













Oracle數(shù)據(jù)庫性能模型
最近一直在思考一個(gè)問題:如何為一個(gè)數(shù)據(jù)庫建立性能模型?作為一名DBA來說,我們面臨的一個(gè)巨大挑戰(zhàn)是:如何保證數(shù)據(jù)庫的性能可以滿足快速變化的應(yīng)用的需求,如何在數(shù)據(jù)量和訪問量持續(xù)增長的情況下,保證應(yīng)用的響應(yīng)時(shí)間和數(shù)據(jù)庫的負(fù)載處在合理的水平下。我們可能會(huì)經(jīng)常面對以下的問題:某個(gè)SQL每秒要執(zhí)行100次,響應(yīng)時(shí)間是多少?某個(gè)應(yīng)用發(fā)布后,對數(shù)據(jù)庫的影響如何?所以,評估應(yīng)用對數(shù)據(jù)庫所產(chǎn)生的影響,優(yōu)化應(yīng)用并預(yù)測風(fēng)險(xiǎn),保證數(shù)據(jù)庫的可用性和穩(wěn)定性,這是應(yīng)用DBA真正有價(jià)值的地方。
響應(yīng)時(shí)間為中心:
如果要選擇一個(gè)評價(jià)系統(tǒng)優(yōu)劣的性能指標(biāo),毫無疑問應(yīng)該是響應(yīng)時(shí)間。響應(yīng)時(shí)間是客戶體驗(yàn)的***要素,所有的優(yōu)化都應(yīng)該為降低響應(yīng)時(shí)間而努力。對于數(shù)據(jù)庫系統(tǒng)也是如此,我們優(yōu)化系統(tǒng),優(yōu)化SQL,最終目標(biāo)都是為了降低響應(yīng)時(shí)間,單位時(shí)間內(nèi)可以處理更多的請求。
數(shù)據(jù)庫時(shí)間模型:
響應(yīng)時(shí)間一般分為服務(wù)時(shí)間(Service time)和等待時(shí)間(Wait time),服務(wù)時(shí)間指進(jìn)程占用CPU的時(shí)間,包括前臺(tái)進(jìn)程(Server process)和后臺(tái)進(jìn)程(Backgroud process),我們一般只關(guān)注前臺(tái)進(jìn)程占用的CPU time。等待時(shí)間包括很多類型,一般最常見的是IO等待和并發(fā)等待,IO等待包括sequential read,scattered read和log file sync等等,而并發(fā)等待主要是latch和enqueue。SQL execute elapsed time指用戶進(jìn)程執(zhí)行SQL的響應(yīng)時(shí)間,包含CPU time和wait time。
以下是Oracle數(shù)據(jù)庫的時(shí)間模型:

在Oracle系統(tǒng)中,我們可以利用AWR或Statspack報(bào)告,看到數(shù)據(jù)庫的時(shí)間信息:
| Statistic Name | Time (s) | % of DB Time |
|---|---|---|
| sql execute elapsed time | 3,062.17 | 91.52 |
| DB CPU | 2,842.08 | 84.95 |
| parse time elapsed | 25.87 | 0.77 |
| PL/SQL execution elapsed time | 11.75 | 0.35 |
| sequence load elapsed time | 7.55 | 0.23 |
| hard parse elapsed time | 5.06 | 0.15 |
| connection management call elapsed time | 3.13 | 0.09 |
| hard parse (sharing criteria) elapsed time | 0.04 | 0.00 |
| repeated bind elapsed time | 0.01 | 0.00 |
| PL/SQL compilation elapsed time | 0.00 | 0.00 |
| DB time | 3,345.74 | |
| background elapsed time | 204.91 | |
| background cpu time | 72.30 |
