Google GFS文件系統(tǒng)深入分析
51CTO編輯注:本文是一篇論文,英文原文標(biāo)題為T(mén)he Google File System,在Google Labs上公布,由blademaster.ixiezi.com的博主Alex翻譯為中文,Google GFS文件系統(tǒng)。現(xiàn)在云計(jì)算漸成潮流,對(duì)大規(guī)模數(shù)據(jù)應(yīng)用、可伸縮、高容錯(cuò)的分布式文件系統(tǒng)的需求日漸增長(zhǎng)。Google根據(jù)自身的經(jīng)驗(yàn)打造的這套針對(duì)大量廉價(jià)客戶(hù)機(jī)的分布式文件系統(tǒng)已經(jīng)廣泛的在Google內(nèi)部進(jìn)行部署,對(duì)于有類(lèi)似需求的企業(yè)而言有相當(dāng)?shù)膮⒖純r(jià)值。
摘要
我們?cè)O(shè)計(jì)并實(shí)現(xiàn)了Google GFS文件系統(tǒng),一個(gè)面向大規(guī)模數(shù)據(jù)密集型應(yīng)用的、可伸縮的分布式文件系統(tǒng)。GFS雖然運(yùn)行在廉價(jià)的普遍硬件設(shè)備上,但是它依然了提供災(zāi)難冗余的能力,為大量客戶(hù)機(jī)提供了高性能的服務(wù)。
雖然GFS的設(shè)計(jì)目標(biāo)與許多傳統(tǒng)的分布式文件系統(tǒng)有很多相同之處,但是,我們的設(shè)計(jì)還是以我們對(duì)自己的應(yīng)用的負(fù)載情況和技術(shù)環(huán)境的分析為基礎(chǔ)的,不管現(xiàn)在還是將來(lái),GFS和早期的分布式文件系統(tǒng)的設(shè)想都有明顯的不同。所以我們重新審視了傳統(tǒng)文件系統(tǒng)在設(shè)計(jì)上的折衷選擇,衍生出了完全不同的設(shè)計(jì)思路。
GFS完全滿足了我們對(duì)存儲(chǔ)的需求。GFS作為存儲(chǔ)平臺(tái)已經(jīng)被廣泛的部署在Google內(nèi)部,存儲(chǔ)我們的服務(wù)產(chǎn)生和處理的數(shù)據(jù),同時(shí)還用于那些需要大規(guī)模數(shù)據(jù)集的研究和開(kāi)發(fā)工作。目前為止,最大的一個(gè)集群利用數(shù)千臺(tái)機(jī)器的數(shù)千個(gè)硬盤(pán),提供了數(shù)百TB的存儲(chǔ)空間,同時(shí)為數(shù)百個(gè)客戶(hù)機(jī)服務(wù)。
在本論文中,我們展示了能夠支持分布式應(yīng)用的文件系統(tǒng)接口的擴(kuò)展,討論我們?cè)O(shè)計(jì)的許多方面,最后列出了小規(guī)模性能測(cè)試以及真實(shí)生產(chǎn)系統(tǒng)中性能相關(guān)數(shù)據(jù)。
常用術(shù)語(yǔ)
設(shè)計(jì),可靠性,性能,測(cè)量
關(guān)鍵詞
容錯(cuò),可伸縮性,數(shù)據(jù)存儲(chǔ),集群存儲(chǔ)
1. 簡(jiǎn)介
為了滿足Google迅速增長(zhǎng)的數(shù)據(jù)處理需求,我們?cè)O(shè)計(jì)并實(shí)現(xiàn)了Google文件系統(tǒng)(Google File System – GFS)。GFS與傳統(tǒng)的分布式文件系統(tǒng)有著很多相同的設(shè)計(jì)目標(biāo),比如,性能、可伸縮性、可靠性以及可用性。但是,我們的設(shè)計(jì)還基于我們對(duì)我們自己的應(yīng)用的負(fù)載情況和技術(shù)環(huán)境的觀察的影響,不管現(xiàn)在還是將來(lái),GFS和早期文件系統(tǒng)的假設(shè)都有明顯的不同。所以我們重新審視了傳統(tǒng)文件系統(tǒng)在設(shè)計(jì)上的折衷選擇,衍生出了完全不同的設(shè)計(jì)思路。
首先,組件失效被認(rèn)為是常態(tài)事件,而不是意外事件。GFS包括幾百甚至幾千臺(tái)普通的廉價(jià)設(shè)備組裝的存儲(chǔ)機(jī)器,同時(shí)被相當(dāng)數(shù)量的客戶(hù)機(jī)訪問(wèn)。GFS組件的數(shù)量和質(zhì)量導(dǎo)致在事實(shí)上,任何給定時(shí)間內(nèi)都有可能發(fā)生某些組件無(wú)法工作,某些組件無(wú)法從它們目前的失效狀態(tài)中恢復(fù)。我們遇到過(guò)各種各樣的問(wèn)題,比如應(yīng)用程序bug、操作系統(tǒng)的bug、人為失誤,甚至還有硬盤(pán)、內(nèi)存、連接器、網(wǎng)絡(luò)以及電源失效等造成的問(wèn)題。所以,持續(xù)的監(jiān)控、錯(cuò)誤偵測(cè)、災(zāi)難冗余以及自動(dòng)恢復(fù)的機(jī)制必須集成在GFS中。
其次,以通常的標(biāo)準(zhǔn)衡量,我們的文件非常巨大。數(shù)GB的文件非常普遍。每個(gè)文件通常都包含許多應(yīng)用程序?qū)ο螅热鐆eb文檔。當(dāng)我們經(jīng)常需要處理快速增長(zhǎng)的、并且由數(shù)億個(gè)對(duì)象構(gòu)成的、數(shù)以TB的數(shù)據(jù)集時(shí),采用管理數(shù)億個(gè)KB大小的小文件的方式是非常不明智的,盡管有些文件系統(tǒng)支持這樣的管理方式。因此,設(shè)計(jì)的假設(shè)條件和參數(shù),比如I/O操作和Block的尺寸都需要重新考慮。
第三,絕大部分文件的修改是采用在文件尾部追加數(shù)據(jù),而不是覆蓋原有數(shù)據(jù)的方式。對(duì)文件的隨機(jī)寫(xiě)入操作在實(shí)際中幾乎不存在。一旦寫(xiě)完之后,對(duì)文件的操作就只有讀,而且通常是按順序讀。大量的數(shù)據(jù)符合這些特性,比如:數(shù)據(jù)分析程序掃描的超大的數(shù)據(jù)集;正在運(yùn)行的應(yīng)用程序生成的連續(xù)的數(shù)據(jù)流;存檔的數(shù)據(jù);由一臺(tái)機(jī)器生成、另外一臺(tái)機(jī)器處理的中間數(shù)據(jù),這些中間數(shù)據(jù)的處理可能是同時(shí)進(jìn)行的、也可能是后續(xù)才處理的。對(duì)于這種針對(duì)海量文件的訪問(wèn)模式,客戶(hù)端對(duì)數(shù)據(jù)塊緩存是沒(méi)有意義的,數(shù)據(jù)的追加操作是性能優(yōu)化和原子性保證的主要考量因素。
第四,應(yīng)用程序和文件系統(tǒng)API的協(xié)同設(shè)計(jì)提高了整個(gè)系統(tǒng)的靈活性。比如,我們放松了對(duì)GFS一致性模型的要求,這樣就減輕了文件系統(tǒng)對(duì)應(yīng)用程序的苛刻要求,大大簡(jiǎn)化了GFS的設(shè)計(jì)。我們引入了原子性的記錄追加操作,從而保證多個(gè)客戶(hù)端能夠同時(shí)進(jìn)行追加操作,不需要額外的同步操作來(lái)保證數(shù)據(jù)的一致性。本文后面還有對(duì)這些問(wèn)題的細(xì)節(jié)的詳細(xì)討論。
Google已經(jīng)針對(duì)不同的應(yīng)用部署了多套GFS集群。最大的一個(gè)集群擁有超過(guò)1000個(gè)存儲(chǔ)節(jié)點(diǎn),超過(guò)300TB的硬盤(pán)空間,被不同機(jī)器上的數(shù)百個(gè)客戶(hù)端連續(xù)不斷的頻繁訪問(wèn)。
#p#
2.設(shè)計(jì)概述
2.1設(shè)計(jì)預(yù)期
在設(shè)計(jì)滿足我們需求的文件系統(tǒng)時(shí)候,我們的設(shè)計(jì)目標(biāo)既有機(jī)會(huì)、又有挑戰(zhàn)。之前我們已經(jīng)提到了一些需要關(guān)注的關(guān)鍵點(diǎn),這里我們將設(shè)計(jì)的預(yù)期目標(biāo)的細(xì)節(jié)展開(kāi)討論。
◆ 系統(tǒng)由許多廉價(jià)的普通組件組成,組件失效是一種常態(tài)。系統(tǒng)必須持續(xù)監(jiān)控自身的狀態(tài),它必須將組件失效作為一種常態(tài),能夠迅速地偵測(cè)、冗余并恢復(fù)失效的組件。
◆ 系統(tǒng)存儲(chǔ)一定數(shù)量的大文件。我們預(yù)期會(huì)有幾百萬(wàn)文件,文件的大小通常在100MB或者以上。數(shù)個(gè)GB大小的文件也是普遍存在,并且要能夠被有效的管理。系統(tǒng)也必須支持小文件,但是不需要針對(duì)小文件做專(zhuān)門(mén)的優(yōu)化。
◆ 系統(tǒng)的工作負(fù)載主要由兩種讀操作組成:大規(guī)模的流式讀取和小規(guī)模的隨機(jī)讀取。大規(guī)模的流式讀取通常一次讀取數(shù)百KB的數(shù)據(jù),更常見(jiàn)的是一次讀取1MB甚至更多的數(shù)據(jù)。來(lái)自同一個(gè)客戶(hù)機(jī)的連續(xù)操作通常是讀取同一個(gè)文件中連續(xù)的一個(gè)區(qū)域。小規(guī)模的隨機(jī)讀取通常是在文件某個(gè)隨機(jī)的位置讀取幾個(gè)KB數(shù)據(jù)。如果應(yīng)用程序?qū)π阅芊浅jP(guān)注,通常的做法是把小規(guī)模的隨機(jī)讀取操作合并并排序,之后按順序批量讀取,這樣就避免了在文件中前后來(lái)回的移動(dòng)讀取位置。
◆ 系統(tǒng)的工作負(fù)載還包括許多大規(guī)模的、順序的、數(shù)據(jù)追加方式的寫(xiě)操作。一般情況下,每次寫(xiě)入的數(shù)據(jù)的大小和大規(guī)模讀類(lèi)似。數(shù)據(jù)一旦被寫(xiě)入后,文件就很少會(huì)被修改了。系統(tǒng)支持小規(guī)模的隨機(jī)位置寫(xiě)入操作,但是可能效率不彰。
◆ 系統(tǒng)必須高效的、行為定義明確的(alex注:well-defined)實(shí)現(xiàn)多客戶(hù)端并行追加數(shù)據(jù)到同一個(gè)文件里的語(yǔ)意。我們的文件通常被用于”生產(chǎn)者-消費(fèi)者“隊(duì)列,或者其它多路文件合并操作。通常會(huì)有數(shù)百個(gè)生產(chǎn)者,每個(gè)生產(chǎn)者進(jìn)程運(yùn)行在一臺(tái)機(jī)器上,同時(shí)對(duì)一個(gè)文件進(jìn)行追加操作。使用最小的同步開(kāi)銷(xiāo)來(lái)實(shí)現(xiàn)的原子的多路追加數(shù)據(jù)操作是必不可少的。文件可以在稍后讀取,或者是消費(fèi)者在追加的操作的同時(shí)讀取文件。
◆ 高性能的穩(wěn)定網(wǎng)絡(luò)帶寬遠(yuǎn)比低延遲重要。我們的目標(biāo)程序絕大部分要求能夠高速率的、大批量的處理數(shù)據(jù),極少有程序?qū)我坏淖x寫(xiě)操作有嚴(yán)格的響應(yīng)時(shí)間要求。
2.2 接口
GFS提供了一套類(lèi)似傳統(tǒng)文件系統(tǒng)的API接口函數(shù),雖然并不是嚴(yán)格按照POSIX等標(biāo)準(zhǔn)API的形式實(shí)現(xiàn)的。文件以分層目錄的形式組織,用路徑名來(lái)標(biāo)識(shí)。我們支持常用的操作,如創(chuàng)建新文件、刪除文件、打開(kāi)文件、關(guān)閉文件、讀和寫(xiě)文件。
