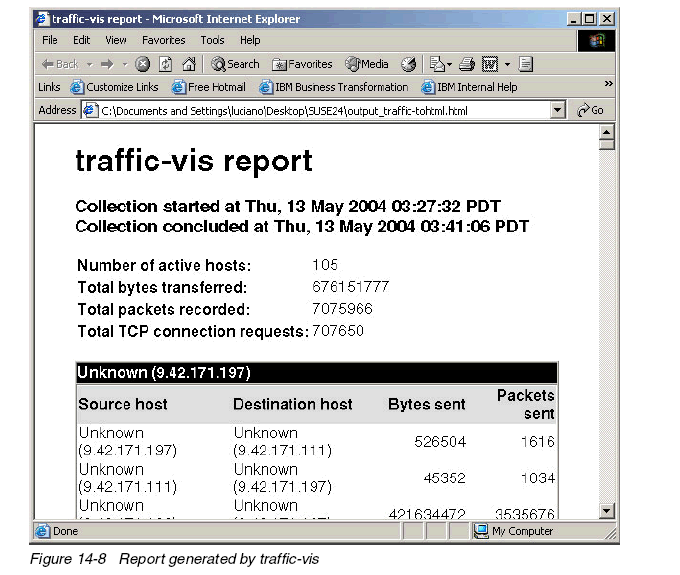
如要生成HTML格式的報(bào)告,顯示傳輸?shù)淖止?jié)數(shù),packets的記錄、全部TCP連接請(qǐng)求和網(wǎng)絡(luò)中每臺(tái)服務(wù)器的信息,請(qǐng)運(yùn)行命令:
traffic-tohtml -i output_traffic-sort -o output_traffic-tohtml.html
可以通過(guò)瀏覽器方式查看報(bào)告的內(nèi)容,如圖14-8
如要生成GIF格式(600X600)的報(bào)告,請(qǐng)運(yùn)行命令:
traffic-togif -i output_traffic-sort -o output_traffic-togif.gif -x 600 -y 600
圖14-9顯示了網(wǎng)絡(luò)中主機(jī)之間通信的情況。GIF格式的報(bào)告可以方便地發(fā)現(xiàn)網(wǎng)絡(luò)廣播,查看哪臺(tái)主機(jī)在TCP網(wǎng)絡(luò)中使用IPX/SPX協(xié)議并隔離網(wǎng)絡(luò),需要記住的是,IPX是基于廣播包的協(xié)議。如果我們需要查明例如網(wǎng)卡故障或重復(fù)IP的問(wèn)題,需要使用特殊的工具。例如SUSE LINUXEnterprise Server自帶的Ethereal。

技巧和提示:使用管道,可以只需執(zhí)行一條命令來(lái)產(chǎn)生報(bào)告。如生成HTML的報(bào)告,執(zhí)行命令:
cat output_traffic-collector | traffic-sort -Hp | traffic-tohtml
-o output_traffic-tohtml.html
如要生成GIF文件,執(zhí)行命令:
cat output_traffic-collector | traffic-sort -Hp | traffic-togif
-o output_traffic-togif.gif -x 600 -y 600
10 pmap
pmap可以報(bào)告某個(gè)或多個(gè)進(jìn)程的內(nèi)存使用情況。使用pmap判斷主機(jī)中哪個(gè)進(jìn)程因占用過(guò)多內(nèi)存導(dǎo)致內(nèi)存瓶頸。圖14-9顯示了SUSE LINUX
Enterprise Server下pmap命令執(zhí)行結(jié)果
pmap -x <pid>
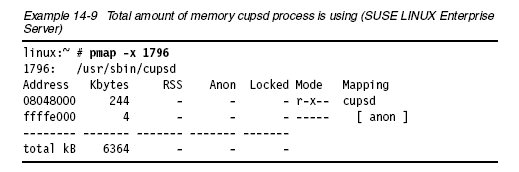
圖14-10顯示了smbd進(jìn)程所占用的內(nèi)存
pmap <pid>

#p#
11 strace
strace截取和記錄系統(tǒng)進(jìn)程調(diào)用,以及進(jìn)程收到的信號(hào)。是一個(gè)非常有效的檢測(cè)、指導(dǎo)和調(diào)試工具。系統(tǒng)管理員可以通過(guò)該命令容易地解決程序問(wèn)題。
使用該命令需要指明進(jìn)程的ID(PID),例如:
strace -p <pid>
圖14-11 shows an example of the output of strace.

12 ulimit
ulimit內(nèi)置在bash shell中,用來(lái)提供對(duì)shell和進(jìn)程可用資源的控制
使用選項(xiàng)-a列出可以設(shè)置的所有參數(shù):
ulimit -a

-H和-S選項(xiàng)指明所給資源的軟硬限制。如果超過(guò)了軟限制,系統(tǒng)管理員會(huì)收到警告信息。硬限制指在用戶(hù)收到超過(guò)文件句炳限制的錯(cuò)誤信息之前,可以達(dá)到的***值。
例如可以設(shè)置對(duì)文件句炳的硬限制:ulimit -Hn 4096
例如可以設(shè)置對(duì)文件句炳的軟限制:ulimit -Sn 1024
查看軟硬值,執(zhí)行如下命令:
ulimit -Hn
ulimit -Sn
例如限制Oracle用戶(hù). 在/etc/security/limits.conf輸入以下行:
soft nofile 4096
hard nofile 10240
對(duì)于Red Hat Enterprise Linux AS,確定文件/etc/pam.d/system-auth包含如下行
session required /lib/security/$ISA/pam_limits.so
對(duì)于SUSE LINUX Enterprise Server,確定文件/etc/pam.d/login 和/etc/pam.d/sshd包含如下行:
session required pam_limits.so
這一行使這些限制生效。
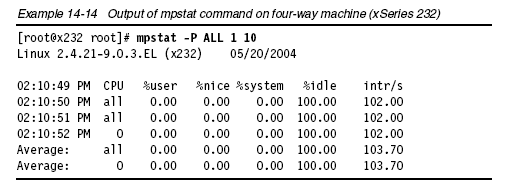
13 mpstat
mpstat是Sysstat工具集的一部分,下載地址是http://perso.wanadoo.fr/sebastien.godard/
mpstat用于報(bào)告多路CPU主機(jī)的每顆CPU活動(dòng)情況,以及整個(gè)主機(jī)的CPU情況。
例如,下邊的命令可以隔2秒報(bào)告一次處理器的活動(dòng)情況,執(zhí)行3次
mpstat 2 3

如下命令每隔1秒顯示一次多路CPU主機(jī)的處理器活動(dòng)情況,執(zhí)行3次
mpstat -P ALL 1 3
【編輯推薦】