DB time是整個(gè)數(shù)據(jù)庫用戶進(jìn)程消耗的總時(shí)間,是從***項(xiàng)到第十項(xiàng)時(shí)間的總和(從sql execute elapsed time到PL/SQL compilation elapsed time),但是我們會(huì)發(fā)現(xiàn)這十項(xiàng)時(shí)間的總和比DB Time要大一些,這是因?yàn)椴糠謺r(shí)間信息有重疊的部分,比如SQL execute elapsed time就包括了很大一部分DB cpu的時(shí)間。而background elapsed time和background cpu time則是Oracle后臺(tái)進(jìn)程消耗的時(shí)間和cpu time。
數(shù)據(jù)庫響應(yīng)時(shí)間分析:
數(shù)據(jù)庫系統(tǒng)的響應(yīng)時(shí)間由四個(gè)要素決定:CPU,IO,內(nèi)存和網(wǎng)絡(luò),其中CPU和IO是最重要的因素。與之相比,內(nèi)存與網(wǎng)絡(luò)則簡單很多,因?yàn)橥ǔG闆r下,對于一個(gè)調(diào)優(yōu)的系統(tǒng)來說,內(nèi)存訪問的延遲時(shí)間非常小(100 ns以下,1 ms=1000000 ns)相比較CPU和IO幾乎可以忽略。而網(wǎng)絡(luò)延遲則通常是一個(gè)常數(shù),比如在一個(gè)數(shù)據(jù)中心的情況下,網(wǎng)絡(luò)的延遲一般在3ms以下,如果存在多數(shù)據(jù)中心的情況,網(wǎng)絡(luò)延遲可能會(huì)超過20ms,所以對于一個(gè)分布式系統(tǒng)來說,網(wǎng)絡(luò)延遲是必須要考慮的問題。
在這里,我們不考慮分布式系統(tǒng),并且忽略內(nèi)存的訪問延遲,重點(diǎn)分析CPU和IO,我們看以下數(shù)據(jù)庫的AWR片段:
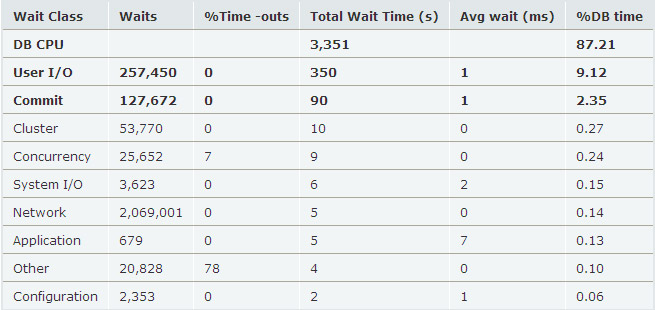
我們看到這個(gè)系統(tǒng)中DB CPU占整個(gè)DB time的87.21%,User I/O占整個(gè)DB time的9.12%,commit相關(guān)的IO等待占2.35%(主要是log file sync),CPU和IO占用了整個(gè)DB time的96.68%。由于DB CPU所占的比例很高,所以這個(gè)數(shù)據(jù)庫系統(tǒng)是CPU intensive類型,這里的DB CPU主要是執(zhí)行SQL的服務(wù)時(shí)間。
我們再看另外的一個(gè)數(shù)據(jù)庫的AWR片段:
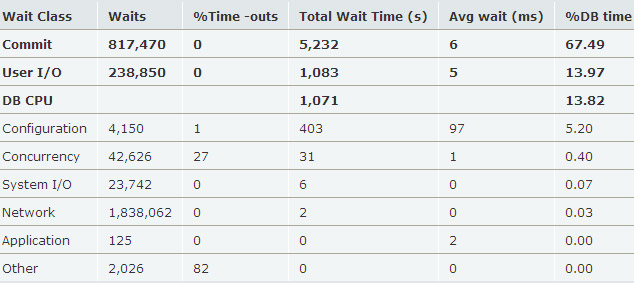
我們看到,Commit和User I/O占DB time的81.46%,而DB CPU只占13.82%,所以這個(gè)數(shù)據(jù)庫系統(tǒng)是IO instensive類型的。
Physical read
Physical read是指Oracle在buffer cache中沒有找到相應(yīng)的block,需要從IO子系統(tǒng)讀取相應(yīng)的block的過程,對應(yīng)的IO稱為物理IO,物理讀數(shù)量代表物理IO讀取的block數(shù)量。因?yàn)橐话鉏O子系統(tǒng)都是慢速的磁盤,所以物理IO對整體響應(yīng)時(shí)間的影響非常大,如果發(fā)生大量的物理IO,整個(gè)系統(tǒng)的響應(yīng)時(shí)間會(huì)變得很差。系統(tǒng)的IO子系統(tǒng)可能是文件系統(tǒng),裸設(shè)備或者ASM,底層硬件可能是SAN存儲(chǔ),NAS存儲(chǔ)或者普通SAS磁盤等等。為了提高響應(yīng)時(shí)間,通常在物理磁盤與Oracle之間增加cache層,對于Oracle來說,物理IO并不一定是真正訪問磁盤,很可能是訪問文件系統(tǒng)cache,存儲(chǔ)的cache等等。
不管IO subsystem是什么,Oracle只關(guān)心物理IO的響應(yīng)時(shí)間。通過AWR報(bào)告,我們可以看到物理IO的響應(yīng)時(shí)間:
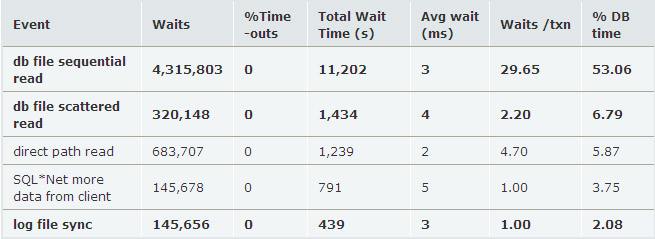
db file sequential read(單塊讀,隨機(jī)IO)的平均響應(yīng)時(shí)間為3ms,db file scattered read(多塊讀,連續(xù)IO)的平均響應(yīng)時(shí)間是4ms,logfile file sync的平均響應(yīng)時(shí)間是3ms,前兩者的Wait class是User I/O,代表用戶進(jìn)程讀操作的響應(yīng)時(shí)間,logfile sync的wait class是Commit,代表lgwr進(jìn)程寫redo的響應(yīng)時(shí)間,因?yàn)橛脩鬰ommit必須完成log file sync的操作,所以它也會(huì)直接影響用戶進(jìn)程寫操作的響應(yīng)時(shí)間。
關(guān)于物理IO的響應(yīng)時(shí)間,我們有一個(gè)經(jīng)驗(yàn)值。對于Sequential read和Scattered read,我們認(rèn)為小于10ms屬于正常狀態(tài),而大于10ms則認(rèn)為IO subsystem的響應(yīng)延遲過大。所以我們在衡量存儲(chǔ)系統(tǒng)的性能時(shí),只有響應(yīng)時(shí)間在10ms以下的IO我們認(rèn)為是有效的。這里有一個(gè)有趣的現(xiàn)象,就是sequential read和scattered read的響應(yīng)時(shí)間幾乎相差無幾,也就是說隨機(jī)IO讀取8K數(shù)據(jù)和連續(xù)IO讀取128K數(shù)據(jù),響應(yīng)時(shí)間差別很小,這是由磁盤的機(jī)械特性造成的,延遲時(shí)間=尋道時(shí)間+
對于log file sync的響應(yīng)時(shí)間,因?yàn)橛脩鬰ommit必須完成log file sync,所以整個(gè)系統(tǒng)的寫操作的響應(yīng)時(shí)間都取決于它的響應(yīng)時(shí)間,而且從整個(gè)數(shù)據(jù)庫系統(tǒng)的角度去看,log file sync幾乎是串行的,所以這個(gè)響應(yīng)時(shí)間對寫操作影響非常大,我們的經(jīng)驗(yàn)值是必須保證在5ms以下,如果超過5ms整個(gè)系統(tǒng)的寫操作都會(huì)受到嚴(yán)重的影響。
Logical read
Logical read是Oracle從buffer cache中讀取block的過程,對應(yīng)的IO稱為邏輯IO,邏輯讀數(shù)量代表邏輯IO讀取的block數(shù)量。因?yàn)镺racle必須首先將block讀入buffer cache中(direct path read除外),所以邏輯讀數(shù)量包含了物理讀數(shù)量。對于一個(gè)SQL來說,邏輯讀數(shù)量是衡量其性能的標(biāo)準(zhǔn),而不是物理讀。雖然物理IO的響應(yīng)延遲比邏輯IO大很多,但是物理讀數(shù)量會(huì)隨著執(zhí)行次數(shù)而變化(頻繁讀取導(dǎo)致block被緩存在buffer cache中)。對于一個(gè)系統(tǒng)也是如此,邏輯讀應(yīng)該是數(shù)據(jù)庫性能評估模型的核心,我們需要建立邏輯讀與響應(yīng)時(shí)間的對應(yīng)關(guān)系。
每個(gè)邏輯讀的響應(yīng)時(shí)間是多少,這是一個(gè)巨大的挑戰(zhàn)。因?yàn)槊總€(gè)邏輯讀背后隱藏了很多動(dòng)作,可能包括物理讀,等待事件,CPU time等等。我對很多數(shù)據(jù)庫的AWR報(bào)告做了分析,期望根據(jù)經(jīng)驗(yàn)值建立一個(gè)簡化的模型。我們假設(shè)一個(gè)數(shù)據(jù)庫如果是充分調(diào)優(yōu)的,除CPU time和IO以外的等待時(shí)間應(yīng)該盡可能少(應(yīng)小于DB time 10%)。在這個(gè)前提下,我們只關(guān)心CPU time和IO的影響,并將系統(tǒng)分為三類:CPU密集型,IO密集型和混合型:
1.IO密集型
User IO 85%
DB CPU 5%
每邏輯讀響應(yīng)時(shí)間0.1-0.5ms
2.CPU密集型
DB CPU 85%
User IO 10%
每邏輯讀響應(yīng)時(shí)間小于0.01ms
3.混合型
User I/O 60%
DB CPU 20%
每邏輯讀響應(yīng)時(shí)間0.05-0.1ms
以上數(shù)據(jù)是根據(jù)很多個(gè)典型數(shù)據(jù)庫的AWR報(bào)告計(jì)算出來的經(jīng)驗(yàn)值,計(jì)算公式很簡單:DB time/邏輯讀=每邏輯讀響應(yīng)時(shí)間。因?yàn)椴]有考慮硬件和OS上的差異,所以這個(gè)數(shù)值并不是特別準(zhǔn)確,但我們還是可以發(fā)現(xiàn)一些規(guī)律:隨著IO所占比例從10%增加到85%,響應(yīng)時(shí)間也從小于0.01ms到0.5ms。
預(yù)測系統(tǒng)瓶頸
對于數(shù)據(jù)庫來說,IO子系統(tǒng)對性能影響非常大,必須保證在一定的IO的壓力下,響應(yīng)延遲控制在合理的范圍內(nèi)(前面說的10ms和5ms)。因?yàn)槊繅K磁盤可以承受的IOPS是基本確定的,比如15K的SAS磁盤,在響應(yīng)延遲不超過10ms的前提下,可以提供150個(gè)IOPS,如果不考慮cache的影響,整個(gè)存儲(chǔ)子系統(tǒng)的IOPS是比較容易計(jì)算的。我們可以在系統(tǒng)上線前,進(jìn)行大量充分的測試,建立存儲(chǔ)IOPS與響應(yīng)延遲的模型,這樣我們就可以預(yù)測出性能出現(xiàn)拐點(diǎn)的風(fēng)險(xiǎn),提前做出擴(kuò)容的判斷。在AWR報(bào)告中,我們可以得到每秒的物理IO的數(shù)量和響應(yīng)時(shí)間,可以方便的實(shí)現(xiàn)性能監(jiān)控和趨勢預(yù)警。
評估CPU的容量瓶頸相對簡單,Oracle中CPU time的計(jì)算是每個(gè)CPU耗費(fèi)時(shí)間的總和,如果有16顆(核)CPU,1個(gè)小時(shí)理論上可以提供3600×16=57600s CPU time,不超過57600s CPU time我們可以認(rèn)為不會(huì)在CPU上排隊(duì),系統(tǒng)不會(huì)出現(xiàn)CPU瓶頸。但是需要注意的是,除了用戶進(jìn)程使用CPU以外,操作系統(tǒng)也需要占用CPU資源,用來管理內(nèi)存和進(jìn)程調(diào)度等。我們在OS上看到的CPU使用率中的sys部分就是系統(tǒng)占用的CPU資源,所以應(yīng)該考慮至少保留10-20%的CPU資源給OS使用。
并發(fā)訪問對數(shù)據(jù)庫的影響
Oracle是一個(gè)Disk-based database,設(shè)計(jì)的出發(fā)點(diǎn)就是大部分?jǐn)?shù)據(jù)在外部存儲(chǔ)中,而只有小部分?jǐn)?shù)據(jù)被cache在buffer中,它既不同于Memcache這類KV cache,也不同于timesten這類In-memory database。所以,就算是所有的數(shù)據(jù)都可以被cache在buffer中,在高并發(fā)訪問的情況下,也可能會(huì)出現(xiàn)大量的latch等待,最常見的情況就是cache buffer chain。當(dāng)大量并發(fā)訪問同一塊數(shù)據(jù)時(shí),就很可能會(huì)出現(xiàn)cache buffer chain的latch爭用,也就是我們常說的“熱點(diǎn)”。
需要注意的是:Oracle中的latch等待分為spin和sleep兩個(gè)部分,spin消耗cpu time,而sleep則是等待時(shí)間。所以大量的latch等待不僅僅會(huì)產(chǎn)生大量的等待時(shí)間,而且會(huì)消耗大量的CPU time。