另外,GFS提供了快照和記錄追加操作。快照以很低的成本創(chuàng)建一個(gè)文件或者目錄樹(shù)的拷貝。記錄追加操作允許多個(gè)客戶(hù)端同時(shí)對(duì)一個(gè)文件進(jìn)行數(shù)據(jù)追加操作,同時(shí)保證每個(gè)客戶(hù)端的追加操作都是原子性的。這對(duì)于實(shí)現(xiàn)多路結(jié)果合并,以及”生產(chǎn)者-消費(fèi)者”隊(duì)列非常有用,多個(gè)客戶(hù)端可以在不需要額外的同步鎖定的情況下,同時(shí)對(duì)一個(gè)文件追加數(shù)據(jù)。我們發(fā)現(xiàn)這些類(lèi)型的文件對(duì)于構(gòu)建大型分布應(yīng)用是非常重要的。快照和記錄追加操作將在3.4和3.3節(jié)分別討論。
2.3 架構(gòu)
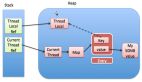
一個(gè)GFS集群包含一個(gè)單獨(dú)的Master節(jié)點(diǎn)(alex注:這里的一個(gè)單獨(dú)的Master節(jié)點(diǎn)的含義是GFS系統(tǒng)中只存在一個(gè)邏輯上的Master組件。后面我們還會(huì)提到Master節(jié)點(diǎn)復(fù)制,因此,為了理解方便,我們把Master節(jié)點(diǎn)視為一個(gè)邏輯上的概念,一個(gè)邏輯的Master節(jié)點(diǎn)包括兩臺(tái)物理主機(jī),即兩臺(tái)Master服務(wù)器)、多臺(tái)Chunk服務(wù)器,并且同時(shí)被多個(gè)客戶(hù)端訪問(wèn),如圖1所示。所有的這些機(jī)器通常都是普通的Linux機(jī)器,運(yùn)行著用戶(hù)級(jí)別(user-level)的服務(wù)進(jìn)程。我們可以很容易的把Chunk服務(wù)器和客戶(hù)端都放在同一臺(tái)機(jī)器上,前提是機(jī)器資源允許,并且我們能夠接受不可靠的應(yīng)用程序代碼帶來(lái)的穩(wěn)定性降低的風(fēng)險(xiǎn)。

GFS存儲(chǔ)的文件都被分割成固定大小的Chunk。在Chunk創(chuàng)建的時(shí)候,Master服務(wù)器會(huì)給每個(gè)Chunk分配一個(gè)不變的、全球唯一的64位的Chunk標(biāo)識(shí)。Chunk服務(wù)器把Chunk以linux文件的形式保存在本地硬盤(pán)上,并且根據(jù)指定的Chunk標(biāo)識(shí)和字節(jié)范圍來(lái)讀寫(xiě)塊數(shù)據(jù)。出于可靠性的考慮,每個(gè)塊都會(huì)復(fù)制到多個(gè)塊服務(wù)器上。缺省情況下,我們使用3個(gè)存儲(chǔ)復(fù)制節(jié)點(diǎn),不過(guò)用戶(hù)可以為不同的文件命名空間設(shè)定不同的復(fù)制級(jí)別。
Master節(jié)點(diǎn)管理所有的文件系統(tǒng)元數(shù)據(jù)。這些元數(shù)據(jù)包括名字空間、訪問(wèn)控制信息、文件和Chunk的映射信息、以及當(dāng)前Chunk的位置信息。Master節(jié)點(diǎn)還管理著系統(tǒng)范圍內(nèi)的活動(dòng),比如,Chunk租用管理(alex注:BDB也有關(guān)于lease的描述,不知道是否相同)、孤兒Chunk(alex注:orphaned chunks)的回收、以及Chunk在Chunk服務(wù)器之間的遷移。Master節(jié)點(diǎn)使用心跳信息周期地和每個(gè)Chunk服務(wù)器通訊,發(fā)送指令到各個(gè)Chunk服務(wù)器并接收Chunk服務(wù)器的狀態(tài)信息。
GFS客戶(hù)端代碼以庫(kù)的形式被鏈接到客戶(hù)程序里。客戶(hù)端代碼實(shí)現(xiàn)了GFS文件系統(tǒng)的API接口函數(shù)、應(yīng)用程序與Master節(jié)點(diǎn)和Chunk服務(wù)器通訊、以及對(duì)數(shù)據(jù)進(jìn)行讀寫(xiě)操作。客戶(hù)端和Master節(jié)點(diǎn)的通信只獲取元數(shù)據(jù),所有的數(shù)據(jù)操作都是由客戶(hù)端直接和Chunk服務(wù)器進(jìn)行交互的。我們不提供POSIX標(biāo)準(zhǔn)的API的功能,因此,GFS API調(diào)用不需要深入到Linux vnode級(jí)別。
無(wú)論是客戶(hù)端還是Chunk服務(wù)器都不需要緩存文件數(shù)據(jù)。客戶(hù)端緩存數(shù)據(jù)幾乎沒(méi)有什么用處,因?yàn)榇蟛糠殖绦蛞匆粤鞯姆绞阶x取一個(gè)巨大文件,要么工作集太大根本無(wú)法被緩存。無(wú)需考慮緩存相關(guān)的問(wèn)題也簡(jiǎn)化了客戶(hù)端和整個(gè)系統(tǒng)的設(shè)計(jì)和實(shí)現(xiàn)。(不過(guò),客戶(hù)端會(huì)緩存元數(shù)據(jù)。)Chunk服務(wù)器不需要緩存文件數(shù)據(jù)的原因是,Chunk以本地文件的方式保存,Linux操作系統(tǒng)的文件系統(tǒng)緩存會(huì)把經(jīng)常訪問(wèn)的數(shù)據(jù)緩存在內(nèi)存中。
2.4 單一Master節(jié)點(diǎn)
單一的Master節(jié)點(diǎn)的策略大大簡(jiǎn)化了我們的設(shè)計(jì)。單一的Master節(jié)點(diǎn)可以通過(guò)全局的信息精確定位Chunk的位置以及進(jìn)行復(fù)制決策。另外,我們必須減少對(duì)Master節(jié)點(diǎn)的讀寫(xiě),避免Master節(jié)點(diǎn)成為系統(tǒng)的瓶頸。客戶(hù)端并不通過(guò)Master節(jié)點(diǎn)讀寫(xiě)文件數(shù)據(jù)。反之,客戶(hù)端向Master節(jié)點(diǎn)詢(xún)問(wèn)它應(yīng)該聯(lián)系的Chunk服務(wù)器。客戶(hù)端將這些元數(shù)據(jù)信息緩存一段時(shí)間,后續(xù)的操作將直接和Chunk服務(wù)器進(jìn)行數(shù)據(jù)讀寫(xiě)操作。
我們利用圖1解釋一下一次簡(jiǎn)單讀取的流程。首先,客戶(hù)端把文件名和程序指定的字節(jié)偏移,根據(jù)固定的Chunk大小,轉(zhuǎn)換成文件的Chunk索引。然后,它把文件名和Chunk索引發(fā)送給Master節(jié)點(diǎn)。Master節(jié)點(diǎn)將相應(yīng)的Chunk標(biāo)識(shí)和副本的位置信息發(fā)還給客戶(hù)端。客戶(hù)端用文件名和Chunk索引作為key緩存這些信息。
之后客戶(hù)端發(fā)送請(qǐng)求到其中的一個(gè)副本處,一般會(huì)選擇最近的。請(qǐng)求信息包含了Chunk的標(biāo)識(shí)和字節(jié)范圍。在對(duì)這個(gè)Chunk的后續(xù)讀取操作中,客戶(hù)端不必再和Master節(jié)點(diǎn)通訊了,除非緩存的元數(shù)據(jù)信息過(guò)期或者文件被重新打開(kāi)。實(shí)際上,客戶(hù)端通常會(huì)在一次請(qǐng)求中查詢(xún)多個(gè)Chunk信息,Master節(jié)點(diǎn)的回應(yīng)也可能包含了緊跟著這些被請(qǐng)求的Chunk后面的Chunk的信息。在實(shí)際應(yīng)用中,這些額外的信息在沒(méi)有任何代價(jià)的情況下,避免了客戶(hù)端和Master節(jié)點(diǎn)未來(lái)可能會(huì)發(fā)生的幾次通訊。
2.5 Chunk尺寸
Chunk的大小是關(guān)鍵的設(shè)計(jì)參數(shù)之一。我們選擇了64MB,這個(gè)尺寸遠(yuǎn)遠(yuǎn)大于一般文件系統(tǒng)的Block size。每個(gè)Chunk的副本都以普通Linux文件的形式保存在Chunk服務(wù)器上,只有在需要的時(shí)候才擴(kuò)大。惰性空間分配策略避免了因內(nèi)部碎片造成的空間浪費(fèi),內(nèi)部碎片或許是對(duì)選擇這么大的Chunk尺寸最具爭(zhēng)議一點(diǎn)。
選擇較大的Chunk尺寸有幾個(gè)重要的優(yōu)點(diǎn)。首先,它減少了客戶(hù)端和Master節(jié)點(diǎn)通訊的需求,因?yàn)橹恍枰淮魏蚆ater節(jié)點(diǎn)的通信就可以獲取Chunk的位置信息,之后就可以對(duì)同一個(gè)Chunk進(jìn)行多次的讀寫(xiě)操作。這種方式對(duì)降低我們的工作負(fù)載來(lái)說(shuō)效果顯著,因?yàn)槲覀兊膽?yīng)用程序通常是連續(xù)讀寫(xiě)大文件。即使是小規(guī)模的隨機(jī)讀取,采用較大的Chunk尺寸也帶來(lái)明顯的好處,客戶(hù)端可以輕松的緩存一個(gè)數(shù)TB的工作數(shù)據(jù)集所有的Chunk位置信息。其次,采用較大的Chunk尺寸,客戶(hù)端能夠?qū)σ粋€(gè)塊進(jìn)行多次操作,這樣就可以通過(guò)與Chunk服務(wù)器保持較長(zhǎng)時(shí)間的
另一方面,即使配合惰性空間分配,采用較大的Chunk尺寸也有其缺陷。小文件包含較少的Chunk,甚至只有一個(gè)Chunk。當(dāng)有許多的客戶(hù)端對(duì)同一個(gè)小文件進(jìn)行多次的訪問(wèn)時(shí),存儲(chǔ)這些Chunk的Chunk服務(wù)器就會(huì)變成熱點(diǎn)。在實(shí)際應(yīng)用中,由于我們的程序通常是連續(xù)的讀取包含多個(gè)Chunk的大文件,熱點(diǎn)還不是主要的問(wèn)題。
然而,當(dāng)我們第一次把GFS用于批處理隊(duì)列系統(tǒng)的時(shí)候,熱點(diǎn)的問(wèn)題還是產(chǎn)生了:一個(gè)可執(zhí)行文件在GFS上保存為single-chunk文件,之后這個(gè)可執(zhí)行文件在數(shù)百臺(tái)機(jī)器上同時(shí)啟動(dòng)。存放這個(gè)可執(zhí)行文件的幾個(gè)Chunk服務(wù)器被數(shù)百個(gè)客戶(hù)端的并發(fā)請(qǐng)求訪問(wèn)導(dǎo)致系統(tǒng)局部過(guò)載。我們通過(guò)使用更大的復(fù)制參數(shù)來(lái)保存可執(zhí)行文件,以及錯(cuò)開(kāi)批處理隊(duì)列系統(tǒng)程序的啟動(dòng)時(shí)間的方法解決了這個(gè)問(wèn)題。一個(gè)可能的長(zhǎng)效解決方案是,在這種的情況下,允許客戶(hù)端從其它客戶(hù)端讀取數(shù)據(jù)。
2.6 元數(shù)據(jù)
Master服務(wù)器(alex注:注意邏輯的Master節(jié)點(diǎn)和物理的Master服務(wù)器的區(qū)別。后續(xù)我們談的是每個(gè)Master服務(wù)器的行為,如存儲(chǔ)、內(nèi)存等等,因此我們將全部使用物理名稱(chēng))存儲(chǔ)3種主要類(lèi)型的元數(shù)據(jù),包括:文件和Chunk的命名空間、文件和Chunk的對(duì)應(yīng)關(guān)系、每個(gè)Chunk副本的存放地點(diǎn)。所有的元數(shù)據(jù)都保存在Master服務(wù)器的內(nèi)存中。前兩種類(lèi)型的元數(shù)據(jù)(命名空間、文件和Chunk的對(duì)應(yīng)關(guān)系)同時(shí)也會(huì)以記錄變更日志的方式記錄在操作系統(tǒng)的系統(tǒng)日志文件中,日志文件存儲(chǔ)在本地磁盤(pán)上,同時(shí)日志會(huì)被復(fù)制到其它的遠(yuǎn)程Master服務(wù)器上。采用保存變更日志的方式,我們能夠簡(jiǎn)單可靠的更新Master服務(wù)器的狀態(tài),并且不用擔(dān)心Master服務(wù)器崩潰導(dǎo)致數(shù)據(jù)不一致的風(fēng)險(xiǎn)。Master服務(wù)器不會(huì)持久保存Chunk位置信息。Master服務(wù)器在啟動(dòng)時(shí),或者有新的Chunk服務(wù)器加入時(shí),向各個(gè)Chunk服務(wù)器輪詢(xún)它們所存儲(chǔ)的Chunk的信息。