Oracle是一個(gè)為并發(fā)操作而設(shè)計(jì)的數(shù)據(jù)庫,大量的并發(fā)讀寫請求,可能會(huì)帶來額外的性能消耗。比如讀取一部分頻繁修改的數(shù)據(jù),Oracle為了保證一致性讀的需要,會(huì)利用undo信息構(gòu)造產(chǎn)生大量CR block,同時(shí)會(huì)產(chǎn)生大量的邏輯讀,這樣會(huì)消耗額外的CPU和響應(yīng)時(shí)間。
存儲(chǔ)也可能存在熱點(diǎn)的問題,需要前期對存儲(chǔ)系統(tǒng)充分的優(yōu)化,常見的手段是利用RAID技術(shù),將數(shù)據(jù)分散在不同的磁盤上,防止出現(xiàn)“熱點(diǎn)”盤。Oracle ASM提供了Rebalance的功能,允許DBA將存儲(chǔ)中的的數(shù)據(jù)重新分布,達(dá)到消除熱點(diǎn)的目的。
總之,Oracle是一個(gè)可以提供大量并發(fā)讀寫訪問的數(shù)據(jù)庫系統(tǒng),但是在很多地方,Oracle又不得采用一些串行的控制手段,比如latch,enqueue和mutex,我們要做的就是盡量降低這些串行控制對數(shù)據(jù)庫整體性能的影響。
數(shù)據(jù)庫優(yōu)化原則
基于響應(yīng)時(shí)間的Oracle優(yōu)化原則:盡量減少等待時(shí)間(Wait time),提高服務(wù)時(shí)間(Service time)。這也是基于Oracle等待事件的分析方法的基本原則:盡量消除各種等待事件對系統(tǒng)的影響,從而提高系統(tǒng)性能和響應(yīng)時(shí)間。
如果數(shù)據(jù)庫系統(tǒng)除了CPU和IO以外的等待時(shí)間超過DB time的5%以上的話,可能存在某些性能問題,需要DBA采用等待事件的分析方法,對系統(tǒng)或應(yīng)用進(jìn)行優(yōu)化。
–EOF–
后記:為什么要寫這么一個(gè)主題,因?yàn)樽罱鸵晃煌绿接憴C(jī)器自動(dòng)審核SQL的問題,就想建立一個(gè)簡單的模型,用來開發(fā)一個(gè)SQL審核工具,開發(fā)人員通過工具和預(yù)先建立好的模型,就可以確定這個(gè)SQL是否存在性能風(fēng)險(xiǎn)。之前我們在做SQL優(yōu)化的時(shí)候,只是關(guān)注這個(gè)SQL本身是否優(yōu)化,邏輯讀是多少。但是,很少有人把邏輯讀和響應(yīng)時(shí)間之間的關(guān)系建立起來,我試圖想回答這個(gè)問題。
關(guān)于容量規(guī)劃和風(fēng)險(xiǎn)預(yù)測其實(shí)是一個(gè)很有意義的命題,但是我們很多時(shí)候都局限在一些具體的技術(shù)細(xì)節(jié)中,而忽略了對整個(gè)系統(tǒng)容量的把握,事實(shí)上,這也是非常難的一件事。也許到目前為止,我根本沒有達(dá)到建立“模型”的程度,但是我試圖將這些方方面面的因素聯(lián)系起來,提供一些有用的經(jīng)驗(yàn)值給大家,我覺得這個(gè)挺有意義。
在這篇文章中,我提到了幾個(gè)有意義的經(jīng)驗(yàn)值,這是我根據(jù)很多數(shù)據(jù)庫AWR中的信息計(jì)算出來的,雖然不保證完全準(zhǔn)確,但是我覺得基本是靠譜的。建議每個(gè)DBA都應(yīng)該從AWR中找到這些信息,并判斷自己的數(shù)據(jù)庫屬于哪種類型,瓶頸在哪里,是否存在性能風(fēng)險(xiǎn)。當(dāng)面對諸如“硬件是否能夠滿足性能需求”,“系統(tǒng)明年是否需要擴(kuò)容”,“應(yīng)用是否會(huì)對系統(tǒng)產(chǎn)生影響”此類問題時(shí),我們可以用這些經(jīng)驗(yàn)值給出一個(gè)判斷。
關(guān)于這個(gè)命題,目前只是一個(gè)階段性的結(jié)果,我還會(huì)繼續(xù)思考。如果大家有興趣,歡迎和我一起探討這個(gè)話題。
本文轉(zhuǎn)載自Hello DBA的博客,原文:Oracle數(shù)據(jù)庫性能模型
【編輯推薦】
- Oracle數(shù)據(jù)庫索引和SQL Server的闡述
- Oracle更改表空間大小的代碼與實(shí)際操作
- Oracle優(yōu)化器的3不同類型介紹
- Oracle優(yōu)化器三大種類的介紹
- Oracle優(yōu)化器二十六個(gè)參數(shù)