2.6.1 內(nèi)存中的數(shù)據(jù)結(jié)構(gòu)
因?yàn)樵獢?shù)據(jù)保存在內(nèi)存中,所以Master服務(wù)器的操作速度非常快。并且,Master服務(wù)器可以在后臺(tái)簡(jiǎn)單而高效的周期性掃描自己保存的全部狀態(tài)信息。這種周期性的狀態(tài)掃描也用于實(shí)現(xiàn)Chunk垃圾收集、在Chunk服務(wù)器失效的時(shí)重新復(fù)制數(shù)據(jù)、通過(guò)Chunk的遷移實(shí)現(xiàn)跨Chunk服務(wù)器的負(fù)載均衡以及磁盤(pán)使用狀況統(tǒng)計(jì)等功能。4.3和4.4章節(jié)將深入討論這些行為。
將元數(shù)據(jù)全部保存在內(nèi)存中的方法有潛在問(wèn)題:Chunk的數(shù)量以及整個(gè)系統(tǒng)的承載能力都受限于Master服務(wù)器所擁有的內(nèi)存大小。但是在實(shí)際應(yīng)用中,這并不是一個(gè)嚴(yán)重的問(wèn)題。Master服務(wù)器只需要不到64個(gè)字節(jié)的元數(shù)據(jù)就能夠管理一個(gè)64MB的Chunk。由于大多數(shù)文件都包含多個(gè)Chunk,因此絕大多數(shù)Chunk都是滿的,除了文件的最后一個(gè)Chunk是部分填充的。同樣的,每個(gè)文件的在命名空間中的數(shù)據(jù)大小通常在64字節(jié)以下,因?yàn)楸4娴奈募怯们熬Y壓縮算法壓縮過(guò)的。
即便是需要支持更大的文件系統(tǒng),為Master服務(wù)器增加額外內(nèi)存的費(fèi)用是很少的,而通過(guò)增加有限的費(fèi)用,我們就能夠把元數(shù)據(jù)全部保存在內(nèi)存里,增強(qiáng)了系統(tǒng)的簡(jiǎn)潔性、可靠性、高性能和靈活性。
2.6.2 Chunk位置信息
Master服務(wù)器并不保存持久化保存哪個(gè)Chunk服務(wù)器存有指定Chunk的副本的信息。Master服務(wù)器只是在啟動(dòng)的時(shí)候輪詢(xún)Chunk服務(wù)器以獲取這些信息。Master服務(wù)器能夠保證它持有的信息始終是最新的,因?yàn)樗刂屏怂械腃hunk位置的分配,而且通過(guò)周期性的心跳信息監(jiān)控Chunk服務(wù)器的狀態(tài)。
最初設(shè)計(jì)時(shí),我們?cè)噲D把Chunk的位置信息持久的保存在Master服務(wù)器上,但是后來(lái)我們發(fā)現(xiàn)在啟動(dòng)的時(shí)候輪詢(xún)Chunk服務(wù)器,之后定期輪詢(xún)更新的方式更簡(jiǎn)單。這種設(shè)計(jì)簡(jiǎn)化了在有Chunk服務(wù)器加入集群、離開(kāi)集群、更名、失效、以及重啟的時(shí)候,Master服務(wù)器和Chunk服務(wù)器數(shù)據(jù)同步的問(wèn)題。在一個(gè)擁有數(shù)百臺(tái)服務(wù)器的集群中,這類(lèi)事件會(huì)頻繁的發(fā)生。
可以從另外一個(gè)角度去理解這個(gè)設(shè)計(jì)決策:只有Chunk服務(wù)器才能最終確定一個(gè)Chunk是否在它的硬盤(pán)上。我們從沒(méi)有考慮過(guò)在Master服務(wù)器上維護(hù)一個(gè)這些信息的全局視圖,因?yàn)镃hunk服務(wù)器的錯(cuò)誤可能會(huì)導(dǎo)致Chunk自動(dòng)消失(比如,硬盤(pán)損壞了或者無(wú)法訪問(wèn)了),亦或者操作人員可能會(huì)重命名一個(gè)Chunk服務(wù)器。
2.6.3 操作日志
操作日志包含了關(guān)鍵的元數(shù)據(jù)變更歷史記錄。這對(duì)GFS非常重要。這不僅僅是因?yàn)椴僮魅罩臼窃獢?shù)據(jù)唯一的持久化存儲(chǔ)記錄,它也作為判斷同步操作順序的邏輯時(shí)間基線(alex注:也就是通過(guò)邏輯日志的序號(hào)作為操作發(fā)生的邏輯時(shí)間,類(lèi)似于事務(wù)系統(tǒng)中的LSN)。文件和Chunk,連同它們的版本(參考4.5節(jié)),都由它們創(chuàng)建的邏輯時(shí)間唯一的、永久的標(biāo)識(shí)。
操作日志非常重要,我們必須確保日志文件的完整,確保只有在元數(shù)據(jù)的變化被持久化后,日志才對(duì)客戶(hù)端是可見(jiàn)的。否則,即使Chunk本身沒(méi)有出現(xiàn)任何問(wèn)題,我們?nèi)杂锌赡軄G失整個(gè)文件系統(tǒng),或者丟失客戶(hù)端最近的操作。所以,我們會(huì)把日志復(fù)制到多臺(tái)遠(yuǎn)程機(jī)器,并且只有把相應(yīng)的日志記錄寫(xiě)入到本地以及遠(yuǎn)程機(jī)器的硬盤(pán)后,才會(huì)響應(yīng)客戶(hù)端的操作請(qǐng)求。Master服務(wù)器會(huì)收集多個(gè)日志記錄后批量處理,以減少寫(xiě)入磁盤(pán)和復(fù)制對(duì)系統(tǒng)整體性能的影響。
Master服務(wù)器在災(zāi)難恢復(fù)時(shí),通過(guò)重演操作日志把文件系統(tǒng)恢復(fù)到最近的狀態(tài)。為了縮短Master啟動(dòng)的時(shí)間,我們必須使日志足夠小(alex注:即重演系統(tǒng)操作的日志量盡量的少)。Master服務(wù)器在日志增長(zhǎng)到一定量時(shí)對(duì)系統(tǒng)狀態(tài)做一次
由于創(chuàng)建一個(gè)Checkpoint文件需要一定的時(shí)間,所以Master服務(wù)器的內(nèi)部狀態(tài)被組織為一種格式,這種格式要確保在Checkpoint過(guò)程中不會(huì)阻塞正在進(jìn)行的修改操作。Master服務(wù)器使用獨(dú)立的線程切換到新的日志文件和創(chuàng)建新的Checkpoint文件。新的Checkpoint文件包括切換前所有的修改。對(duì)于一個(gè)包含數(shù)百萬(wàn)個(gè)文件的集群,創(chuàng)建一個(gè)Checkpoint文件需要1分鐘左右的時(shí)間。創(chuàng)建完成后,Checkpoint文件會(huì)被寫(xiě)入在本地和遠(yuǎn)程的硬盤(pán)里。
Master服務(wù)器恢復(fù)只需要最新的Checkpoint文件和后續(xù)的日志文件。舊的Checkpoint文件和日志文件可以被刪除,但是為了應(yīng)對(duì)災(zāi)難性的故障(alex注:catastrophes,數(shù)據(jù)備份相關(guān)文檔中經(jīng)常會(huì)遇到這個(gè)詞,表示一種超出預(yù)期范圍的災(zāi)難性事件),我們通常會(huì)多保存一些歷史文件。Checkpoint失敗不會(huì)對(duì)正確性產(chǎn)生任何影響,因?yàn)榛謴?fù)功能的代碼可以檢測(cè)并跳過(guò)沒(méi)有完成的Checkpoint文件。
2.7 一致性模型
GFS支持一個(gè)寬松的一致性模型,這個(gè)模型能夠很好的支撐我們的高度分布的應(yīng)用,同時(shí)還保持了相對(duì)簡(jiǎn)單且容易實(shí)現(xiàn)的優(yōu)點(diǎn)。本節(jié)我們討論GFS的一致性的保障機(jī)制,以及對(duì)應(yīng)用程序的意義。我們也著重描述了GFS如何管理這些一致性保障機(jī)制,但是實(shí)現(xiàn)的細(xì)節(jié)將在本論文的其它部分討論。
2.7.1 GFS一致性保障機(jī)制
文件命名空間的修改(例如,文件創(chuàng)建)是原子性的。它們僅由Master節(jié)點(diǎn)的控制:命名空間鎖提供了原子性和正確性(4.1章)的保障;Master節(jié)點(diǎn)的操作日志定義了這些操作在全局的順序(2.6.3章)。

數(shù)據(jù)修改后文件region(alex注:region這個(gè)詞用中文非常難以表達(dá),我認(rèn)為應(yīng)該是修改操作所涉及的文件中的某個(gè)范圍)的狀態(tài)取決于操作的類(lèi)型、成功與否、以及是否同步修改。表1總結(jié)了各種操作的結(jié)果。如果所有客戶(hù)端,無(wú)論從哪個(gè)副本讀取,讀到的數(shù)據(jù)都一樣,那么我們認(rèn)為文件region是“一致的”;如果對(duì)文件的數(shù)據(jù)修改之后,region是一致的,并且客戶(hù)端能夠看到寫(xiě)入操作全部的內(nèi)容,那么這個(gè)region是“已定義的”。當(dāng)一個(gè)數(shù)據(jù)修改操作成功執(zhí)行,并且沒(méi)有受到同時(shí)執(zhí)行的其它寫(xiě)入操作的干擾,那么影響的region就是已定義的(隱含了一致性):所有的客戶(hù)端都可以看到寫(xiě)入的內(nèi)容。并行修改操作成功完成之后,region處于一致的、未定義的狀態(tài):所有的客戶(hù)端看到同樣的數(shù)據(jù),但是無(wú)法讀到任何一次寫(xiě)入操作寫(xiě)入的數(shù)據(jù)。通常情況下,文件region內(nèi)包含了來(lái)自多個(gè)修改操作的、混雜的數(shù)據(jù)片段。失敗的修改操作導(dǎo)致一個(gè)region處于不一致?tīng)顟B(tài)(同時(shí)也是未定義的):不同的客戶(hù)在不同的時(shí)間會(huì)看到不同的數(shù)據(jù)。后面我們將描述應(yīng)用如何區(qū)分已定義和未定義的region。應(yīng)用程序沒(méi)有必要再去細(xì)分未定義region的不同類(lèi)型。
數(shù)據(jù)修改操作分為寫(xiě)入或者記錄追加兩種。寫(xiě)入操作把數(shù)據(jù)寫(xiě)在應(yīng)用程序指定的文件偏移位置上。即使有多個(gè)修改操作并行執(zhí)行時(shí),記錄追加操作至少可以把數(shù)據(jù)原子性的追加到文件中一次,但是偏移位置是由GFS選擇的(3.3章)(alex注:這句話有點(diǎn)費(fèi)解,其含義是所有的追加寫(xiě)入都會(huì)成功,但是有可能被執(zhí)行了多次,而且每次追加的文件偏移量由GFS自己計(jì)算)。(相比而言,通常說(shuō)的追加操作寫(xiě)的偏移位置是文件的尾部。)GFS返回給客戶(hù)端一個(gè)偏移量,表示了包含了寫(xiě)入記錄的、已定義的region的起點(diǎn)。另外,GFS可能會(huì)在文件中間插入填充數(shù)據(jù)或者重復(fù)記錄。這些數(shù)據(jù)占據(jù)的文件region被認(rèn)定是不一致的,這些數(shù)據(jù)通常比用戶(hù)數(shù)據(jù)小的多。
經(jīng)過(guò)了一系列的成功的修改操作之后,GFS確保被修改的文件region是已定義的,并且包含最后一次修改操作寫(xiě)入的數(shù)據(jù)。GFS通過(guò)以下措施確保上述行為:(a) 對(duì)Chunk的所有副本的修改操作順序一致(3.1章),(b)使用Chunk的版本號(hào)來(lái)檢測(cè)副本是否因?yàn)樗诘腃hunk服務(wù)器宕機(jī)(4.5章)而錯(cuò)過(guò)了修改操作而導(dǎo)致其失效。失效的副本不會(huì)再進(jìn)行任何修改操作,Master服務(wù)器也不再返回這個(gè)Chunk副本的位置信息給客戶(hù)端。它們會(huì)被垃圾收集系統(tǒng)盡快回收。
由于Chunk位置信息會(huì)被客戶(hù)端緩存,所以在信息刷新前,客戶(hù)端有可能從一個(gè)失效的副本讀取了數(shù)據(jù)。在緩存的超時(shí)時(shí)間和文件下一次被打開(kāi)的時(shí)間之間存在一個(gè)時(shí)間窗,文件再次被打開(kāi)后會(huì)清除緩存中與該文件有關(guān)的所有Chunk位置信息。而且,由于我們的文件大多數(shù)都是只進(jìn)行追加操作的,所以,一個(gè)失效的副本通常返回一個(gè)提前結(jié)束的Chunk而不是過(guò)期的數(shù)據(jù)。當(dāng)一個(gè)Reader(alex注:本文中將用到兩個(gè)專(zhuān)有名詞,Reader和Writer,分別表示執(zhí)行GFS讀取和寫(xiě)入操作的程序)重新嘗試并聯(lián)絡(luò)Master服務(wù)器時(shí),它就會(huì)立刻得到最新的Chunk位置信息。
即使在修改操作成功執(zhí)行很長(zhǎng)時(shí)間之后,組件的失效也可能損壞或者刪除數(shù)據(jù)。GFS通過(guò)Master服務(wù)器和所有Chunk服務(wù)器的定期“握手”來(lái)找到失效的Chunk服務(wù)器,并且使用Checksum來(lái)校驗(yàn)數(shù)據(jù)是否損壞(5.2章)。一旦發(fā)現(xiàn)問(wèn)題,數(shù)據(jù)要盡快利用有效的副本進(jìn)行恢復(fù)(4.3章)。只有當(dāng)一個(gè)Chunk的所有副本在GFS檢測(cè)到錯(cuò)誤并采取應(yīng)對(duì)措施之前全部丟失,這個(gè)Chunk才會(huì)不可逆轉(zhuǎn)的丟失。在一般情況下GFS的反應(yīng)時(shí)間(alex注:指Master節(jié)點(diǎn)檢測(cè)到錯(cuò)誤并采取應(yīng)對(duì)措施)是幾分鐘。即使在這種情況下,Chunk也只是不可用了,而不是損壞了:應(yīng)用程序會(huì)收到明確的錯(cuò)誤信息而不是損壞的數(shù)據(jù)。
2.7.2 程序的實(shí)現(xiàn)
使用GFS的應(yīng)用程序可以利用一些簡(jiǎn)單技術(shù)實(shí)現(xiàn)這個(gè)寬松的一致性模型,這些技術(shù)也用來(lái)實(shí)現(xiàn)一些其它的目標(biāo)功能,包括:盡量采用追加寫(xiě)入而不是覆蓋,Checkpoint,自驗(yàn)證的寫(xiě)入操作,自標(biāo)識(shí)的記錄。
在實(shí)際應(yīng)用中,我們所有的應(yīng)用程序?qū)ξ募膶?xiě)入操作都是盡量采用數(shù)據(jù)追加方式,而不是覆蓋方式。一種典型的應(yīng)用,應(yīng)用程序從頭到尾寫(xiě)入數(shù)據(jù),生成了一個(gè)文件。寫(xiě)入所有數(shù)據(jù)之后,應(yīng)用程序自動(dòng)將文件改名為一個(gè)永久保存的文件名,或者周期性的作Checkpoint,記錄成功寫(xiě)入了多少數(shù)據(jù)。Checkpoint文件可以包含程序級(jí)別的校驗(yàn)和。Readers僅校驗(yàn)并處理上個(gè)Checkpoint之后產(chǎn)生的文件region,這些文件region的狀態(tài)一定是已定義的。這個(gè)方法滿足了我們一致性和并發(fā)處理的要求。追加寫(xiě)入比隨機(jī)位置寫(xiě)入更加有效率,對(duì)應(yīng)用程序的失敗處理更具有彈性。Checkpoint可以讓W(xué)riter以漸進(jìn)的方式重新開(kāi)始,并且可以防止Reader處理已經(jīng)被成功寫(xiě)入,但是從應(yīng)用程序的角度來(lái)看還并未完成的數(shù)據(jù)。
我們?cè)賮?lái)分析另一種典型的應(yīng)用。許多應(yīng)用程序并行的追加數(shù)據(jù)到同一個(gè)文件,比如進(jìn)行結(jié)果的合并或者是一個(gè)生產(chǎn)者-消費(fèi)者隊(duì)列。記錄追加方式的“至少一次追加”的特性保證了Writer的輸出。Readers使用下面的方法來(lái)處理偶然性的填充數(shù)據(jù)和重復(fù)內(nèi)容。Writers在每條寫(xiě)入的記錄中都包含了額外的信息,例如Checksum,用來(lái)驗(yàn)證它的有效性。Reader可以利用Checksum識(shí)別和拋棄額外的填充數(shù)據(jù)和記錄片段。如果應(yīng)用不能容忍偶爾的重復(fù)內(nèi)容(比如,如果這些重復(fù)數(shù)據(jù)觸發(fā)了非冪等操作),可以用記錄的唯一標(biāo)識(shí)符來(lái)過(guò)濾它們,這些唯一標(biāo)識(shí)符通常用于命名程序中處理的實(shí)體對(duì)象,例如web文檔。這些記錄I/O功能(alex注:These functionalities for record I/O)(除了剔除重復(fù)數(shù)據(jù))都包含在我們的程序共享的庫(kù)中,并且適用于Google內(nèi)部的其它的文件接口實(shí)現(xiàn)。所以,相同序列的記錄,加上一些偶爾出現(xiàn)的重復(fù)數(shù)據(jù),都被分發(fā)到Reader了。
#p#
3. 系統(tǒng)交互
我們?cè)谠O(shè)計(jì)這個(gè)系統(tǒng)時(shí),一個(gè)重要的原則是最小化所有操作和Master節(jié)點(diǎn)的交互。帶著這樣的設(shè)計(jì)理念,我們現(xiàn)在描述一下客戶(hù)機(jī)、Master服務(wù)器和Chunk服務(wù)器如何進(jìn)行交互,以實(shí)現(xiàn)數(shù)據(jù)修改操作、原子的記錄追加操作以及快照功能。
3.1 租約(lease)和變更順序
(alex注:lease是數(shù)據(jù)庫(kù)中的一個(gè)術(shù)語(yǔ))
變更是一個(gè)會(huì)改變Chunk內(nèi)容或者元數(shù)據(jù)的操作,比如寫(xiě)入操作或者記錄追加操作。變更操作會(huì)在Chunk的所有副本上執(zhí)行。我們使用租約(lease)機(jī)制來(lái)保持多個(gè)副本間變更順序的一致性。Master節(jié)點(diǎn)為Chunk的一個(gè)副本建立一個(gè)租約,我們把這個(gè)副本叫做主Chunk。主Chunk對(duì)Chunk的所有更改操作進(jìn)行序列化。所有的副本都遵從這個(gè)序列進(jìn)行修改操作。因此,修改操作全局的順序首先由Master節(jié)點(diǎn)選擇的租約的順序決定,然后由租約中主Chunk分配的序列號(hào)決定。
設(shè)計(jì)租約機(jī)制的目的是為了最小化Master節(jié)點(diǎn)的管理負(fù)擔(dān)。租約的初始超時(shí)設(shè)置為60秒。不過(guò),只要Chunk被修改了,主Chunk就可以申請(qǐng)更長(zhǎng)的租期,通常會(huì)得到Master節(jié)點(diǎn)的確認(rèn)并收到租約延長(zhǎng)的時(shí)間。這些租約延長(zhǎng)請(qǐng)求和批準(zhǔn)的信息通常都是附加在Master節(jié)點(diǎn)和Chunk服務(wù)器之間的心跳消息中來(lái)傳遞。有時(shí)Master節(jié)點(diǎn)會(huì)試圖提前取消租約(例如,Master節(jié)點(diǎn)想取消在一個(gè)已經(jīng)被改名的文件上的修改操作)。即使Master節(jié)點(diǎn)和主Chunk失去聯(lián)系,它仍然可以安全地在舊的租約到期后和另外一個(gè)Chunk副本簽訂新的租約。
在圖2中,我們依據(jù)步驟編號(hào),展現(xiàn)寫(xiě)入操作的控制流程。

◆ 客戶(hù)機(jī)向Master節(jié)點(diǎn)詢(xún)問(wèn)哪一個(gè)Chunk服務(wù)器持有當(dāng)前的租約,以及其它副本的位置。如果沒(méi)有一個(gè)Chunk持有租約,Master節(jié)點(diǎn)就選擇其中一個(gè)副本建立一個(gè)租約(這個(gè)步驟在圖上沒(méi)有顯示)。
◆ Master節(jié)點(diǎn)將主Chunk的標(biāo)識(shí)符以及其它副本(又稱(chēng)為secondary副本、二級(jí)副本)的位置返回給客戶(hù)機(jī)。客戶(hù)機(jī)緩存這些數(shù)據(jù)以便后續(xù)的操作。只有在主Chunk不可用,或者主Chunk回復(fù)信息表明它已不再持有租約的時(shí)候,客戶(hù)機(jī)才需要重新跟Master節(jié)點(diǎn)聯(lián)系。
◆ 客戶(hù)機(jī)把數(shù)據(jù)推送到所有的副本上。客戶(hù)機(jī)可以以任意的順序推送數(shù)據(jù)。Chunk服務(wù)器接收到數(shù)據(jù)并保存在它的內(nèi)部LRU緩存中,一直到數(shù)據(jù)被使用或者過(guò)期交換出去。由于數(shù)據(jù)流的網(wǎng)絡(luò)傳輸負(fù)載非常高,通過(guò)分離數(shù)據(jù)流和控制流,我們可以基于網(wǎng)絡(luò)拓?fù)淝闆r對(duì)數(shù)據(jù)流進(jìn)行規(guī)劃,提高系統(tǒng)性能,而不用去理會(huì)哪個(gè)Chunk服務(wù)器保存了主Chunk。3.2章節(jié)會(huì)進(jìn)一步討論這點(diǎn)。
◆當(dāng)所有的副本都確認(rèn)接收到了數(shù)據(jù),客戶(hù)機(jī)發(fā)送寫(xiě)請(qǐng)求到主Chunk服務(wù)器。這個(gè)請(qǐng)求標(biāo)識(shí)了早前推送到所有副本的數(shù)據(jù)。主Chunk為接收到的所有操作分配連續(xù)的序列號(hào),這些操作可能來(lái)自不同的客戶(hù)機(jī),序列號(hào)保證了操作順序執(zhí)行。它以序列號(hào)的順序把操作應(yīng)用到它自己的本地狀態(tài)中(alex注:也就是在本地執(zhí)行這些操作,這句話按字面翻譯有點(diǎn)費(fèi)解,也許應(yīng)該翻譯為“它順序執(zhí)行這些操作,并更新自己的狀態(tài)”)。
◆主Chunk把寫(xiě)請(qǐng)求傳遞到所有的二級(jí)副本。每個(gè)二級(jí)副本依照主Chunk分配的序列號(hào)以相同的順序執(zhí)行這些操作。
◆所有的二級(jí)副本回復(fù)主Chunk,它們已經(jīng)完成了操作。
◆主Chunk服務(wù)器(alex注:即主Chunk所在的Chunk服務(wù)器)回復(fù)客戶(hù)機(jī)。任何副本產(chǎn)生的任何錯(cuò)誤都會(huì)返回給客戶(hù)機(jī)。在出現(xiàn)錯(cuò)誤的情況下,寫(xiě)入操作可能在主Chunk和一些二級(jí)副本執(zhí)行成功。(如果操作在主Chunk上失敗了,操作就不會(huì)被分配序列號(hào),也不會(huì)被傳遞。)客戶(hù)端的請(qǐng)求被確認(rèn)為失敗,被修改的region處于不一致的狀態(tài)。我們的客戶(hù)機(jī)代碼通過(guò)重復(fù)執(zhí)行失敗的操作來(lái)處理這樣的錯(cuò)誤。在從頭開(kāi)始重復(fù)執(zhí)行之前,客戶(hù)機(jī)會(huì)先從步驟(3)到步驟(7)做幾次嘗試。
如果應(yīng)用程序一次寫(xiě)入的數(shù)據(jù)量很大,或者數(shù)據(jù)跨越了多個(gè)Chunk,GFS客戶(hù)機(jī)代碼會(huì)把它們分成多個(gè)寫(xiě)操作。這些操作都遵循前面描述的控制流程,但是可能會(huì)被其它客戶(hù)機(jī)上同時(shí)進(jìn)行的操作打斷或者覆蓋。因此,共享的文件region的尾部可能包含來(lái)自不同客戶(hù)機(jī)的數(shù)據(jù)片段,盡管如此,由于這些分解后的寫(xiě)入操作在所有的副本上都以相同的順序執(zhí)行完成,Chunk的所有副本都是一致的。這使文件region處于2.7節(jié)描述的一致的、但是未定義的狀態(tài)。
3.2 數(shù)據(jù)流
為了提高網(wǎng)絡(luò)效率,我們采取了把數(shù)據(jù)流和控制流分開(kāi)的措施。在控制流從客戶(hù)機(jī)到主Chunk、然后再到所有二級(jí)副本的同時(shí),數(shù)據(jù)以管道的方式,順序的沿著一個(gè)精心選擇的Chunk服務(wù)器鏈推送。我們的目標(biāo)是充分利用每臺(tái)機(jī)器的帶寬,避免網(wǎng)絡(luò)瓶頸和高延時(shí)的連接,最小化推送所有數(shù)據(jù)的延時(shí)。
為了充分利用每臺(tái)機(jī)器的帶寬,數(shù)據(jù)沿著一個(gè)Chunk服務(wù)器鏈順序的推送,而不是以其它拓?fù)湫问椒稚⑼扑停ɡ纾瑯?shù)型拓?fù)浣Y(jié)構(gòu))。線性推送模式下,每臺(tái)機(jī)器所有的出口帶寬都用于以最快的速度傳輸數(shù)據(jù),而不是在多個(gè)接受者之間分配帶寬。
為了盡可能的避免出現(xiàn)網(wǎng)絡(luò)瓶頸和高延遲的鏈接(eg,inter-switch最有可能出現(xiàn)類(lèi)似問(wèn)題),每臺(tái)機(jī)器都盡量的在網(wǎng)絡(luò)拓?fù)渲羞x擇一臺(tái)還沒(méi)有接收到數(shù)據(jù)的、離自己最近的機(jī)器作為目標(biāo)推送數(shù)據(jù)。假設(shè)客戶(hù)機(jī)把數(shù)據(jù)從Chunk服務(wù)器S1推送到S4。它把數(shù)據(jù)推送到最近的Chunk服務(wù)器S1。S1把數(shù)據(jù)推送到S2,因?yàn)镾2和S4中最接近的機(jī)器是S2。同樣的,S2把數(shù)據(jù)傳遞給S3和S4之間更近的機(jī)器,依次類(lèi)推推送下去。我們的網(wǎng)絡(luò)拓?fù)浞浅:?jiǎn)單,通過(guò)IP地址就可以計(jì)算出節(jié)點(diǎn)的“距離”。
最后,我們利用基于TCP連接的、管道式數(shù)據(jù)推送方式來(lái)最小化延遲。Chunk服務(wù)器接收到數(shù)據(jù)后,馬上開(kāi)始向前推送。管道方式的數(shù)據(jù)推送對(duì)我們幫助很大,因?yàn)槲覀儾捎萌p工的交換網(wǎng)絡(luò)。接收到數(shù)據(jù)后立刻向前推送不會(huì)降低接收的速度。在沒(méi)有網(wǎng)絡(luò)擁塞的情況下,傳送B字節(jié)的數(shù)據(jù)到R個(gè)副本的理想時(shí)間是 B/T+RL ,T是網(wǎng)絡(luò)的吞吐量,L是在兩臺(tái)機(jī)器數(shù)據(jù)傳輸?shù)难舆t。通常情況下,我們的網(wǎng)絡(luò)連接速度是100Mbps(T),L將遠(yuǎn)小于1ms。因此,1MB的數(shù)據(jù)在理想情況下80ms左右就能分發(fā)出去。
3.3 原子的記錄追加
GFS提供了一種原子的數(shù)據(jù)追加操作–記錄追加。傳統(tǒng)方式的寫(xiě)入操作,客戶(hù)程序會(huì)指定數(shù)據(jù)寫(xiě)入的偏移量。對(duì)同一個(gè)region的并行寫(xiě)入操作不是串行的:region尾部可能會(huì)包含多個(gè)不同客戶(hù)機(jī)寫(xiě)入的數(shù)據(jù)片段。使用記錄追加,客戶(hù)機(jī)只需要指定要寫(xiě)入的數(shù)據(jù)。GFS保證至少有一次原子的寫(xiě)入操作成功執(zhí)行(即寫(xiě)入一個(gè)順序的
記錄追加在我們的分布應(yīng)用中非常頻繁的使用,在這些分布式應(yīng)用中,通常有很多的客戶(hù)機(jī)并行地對(duì)同一個(gè)文件追加寫(xiě)入數(shù)據(jù)。如果我們采用傳統(tǒng)方式的文件寫(xiě)入操作,客戶(hù)機(jī)需要額外的復(fù)雜、昂貴的同步機(jī)制,例如使用一個(gè)分布式的鎖管理器。在我們的工作中,這樣的文件通常用于多個(gè)生產(chǎn)者/單一消費(fèi)者的隊(duì)列系統(tǒng),或者是合并了來(lái)自多個(gè)客戶(hù)機(jī)的數(shù)據(jù)的結(jié)果文件。
記錄追加是一種修改操作,它也遵循3.1節(jié)描述的控制流程,除了在主Chunk有些額外的控制邏輯。客戶(hù)機(jī)把數(shù)據(jù)推送給文件最后一個(gè)Chunk的所有副本,之后發(fā)送請(qǐng)求給主Chunk。主Chunk會(huì)檢查這次記錄追加操作是否會(huì)使Chunk超過(guò)最大尺寸(64MB)。如果超過(guò)了最大尺寸,主Chunk首先將當(dāng)前Chunk填充到最大尺寸,之后通知所有二級(jí)副本做同樣的操作,然后回復(fù)客戶(hù)機(jī)要求其對(duì)下一個(gè)Chunk重新進(jìn)行記錄追加操作。(記錄追加的數(shù)據(jù)大小嚴(yán)格控制在Chunk最大尺寸的1/4,這樣即使在最壞情況下,數(shù)據(jù)碎片的數(shù)量仍然在可控的范圍。)通常情況下追加的記錄不超過(guò)Chunk的最大尺寸,主Chunk把數(shù)據(jù)追加到自己的副本內(nèi),然后通知二級(jí)副本把數(shù)據(jù)寫(xiě)在跟主Chunk一樣的位置上,最后回復(fù)客戶(hù)機(jī)操作成功。
如果記錄追加操作在任何一個(gè)副本上失敗了,客戶(hù)端就需要重新進(jìn)行操作。重新進(jìn)行記錄追加的結(jié)果是,同一個(gè)Chunk的不同副本可能包含不同的數(shù)據(jù)–重復(fù)包含一個(gè)記錄全部或者部分的數(shù)據(jù)。GFS并不保證Chunk的所有副本在字節(jié)級(jí)別是完全一致的。它只保證數(shù)據(jù)作為一個(gè)整體原子的被至少寫(xiě)入一次。這個(gè)特性可以通過(guò)簡(jiǎn)單觀察推導(dǎo)出來(lái):如果操作成功執(zhí)行,數(shù)據(jù)一定已經(jīng)寫(xiě)入到Chunk的所有副本的相同偏移位置上。這之后,所有的副本至少都到了記錄尾部的長(zhǎng)度,任何后續(xù)的記錄都會(huì)追加到更大的偏移地址,或者是不同的Chunk上,即使其它的Chunk副本被Master節(jié)點(diǎn)選為了主Chunk。就我們的一致性保障模型而言,記錄追加操作成功寫(xiě)入數(shù)據(jù)的region是已定義的(因此也是一致的),反之則是不一致的(因此也就是未定義的)。正如我們?cè)?.7.2節(jié)討論的,我們的程序可以處理不一致的區(qū)域。
3.4 快照
(alex注:這一節(jié)非常難以理解,總的來(lái)說(shuō)依次講述了什么是快照、快照使用的COW技術(shù)、快照如何不干擾當(dāng)前操作)
快照操作幾乎可以瞬間完成對(duì)一個(gè)文件或者目錄樹(shù)(“源”)做一個(gè)拷貝,并且?guī)缀醪粫?huì)對(duì)正在進(jìn)行的其它操作造成任何干擾。我們的用戶(hù)可以使用快照迅速的創(chuàng)建一個(gè)巨大的數(shù)據(jù)集的分支拷貝(而且經(jīng)常是遞歸的拷貝拷貝),或者是在做實(shí)驗(yàn)性的數(shù)據(jù)操作之前,使用快照操作備份當(dāng)前狀態(tài),這樣之后就可以輕松的提交或者回滾到備份時(shí)的狀態(tài)。
就像AFS(alex注:AFS,即Andrew File System,一種分布式文件系統(tǒng)),我們用標(biāo)準(zhǔn)的copy-on-write技術(shù)實(shí)現(xiàn)快照。當(dāng)Master節(jié)點(diǎn)收到一個(gè)快照請(qǐng)求,它首先取消作快照的文件的所有Chunk的租約。這個(gè)措施保證了后續(xù)對(duì)這些Chunk的寫(xiě)操作都必須與Master交互交互以找到租約持有者。這就給Master節(jié)點(diǎn)一個(gè)率先創(chuàng)建Chunk的新拷貝的機(jī)會(huì)。
租約取消或者過(guò)期之后,Master節(jié)點(diǎn)把這個(gè)操作以日志的方式記錄到硬盤(pán)上。然后,Master節(jié)點(diǎn)通過(guò)復(fù)制源文件或者目錄的元數(shù)據(jù)的方式,把這條日志記錄的變化反映到保存在內(nèi)存的狀態(tài)中。新創(chuàng)建的快照文件和源文件指向完全相同的Chunk地址。
在快照操作之后,當(dāng)客戶(hù)機(jī)第一次想寫(xiě)入數(shù)據(jù)到Chunk C,它首先會(huì)發(fā)送一個(gè)請(qǐng)求到Master節(jié)點(diǎn)查詢(xún)當(dāng)前的租約持有者。Master節(jié)點(diǎn)注意到Chunke C的引用計(jì)數(shù)超過(guò)了1(alex注:不太明白為什么會(huì)大于1.難道是Snapshot沒(méi)有釋放引用計(jì)數(shù)?)。Master節(jié)點(diǎn)不會(huì)馬上回復(fù)客戶(hù)機(jī)的請(qǐng)求,而是選擇一個(gè)新的Chunk句柄C`。之后,Master節(jié)點(diǎn)要求每個(gè)擁有Chunk C當(dāng)前副本的Chunk服務(wù)器創(chuàng)建一個(gè)叫做C`的新Chunk。通過(guò)在源Chunk所在Chunk服務(wù)器上創(chuàng)建新的Chunk,我們確保數(shù)據(jù)在本地而不是通過(guò)網(wǎng)絡(luò)復(fù)制(我們的硬盤(pán)比我們的100Mb以太網(wǎng)大約快3倍)。從這點(diǎn)來(lái)講,請(qǐng)求的處理方式和任何其它Chunk沒(méi)什么不同:Master節(jié)點(diǎn)確保新Chunk C`的一個(gè)副本擁有租約,之后回復(fù)客戶(hù)機(jī),客戶(hù)機(jī)得到回復(fù)后就可以正常的寫(xiě)這個(gè)Chunk,而不必理會(huì)它是從一個(gè)已存在的Chunk克隆出來(lái)的。
#p#
4. Master節(jié)點(diǎn)的操作
Master節(jié)點(diǎn)執(zhí)行所有的名稱(chēng)空間操作。此外,它還管理著整個(gè)系統(tǒng)里所有Chunk的副本:它決定Chunk的存儲(chǔ)位置,創(chuàng)建新Chunk和它的副本,協(xié)調(diào)各種各樣的系統(tǒng)活動(dòng)以保證Chunk被完全復(fù)制,在所有的Chunk服務(wù)器之間的進(jìn)行負(fù)載均衡,回收不再使用的存儲(chǔ)空間。本節(jié)我們討論上述的主題。
4.1 名稱(chēng)空間管理和鎖
Master節(jié)點(diǎn)的很多操作會(huì)花費(fèi)很長(zhǎng)的時(shí)間:比如,快照操作必須取消Chunk服務(wù)器上快照所涉及的所有的Chunk的租約。我們不希望在這些操作的運(yùn)行時(shí),延緩了其它的Master節(jié)點(diǎn)的操作。因此,我們?cè)试S多個(gè)操作同時(shí)進(jìn)行,使用名稱(chēng)空間的region上的鎖來(lái)保證執(zhí)行的正確順序。
不同于許多傳統(tǒng)文件系統(tǒng),GFS沒(méi)有針對(duì)每個(gè)目錄實(shí)現(xiàn)能夠列出目錄下所有文件的數(shù)據(jù)結(jié)構(gòu)。GFS也不支持文件或者目錄的鏈接(即Unix術(shù)語(yǔ)中的硬鏈接或者符號(hào)鏈接)。在邏輯上,GFS的名稱(chēng)空間就是一個(gè)全路徑和元數(shù)據(jù)映射關(guān)系的查找表。利用前綴壓縮,這個(gè)表可以高效的存儲(chǔ)在內(nèi)存中。在存儲(chǔ)名稱(chēng)空間的樹(shù)型結(jié)構(gòu)上,每個(gè)節(jié)點(diǎn)(絕對(duì)路徑的文件名或絕對(duì)路徑的目錄名)都有一個(gè)關(guān)聯(lián)的讀寫(xiě)鎖。
每個(gè)Master節(jié)點(diǎn)的操作在開(kāi)始之前都要獲得一系列的鎖。通常情況下,如果一個(gè)操作涉及/d1/d2/…/dn/leaf,那么操作首先要獲得目錄/d1,/d1/d2,…,/d1/d2/…/dn的讀鎖,以及/d1/d2/…/dn/leaf的讀寫(xiě)鎖。注意,根據(jù)操作的不同,leaf可以是一個(gè)文件,也可以是一個(gè)目錄。
現(xiàn)在,我們演示一下在/home/user被快照到/save/user的時(shí)候,鎖機(jī)制如何防止創(chuàng)建文件/home/user/foo。快照操作獲取/home和/save的讀取鎖,以及/home/user和/save/user的寫(xiě)入鎖。文件創(chuàng)建操作獲得/home和/home/user的讀取鎖,以及/home/user/foo的寫(xiě)入鎖。這兩個(gè)操作要順序執(zhí)行,因?yàn)樗鼈冊(cè)噲D獲取的/home/user的鎖是相互沖突。文件創(chuàng)建操作不需要獲取父目錄的寫(xiě)入鎖,因?yàn)檫@里沒(méi)有”目錄”,或者類(lèi)似inode等用來(lái)禁止修改的數(shù)據(jù)結(jié)構(gòu)。文件名的讀取鎖足以防止父目錄被刪除。
采用這種鎖方案的優(yōu)點(diǎn)是支持對(duì)同一目錄的并行操作。比如,可以再同一個(gè)目錄下同時(shí)創(chuàng)建多個(gè)文件:每一個(gè)操作都獲取一個(gè)目錄名的上的讀取鎖和文件名上的寫(xiě)入鎖。目錄名的讀取鎖足以的防止目錄被刪除、改名以及被快照。文件名的寫(xiě)入鎖序列化文件創(chuàng)建操作,確保不會(huì)多次創(chuàng)建同名的文件。
因?yàn)槊Q(chēng)空間可能有很多節(jié)點(diǎn),讀寫(xiě)鎖采用惰性分配策略,在不再使用的時(shí)候立刻被刪除。同樣,鎖的獲取也要依據(jù)一個(gè)全局一致的順序來(lái)避免死鎖:首先按名稱(chēng)空間的層次排序,在同一個(gè)層次內(nèi)按字典順序排序。
4.2 副本的位置
GFS集群是高度分布的多層布局結(jié)構(gòu),而不是平面結(jié)構(gòu)。典型的拓?fù)浣Y(jié)構(gòu)是有數(shù)百個(gè)Chunk服務(wù)器安裝在許多機(jī)架上。Chunk服務(wù)器被來(lái)自同一或者不同機(jī)架上的數(shù)百個(gè)客戶(hù)機(jī)輪流訪問(wèn)。不同機(jī)架上的兩臺(tái)機(jī)器間的通訊可能跨越一個(gè)或多個(gè)網(wǎng)絡(luò)交換機(jī)。另外,機(jī)架的出入帶寬可能比機(jī)架內(nèi)所有機(jī)器加和在一起的帶寬要小。多層分布架構(gòu)對(duì)數(shù)據(jù)的靈活性、可靠性以及可用性方面提出特有的挑戰(zhàn)。
Chunk副本位置選擇的策略服務(wù)兩大目標(biāo):最大化數(shù)據(jù)可靠性和可用性,最大化網(wǎng)絡(luò)帶寬利用率。為了實(shí)現(xiàn)這兩個(gè)目的,僅僅是在多臺(tái)機(jī)器上分別存儲(chǔ)這些副本是不夠的,這只能預(yù)防硬盤(pán)損壞或者機(jī)器失效帶來(lái)的影響,以及最大化每臺(tái)機(jī)器的網(wǎng)絡(luò)帶寬利用率。我們必須在多個(gè)機(jī)架間分布儲(chǔ)存Chunk的副本。這保證Chunk的一些副本在整個(gè)機(jī)架被破壞或掉線(比如,共享資源,如電源或者網(wǎng)絡(luò)交換機(jī)造成的問(wèn)題)的情況下依然存在且保持可用狀態(tài)。這還意味著在網(wǎng)絡(luò)流量方面,尤其是針對(duì)Chunk的讀操作,能夠有效利用多個(gè)機(jī)架的整合帶寬。另一方面,寫(xiě)操作必須和多個(gè)機(jī)架上的設(shè)備進(jìn)行網(wǎng)絡(luò)通信,但是這個(gè)代價(jià)是我們?cè)敢飧冻龅摹?/p>
4.3 創(chuàng)建,重新復(fù)制,重新負(fù)載均衡
Chunk的副本有三個(gè)用途:Chunk創(chuàng)建,重新復(fù)制和重新負(fù)載均衡。
當(dāng)Master節(jié)點(diǎn)創(chuàng)建一個(gè)Chunk時(shí),它會(huì)選擇在哪里放置初始的空的副本。Master節(jié)點(diǎn)會(huì)考慮幾個(gè)因素。(1)我們希望在低于平均硬盤(pán)使用率的Chunk服務(wù)器上存儲(chǔ)新的副本。這樣的做法最終能夠平衡Chunk服務(wù)器之間的硬盤(pán)使用率。(2)我們希望限制在每個(gè)Chunk服務(wù)器上”最近”的Chunk創(chuàng)建操作的次數(shù)。雖然創(chuàng)建操作本身是廉價(jià)的,但是創(chuàng)建操作也意味著隨之會(huì)有大量的寫(xiě)入數(shù)據(jù)的操作,因?yàn)镃hunk在Writer真正寫(xiě)入數(shù)據(jù)的時(shí)候才被創(chuàng)建,而在我們的”追加一次,讀取多次”的工作模式下,Chunk一旦寫(xiě)入成功之后就會(huì)變?yōu)橹蛔x的了。(3)如上所述,我們希望把Chunk的副本分布在多個(gè)機(jī)架之間。
當(dāng)Chunk的有效副本數(shù)量少于用戶(hù)指定的復(fù)制因數(shù)的時(shí)候,Master節(jié)點(diǎn)會(huì)重新復(fù)制它。這可能是由幾個(gè)原因引起的:一個(gè)Chunk服務(wù)器不可用了,Chunk服務(wù)器報(bào)告它所存儲(chǔ)的一個(gè)副本損壞了,Chunk服務(wù)器的一個(gè)磁盤(pán)因?yàn)殄e(cuò)誤不可用了,或者Chunk副本的復(fù)制因數(shù)提高了。每個(gè)需要被重新復(fù)制的Chunk都會(huì)根據(jù)幾個(gè)因素進(jìn)行排序。一個(gè)因素是Chunk現(xiàn)有副本數(shù)量和復(fù)制因數(shù)相差多少。例如,丟失兩個(gè)副本的Chunk比丟失一個(gè)副本的Chunk有更高的優(yōu)先級(jí)。另外,我們優(yōu)先重新復(fù)制活躍(live)文件的Chunk而不是最近剛被刪除的文件的Chunk(查看4.4節(jié))。最后,為了最小化失效的Chunk對(duì)正在運(yùn)行的應(yīng)用程序的影響,我們提高會(huì)阻塞客戶(hù)機(jī)程序處理流程的Chunk的優(yōu)先級(jí)。
Master節(jié)點(diǎn)選擇優(yōu)先級(jí)最高的Chunk,然后命令某個(gè)Chunk服務(wù)器直接從可用的副本”克隆”一個(gè)副本出來(lái)。選擇新副本的位置的策略和創(chuàng)建時(shí)類(lèi)似:平衡硬盤(pán)使用率、限制同一臺(tái)Chunk服務(wù)器上的正在進(jìn)行的克隆操作的數(shù)量、在機(jī)架間分布副本。為了防止克隆產(chǎn)生的網(wǎng)絡(luò)流量大大超過(guò)客戶(hù)機(jī)的流量,Master節(jié)點(diǎn)對(duì)整個(gè)集群和每個(gè)Chunk服務(wù)器上的同時(shí)進(jìn)行的克隆操作的數(shù)量都進(jìn)行了限制。另外,Chunk服務(wù)器通過(guò)調(diào)節(jié)它對(duì)源Chunk服務(wù)器讀請(qǐng)求的頻率來(lái)限制它用于克隆操作的帶寬。
最后,Master服務(wù)器周期性地對(duì)副本進(jìn)行重新負(fù)載均衡:它檢查當(dāng)前的副本分布情況,然后移動(dòng)副本以便更好的利用硬盤(pán)空間、更有效的進(jìn)行負(fù)載均衡。而且在這個(gè)過(guò)程中,Master服務(wù)器逐漸的填滿一個(gè)新的Chunk服務(wù)器,而不是在短時(shí)間內(nèi)用新的Chunk填滿它,以至于過(guò)載。新副本的存儲(chǔ)位置選擇策略和上面討論的相同。另外,Master節(jié)點(diǎn)必須選擇哪個(gè)副本要被移走。通常情況,Master節(jié)點(diǎn)移走那些剩余空間低于平均值的Chunk服務(wù)器上的副本,從而平衡系統(tǒng)整體的硬盤(pán)使用率。
4.4 垃圾回收
GFS在文件刪除后不會(huì)立刻回收可用的物理空間。GFS空間回收采用惰性的策略,只在文件和Chunk級(jí)的常規(guī)垃圾收集時(shí)進(jìn)行。我們發(fā)現(xiàn)這個(gè)方法使系統(tǒng)更簡(jiǎn)單、更可靠。
4.4.1 機(jī)制
當(dāng)一個(gè)文件被應(yīng)用程序刪除時(shí),Master節(jié)點(diǎn)象對(duì)待其它修改操作一樣,立刻把刪除操作以日志的方式記錄下來(lái)。但是,Master節(jié)點(diǎn)并不馬上回收資源,而是把文件名改為一個(gè)包含刪除時(shí)間戳的、隱藏的名字。當(dāng)Master節(jié)點(diǎn)對(duì)文件系統(tǒng)命名空間做常規(guī)掃描的時(shí)候,它會(huì)刪除所有三天前的隱藏文件(這個(gè)時(shí)間間隔是可以設(shè)置的)。直到文件被真正刪除,它們?nèi)耘f可以用新的特殊的名字讀取,也可以通過(guò)把隱藏文件改名為正常顯示的文件名的方式“反刪除”。當(dāng)隱藏文件被從名稱(chēng)空間中刪除,Master服務(wù)器內(nèi)存中保存的這個(gè)文件的相關(guān)元數(shù)據(jù)才會(huì)被刪除。這也有效的切斷了文件和它包含的所有Chunk的連接(alex注:原文是This effectively severs its links to all its chunks)。
在對(duì)Chunk名字空間做類(lèi)似的常規(guī)掃描時(shí),Master節(jié)點(diǎn)找到孤兒Chunk(不被任何文件包含的Chunk)并刪除它們的元數(shù)據(jù)。Chunk服務(wù)器在和Master節(jié)點(diǎn)交互的心跳信息中,報(bào)告它擁有的Chunk子集的信息,Master節(jié)點(diǎn)回復(fù)Chunk服務(wù)器哪些Chunk在Master節(jié)點(diǎn)保存的元數(shù)據(jù)中已經(jīng)不存在了。Chunk服務(wù)器可以任意刪除這些Chunk的副本。
4.4.2 討論
雖然分布式垃圾回收在編程語(yǔ)言領(lǐng)域是一個(gè)需要復(fù)雜的方案才能解決的難題,但是在GFS系統(tǒng)中是非常簡(jiǎn)單的。我們可以輕易的得到Chunk的所有引用:它們都只存儲(chǔ)在Master服務(wù)器上的文件到塊的映射表中。我們也可以很輕易的得到所有Chunk的副本:它們都以Linux文件的形式存儲(chǔ)在Chunk服務(wù)器的指定目錄下。所有Master節(jié)點(diǎn)不能識(shí)別的副本都是”垃圾”。
垃圾回收在空間回收方面相比直接刪除有幾個(gè)優(yōu)勢(shì)。首先,對(duì)于組件失效是常態(tài)的大規(guī)模分布式系統(tǒng),垃圾回收方式簡(jiǎn)單可靠。Chunk可能在某些Chunk服務(wù)器創(chuàng)建成功,某些Chunk服務(wù)器上創(chuàng)建失敗,失敗的副本處于無(wú)法被Master節(jié)點(diǎn)識(shí)別的狀態(tài)。副本刪除消息可能丟失,Master節(jié)點(diǎn)必須重新發(fā)送失敗的刪除消息,包括自身的和Chunk服務(wù)器的(alex注:自身的指刪除metadata的消息)。垃圾回收提供了一致的、可靠的清除無(wú)用副本的方法。第二,垃圾回收把存儲(chǔ)空間的回收操作合并到Master節(jié)點(diǎn)規(guī)律性的后臺(tái)活動(dòng)中,比如,例行掃描和與Chunk服務(wù)器握手等。因此,操作被批量的執(zhí)行,開(kāi)銷(xiāo)會(huì)被分散。另外,垃圾回收在Master節(jié)點(diǎn)相對(duì)空閑的時(shí)候完成。這樣Master節(jié)點(diǎn)就可以給那些需要快速反應(yīng)的客戶(hù)機(jī)請(qǐng)求提供更快捷的響應(yīng)。第三,延緩存儲(chǔ)空間回收為意外的、不可逆轉(zhuǎn)的刪除操作提供了安全保障。
根據(jù)我們的使用經(jīng)驗(yàn),延遲回收空間的主要問(wèn)題是,延遲回收會(huì)阻礙用戶(hù)調(diào)優(yōu)存儲(chǔ)空間的使用,特別是當(dāng)存儲(chǔ)空間比較緊缺的時(shí)候。當(dāng)應(yīng)用程序重復(fù)創(chuàng)建和刪除臨時(shí)文件時(shí),釋放的存儲(chǔ)空間不能馬上重用。我們通過(guò)顯式的再次刪除一個(gè)已經(jīng)被刪除的文件的方式加速空間回收的速度。我們?cè)试S用戶(hù)為命名空間的不同部分設(shè)定不同的復(fù)制和回收策略。例如,用戶(hù)可以指定某些目錄樹(shù)下面的文件不做復(fù)制,刪除的文件被即時(shí)的、不可恢復(fù)的從文件系統(tǒng)移除。
4.5 過(guò)期失效的副本檢測(cè)
當(dāng)Chunk服務(wù)器失效時(shí),Chunk的副本有可能因錯(cuò)失了一些修改操作而過(guò)期失效。Master節(jié)點(diǎn)保存了每個(gè)Chunk的版本號(hào),用來(lái)區(qū)分當(dāng)前的副本和過(guò)期副本。
無(wú)論何時(shí),只要Master節(jié)點(diǎn)和Chunk簽訂一個(gè)新的租約,它就增加Chunk的版本號(hào),然后通知最新的副本。Master節(jié)點(diǎn)和這些副本都把新的版本號(hào)記錄在它們持久化存儲(chǔ)的狀態(tài)信息中。這個(gè)動(dòng)作發(fā)生在任何客戶(hù)機(jī)得到通知以前,因此也是對(duì)這個(gè)Chunk開(kāi)始寫(xiě)之前。如果某個(gè)副本所在的Chunk服務(wù)器正好處于失效狀態(tài),那么副本的版本號(hào)就不會(huì)被增加。Master節(jié)點(diǎn)在這個(gè)Chunk服務(wù)器重新啟動(dòng),并且向Master節(jié)點(diǎn)報(bào)告它擁有的Chunk的集合以及相應(yīng)的版本號(hào)的時(shí)候,就會(huì)檢測(cè)出它包含過(guò)期的Chunk。如果Master節(jié)點(diǎn)看到一個(gè)比它記錄的版本號(hào)更高的版本號(hào),Master節(jié)點(diǎn)會(huì)認(rèn)為它和Chunk服務(wù)器簽訂租約的操作失敗了,因此會(huì)選擇更高的版本號(hào)作為當(dāng)前的版本號(hào)。
Master節(jié)點(diǎn)在例行的垃圾回收過(guò)程中移除所有的過(guò)期失效副本。在此之前,Master節(jié)點(diǎn)在回復(fù)客戶(hù)機(jī)的Chunk信息請(qǐng)求的時(shí)候,簡(jiǎn)單的認(rèn)為那些過(guò)期的塊根本就不存在。另外一重保障措施是,Master節(jié)點(diǎn)在通知客戶(hù)機(jī)哪個(gè)Chunk服務(wù)器持有租約、或者指示Chunk服務(wù)器從哪個(gè)Chunk服務(wù)器進(jìn)行克隆時(shí),消息中都附帶了Chunk的版本號(hào)。客戶(hù)機(jī)或者Chunk服務(wù)器在執(zhí)行操作時(shí)都會(huì)驗(yàn)證版本號(hào)以確保總是訪問(wèn)當(dāng)前版本的數(shù)據(jù)。
#p#
5. 容錯(cuò)和診斷
我們?cè)谠O(shè)計(jì)GFS時(shí)遇到的最大挑戰(zhàn)之一是如何處理頻繁發(fā)生的組件失效。組件的數(shù)量和質(zhì)量讓這些問(wèn)題出現(xiàn)的頻率遠(yuǎn)遠(yuǎn)超過(guò)一般系統(tǒng)意外發(fā)生的頻率:我們不能完全依賴(lài)機(jī)器的穩(wěn)定性,也不能完全相信硬盤(pán)的可靠性。組件的失效可能造成系統(tǒng)不可用,更糟糕的是,還可能產(chǎn)生不完整的數(shù)據(jù)。我們討論我們?nèi)绾蚊鎸?duì)這些挑戰(zhàn),以及當(dāng)組件失效不可避免的發(fā)生時(shí),用GFS自帶工具診斷系統(tǒng)故障。
5.1 高可用性
在GFS集群的數(shù)百個(gè)服務(wù)器之中,在任何給定的時(shí)間必定會(huì)有些服務(wù)器是不可用的。我們使用兩條簡(jiǎn)單但是有效的策略保證整個(gè)系統(tǒng)的高可用性:快速恢復(fù)和復(fù)制。
5.1.1 快速恢復(fù)
不管Master服務(wù)器和Chunk服務(wù)器是如何關(guān)閉的,它們都被設(shè)計(jì)為可以在數(shù)秒鐘內(nèi)恢復(fù)它們的狀態(tài)并重新啟動(dòng)。事實(shí)上,我們并不區(qū)分正常關(guān)閉和異常關(guān)閉;通常,我們通過(guò)直接kill掉進(jìn)程來(lái)關(guān)閉服務(wù)器。客戶(hù)機(jī)和其它的服務(wù)器會(huì)感覺(jué)到系統(tǒng)有點(diǎn)顛簸(alex注:a minor hiccup),正在發(fā)出的請(qǐng)求會(huì)超時(shí),需要重新連接到重啟后的服務(wù)器,然后重試這個(gè)請(qǐng)求。6.6.2章節(jié)記錄了實(shí)測(cè)的啟動(dòng)時(shí)間。
5.1.2 Chunk復(fù)制
正如之前討論的,每個(gè)Chunk都被復(fù)制到不同機(jī)架上的不同的Chunk服務(wù)器上。用戶(hù)可以為文件命名空間的不同部分設(shè)定不同的復(fù)制級(jí)別。缺省是3。當(dāng)有Chunk服務(wù)器離線了,或者通過(guò)Chksum校驗(yàn)(參考5.2節(jié))發(fā)現(xiàn)了已經(jīng)損壞的數(shù)據(jù),Master節(jié)點(diǎn)通過(guò)克隆已有的副本保證每個(gè)Chunk都被完整復(fù)制(alex注:即每個(gè)Chunk都有復(fù)制因子制定的個(gè)數(shù)個(gè)副本,缺省是3)。雖然Chunk復(fù)制策略對(duì)我們非常有效,但是我們也在尋找其它形式的跨服務(wù)器的冗余解決方案,比如使用奇偶校驗(yàn)、或者Erasure codes(alex注:Erasure codes用來(lái)解決鏈接層中不相關(guān)的錯(cuò)誤,以及網(wǎng)絡(luò)擁塞和buffer限制造成的丟包錯(cuò)誤)來(lái)解決我們?nèi)找嬖鲩L(zhǎng)的只讀存儲(chǔ)需求。我們的系統(tǒng)主要的工作負(fù)載是追加方式的寫(xiě)入和讀取操作,很少有隨機(jī)的寫(xiě)入操作,因此,我們認(rèn)為在我們這個(gè)高度解耦合的系統(tǒng)架構(gòu)下實(shí)現(xiàn)這些復(fù)雜的冗余方案很有挑戰(zhàn)性,但并非不可實(shí)現(xiàn)。
5.1.3 Master服務(wù)器的復(fù)制
為了保證Master服務(wù)器的可靠性,Master服務(wù)器的狀態(tài)也要復(fù)制。Master服務(wù)器所有的操作日志和checkpoint文件都被復(fù)制到多臺(tái)機(jī)器上。對(duì)Master服務(wù)器狀態(tài)的修改操作能夠提交成功的前提是,操作日志寫(xiě)入到Master服務(wù)器的備節(jié)點(diǎn)和本機(jī)的磁盤(pán)。簡(jiǎn)單說(shuō)來(lái),一個(gè)Master服務(wù)進(jìn)程負(fù)責(zé)所有的修改操作,包括后臺(tái)的服務(wù),比如垃圾回收等改變系統(tǒng)內(nèi)部狀態(tài)活動(dòng)。當(dāng)它失效的時(shí),幾乎可以立刻重新啟動(dòng)。如果Master進(jìn)程所在的機(jī)器或者磁盤(pán)失效了,處于GFS系統(tǒng)外部的監(jiān)控進(jìn)程會(huì)在其它的存有完整操作日志的機(jī)器上啟動(dòng)一個(gè)新的Master進(jìn)程。客戶(hù)端使用規(guī)范的名字訪問(wèn)Master(比如gfs-test)節(jié)點(diǎn),這個(gè)名字類(lèi)似DNS別名,因此也就可以在Master進(jìn)程轉(zhuǎn)到別的機(jī)器上執(zhí)行時(shí),通過(guò)更改別名的實(shí)際指向訪問(wèn)新的Master節(jié)點(diǎn)。
此外,GFS中還有些“影子”Master服務(wù)器,這些“影子”服務(wù)器在“主”Master服務(wù)器宕機(jī)的時(shí)候提供文件系統(tǒng)的只讀訪問(wèn)。它們是影子,而不是鏡像,所以它們的數(shù)據(jù)可能比“主”Master服務(wù)器更新要慢,通常是不到1秒。對(duì)于那些不經(jīng)常改變的文件、或者那些允許獲取的數(shù)據(jù)有少量過(guò)期的應(yīng)用程序,“影子”Master服務(wù)器能夠提高讀取的效率。事實(shí)上,因?yàn)槲募?nèi)容是從Chunk服務(wù)器上讀取的,因此,應(yīng)用程序不會(huì)發(fā)現(xiàn)過(guò)期的文件內(nèi)容。在這個(gè)短暫的時(shí)間窗內(nèi),過(guò)期的可能是文件的元數(shù)據(jù),比如目錄的內(nèi)容或者訪問(wèn)控制信息。
“影子”Master服務(wù)器為了保持自身狀態(tài)是最新的,它會(huì)讀取一份當(dāng)前正在進(jìn)行的操作的日志副本,并且依照和主Master服務(wù)器完全相同的順序來(lái)更改內(nèi)部的數(shù)據(jù)結(jié)構(gòu)。和主Master服務(wù)器一樣,“影子”Master服務(wù)器在啟動(dòng)的時(shí)候也會(huì)從Chunk服務(wù)器輪詢(xún)數(shù)據(jù)(之后定期拉數(shù)據(jù)),數(shù)據(jù)中包括了Chunk副本的位置信息;“影子”Master服務(wù)器也會(huì)定期和Chunk服務(wù)器“握手”來(lái)確定它們的狀態(tài)。在主Master服務(wù)器因創(chuàng)建和刪除副本導(dǎo)致副本位置信息更新時(shí),“影子”Master服務(wù)器才和主Master服務(wù)器通信來(lái)更新自身狀態(tài)。
5.2 數(shù)據(jù)完整性
每個(gè)Chunk服務(wù)器都使用Checksum來(lái)檢查保存的數(shù)據(jù)是否損壞。考慮到一個(gè)GFS集群通常都有好幾百臺(tái)機(jī)器、幾千塊硬盤(pán),磁盤(pán)損壞導(dǎo)致數(shù)據(jù)在讀寫(xiě)過(guò)程中損壞或者丟失是非常常見(jiàn)的(第7節(jié)講了一個(gè)原因)。我們可以通過(guò)別的Chunk副本來(lái)解決數(shù)據(jù)損壞問(wèn)題,但是跨越Chunk服務(wù)器比較副本來(lái)檢查數(shù)據(jù)是否損壞很不實(shí)際。另外,GFS允許有歧義的副本存在:GFS修改操作的語(yǔ)義,特別是早先討論過(guò)的原子紀(jì)錄追加的操作,并不保證副本完全相同(alex注:副本不是byte-wise完全一致的)。因此,每個(gè)Chunk服務(wù)器必須獨(dú)立維護(hù)Checksum來(lái)校驗(yàn)自己的副本的完整性。
我們把每個(gè)Chunk都分成64KB大小的塊。每個(gè)塊都對(duì)應(yīng)一個(gè)32位的Checksum。和其它元數(shù)據(jù)一樣,Checksum與其它的用戶(hù)數(shù)據(jù)是分開(kāi)的,并且保存在內(nèi)存和硬盤(pán)上,同時(shí)也記錄操作日志。
對(duì)于讀操作來(lái)說(shuō),在把數(shù)據(jù)返回給客戶(hù)端或者其它的Chunk服務(wù)器之前,Chunk服務(wù)器會(huì)校驗(yàn)讀取操作涉及的范圍內(nèi)的塊的Checksum。因此Chunk服務(wù)器不會(huì)把錯(cuò)誤數(shù)據(jù)傳遞到其它的機(jī)器上。如果發(fā)生某個(gè)塊的Checksum不正確,Chunk服務(wù)器返回給請(qǐng)求者一個(gè)錯(cuò)誤信息,并且通知Master服務(wù)器這個(gè)錯(cuò)誤。作為回應(yīng),請(qǐng)求者應(yīng)當(dāng)從其它副本讀取數(shù)據(jù),Master服務(wù)器也會(huì)從其它副本克隆數(shù)據(jù)進(jìn)行恢復(fù)。當(dāng)一個(gè)新的副本就緒后,Master服務(wù)器通知副本錯(cuò)誤的Chunk服務(wù)器刪掉錯(cuò)誤的副本。
Checksum對(duì)讀操作的性能影響很小,可以基于幾個(gè)原因來(lái)分析一下。因?yàn)榇蟛糠值淖x操作都至少要讀取幾個(gè)塊,而我們只需要讀取一小部分額外的相關(guān)數(shù)據(jù)進(jìn)行校驗(yàn)。GFS客戶(hù)端代碼通過(guò)每次把讀取操作都對(duì)齊在Checksum block的邊界上,進(jìn)一步減少了這些額外的讀取操作的負(fù)面影響。另外,在Chunk服務(wù)器上,Chunksum的查找和比較不需要I/O操作,Checksum的計(jì)算可以和I/O操作同時(shí)進(jìn)行。
Checksum的計(jì)算針對(duì)在Chunk尾部的追加寫(xiě)入操作作了高度優(yōu)化(與之對(duì)應(yīng)的是覆蓋現(xiàn)有數(shù)據(jù)的寫(xiě)入操作),因?yàn)檫@類(lèi)操作在我們的工作中占了很大比例。我們只增量更新最后一個(gè)不完整的塊的Checksum,并且用所有的追加來(lái)的新Checksum塊來(lái)計(jì)算新的Checksum。即使是最后一個(gè)不完整的Checksum塊已經(jīng)損壞了,而且我們不能夠馬上檢查出來(lái),由于新的Checksum和已有數(shù)據(jù)不吻合,在下次對(duì)這個(gè)塊進(jìn)行讀取操作的時(shí)候,會(huì)檢查出數(shù)據(jù)已經(jīng)損壞了。
相比之下,如果寫(xiě)操作覆蓋已經(jīng)存在的一個(gè)范圍內(nèi)的Chunk,我們必須讀取和校驗(yàn)被覆蓋的第一個(gè)和最后一個(gè)塊,然后再執(zhí)行寫(xiě)操作;操作完成之后再重新計(jì)算和寫(xiě)入新的Checksum。如果我們不校驗(yàn)第一個(gè)和最后一個(gè)被寫(xiě)的塊,那么新的Checksum可能會(huì)隱藏沒(méi)有被覆蓋區(qū)域內(nèi)的數(shù)據(jù)錯(cuò)誤。
在Chunk服務(wù)器空閑的時(shí)候,它會(huì)掃描和校驗(yàn)每個(gè)不活動(dòng)的Chunk的內(nèi)容。這使得我們能夠發(fā)現(xiàn)很少被讀取的Chunk是否完整。一旦發(fā)現(xiàn)有Chunk的數(shù)據(jù)損壞,Master可以創(chuàng)建一個(gè)新的、正確的副本,然后把損壞的副本刪除掉。這個(gè)機(jī)制也避免了非活動(dòng)的、已損壞的Chunk欺騙Master節(jié)點(diǎn),使Master節(jié)點(diǎn)認(rèn)為它們已經(jīng)有了足夠多的副本了。
5.3 診斷工具
詳盡的、深入細(xì)節(jié)的診斷日志,在問(wèn)題隔離、調(diào)試、以及性能分析等方面給我們帶來(lái)無(wú)法估量的幫助,同時(shí)也只需要很小的開(kāi)銷(xiāo)。沒(méi)有日志的幫助,我們很難理解短暫的、不重復(fù)的機(jī)器之間的消息交互。GFS的服務(wù)器會(huì)產(chǎn)生大量的日志,記錄了大量關(guān)鍵的事件(比如,Chunk服務(wù)器啟動(dòng)和關(guān)閉)以及所有的RPC的請(qǐng)求和回復(fù)。這些診斷日志可以隨意刪除,對(duì)系統(tǒng)的正確運(yùn)行不造成任何影響。然而,我們?cè)诖鎯?chǔ)空間允許的情況下會(huì)盡量的保存這些日志。
RPC日志包含了網(wǎng)絡(luò)上發(fā)生的所有請(qǐng)求和響應(yīng)的詳細(xì)記錄,但是不包括讀寫(xiě)的文件數(shù)據(jù)。通過(guò)匹配請(qǐng)求與回應(yīng),以及收集不同機(jī)器上的RPC日志記錄,我們可以重演所有的消息交互來(lái)診斷問(wèn)題。日志還用來(lái)跟蹤負(fù)載測(cè)試和性能分析。
日志對(duì)性能的影響很小(遠(yuǎn)小于它帶來(lái)的好處),因?yàn)檫@些日志的寫(xiě)入方式是順序的、異步的。最近發(fā)生的事件日志保存在內(nèi)存中,可用于持續(xù)不斷的在線監(jiān)控。
#p#
6. 度量
本節(jié)中,我們將使用一些小規(guī)模基準(zhǔn)測(cè)試來(lái)展現(xiàn)GFS系統(tǒng)架構(gòu)和實(shí)現(xiàn)上的一些固有瓶頸,還有些來(lái)自Google內(nèi)部使用的真實(shí)的GFS集群的基準(zhǔn)數(shù)據(jù)。
6.1 小規(guī)模基準(zhǔn)測(cè)試
我們?cè)谝粋€(gè)包含1臺(tái)Master服務(wù)器,2臺(tái)Master服務(wù)器復(fù)制節(jié)點(diǎn),16臺(tái)Chunk服務(wù)器和16個(gè)客戶(hù)機(jī)組成的GFS集群上測(cè)量性能。注意,采用這樣的集群配置方案只是為了易于測(cè)試。典型的GFS集群有數(shù)百個(gè)Chunk服務(wù)器和數(shù)百個(gè)客戶(hù)機(jī)。
所有機(jī)器的配置都一樣:兩個(gè)PIII 1.4GHz處理器,2GB內(nèi)存,兩個(gè)80G/5400rpm的硬盤(pán),以及100Mbps全雙工以太網(wǎng)連接到一個(gè)HP2524交換機(jī)。GFS集群中所有的19臺(tái)服務(wù)器都連接在一個(gè)交換機(jī),所有16臺(tái)客戶(hù)機(jī)連接到另一個(gè)交換機(jī)上。兩個(gè)交換機(jī)之間使用1Gbps的線路連接。
6.1.1 讀取
N個(gè)客戶(hù)機(jī)從GFS文件系統(tǒng)同步讀取數(shù)據(jù)。每個(gè)客戶(hù)機(jī)從320GB的文件集合中隨機(jī)讀取4MB region的內(nèi)容。讀取操作重復(fù)執(zhí)行256次,因此,每個(gè)客戶(hù)機(jī)最終都讀取1GB的數(shù)據(jù)。所有的Chunk服務(wù)器加起來(lái)總共只有32GB的內(nèi)存,因此,我們預(yù)期只有最多10%的讀取請(qǐng)求命中Linux的文件系統(tǒng)緩沖。我們的測(cè)試結(jié)果應(yīng)該和一個(gè)在沒(méi)有文件系統(tǒng)緩存的情況下讀取測(cè)試的結(jié)果接近。

圖三:合計(jì)吞吐量:上邊的曲線顯示了我們網(wǎng)絡(luò)拓?fù)湎碌暮嫌?jì)理論吞吐量上限。下邊的曲線顯示了觀測(cè)到的吞吐量。這個(gè)曲線有著95%的可靠性,因?yàn)橛袝r(shí)候測(cè)量會(huì)不夠精確。
圖3(a)顯示了N個(gè)客戶(hù)機(jī)整體的讀取速度以及這個(gè)速度的理論極限。當(dāng)連接兩個(gè)交換機(jī)的1Gbps的鏈路飽和時(shí),整體讀取速度達(dá)到理論的極限值是125MB/S,或者說(shuō)每個(gè)客戶(hù)機(jī)配置的100Mbps網(wǎng)卡達(dá)到飽和時(shí),每個(gè)客戶(hù)機(jī)讀取速度的理論極限值是12.5MB/s。實(shí)測(cè)結(jié)果是,當(dāng)一個(gè)客戶(hù)機(jī)讀取的時(shí)候,讀取的速度是10MB/s,也就是說(shuō)達(dá)到客戶(hù)機(jī)理論讀取速度極限值的80%。對(duì)于16個(gè)客戶(hù)機(jī),整體的讀取速度達(dá)到了94MB/s,大約是理論整體讀取速度極限值的75%,也就是說(shuō)每個(gè)客戶(hù)機(jī)的讀取速度是6MB/s。讀取效率從80%降低到了75%,主要的原因是當(dāng)讀取的客戶(hù)機(jī)增加時(shí),多個(gè)客戶(hù)機(jī)同時(shí)讀取一個(gè)Chunk服務(wù)器的幾率也增加了,導(dǎo)致整體的讀取效率下降。
6.1.2 寫(xiě)入
N個(gè)客戶(hù)機(jī)同時(shí)向N個(gè)不同的文件中寫(xiě)入數(shù)據(jù)。每個(gè)客戶(hù)機(jī)以每次1MB的速度連續(xù)寫(xiě)入1GB的數(shù)據(jù)。圖3(b)顯示了整體的寫(xiě)入速度和它們理論上的極限值。理論上的極限值是67MB/s,因?yàn)槲覀冃枰衙恳籦yte寫(xiě)入到16個(gè)Chunk服務(wù)器中的3個(gè)上,而每個(gè)Chunk服務(wù)器的輸入連接速度是12.5MB/s。
一個(gè)客戶(hù)機(jī)的寫(xiě)入速度是6.3MB,大概是理論極限值的一半。導(dǎo)致這個(gè)結(jié)果的主要原因是我們的網(wǎng)絡(luò)協(xié)議棧。它與我們推送數(shù)據(jù)到Chunk服務(wù)器時(shí)采用的管道模式不相適應(yīng)。從一個(gè)副本到另一個(gè)副本的數(shù)據(jù)傳輸延遲降低了整個(gè)的寫(xiě)入速度。
16個(gè)客戶(hù)機(jī)整體的寫(xiě)入速度達(dá)到了35MB/s(即每個(gè)客戶(hù)機(jī)2.2MB/s),大約只是理論極限值的一半。和多個(gè)客戶(hù)機(jī)讀取的情形很類(lèi)型,隨著客戶(hù)機(jī)數(shù)量的增加,多個(gè)客戶(hù)機(jī)同時(shí)寫(xiě)入同一個(gè)Chunk服務(wù)器的幾率也增加了。而且,16個(gè)客戶(hù)機(jī)并行寫(xiě)入可能引起的沖突比16個(gè)客戶(hù)機(jī)并行讀取要大得多,因?yàn)槊總€(gè)寫(xiě)入都會(huì)涉及三個(gè)不同的副本。
寫(xiě)入的速度比我們想象的要慢。在實(shí)際應(yīng)用中,這沒(méi)有成為我們的主要問(wèn)題,因?yàn)榧词乖趩蝹€(gè)客戶(hù)機(jī)上能夠感受到延時(shí),它也不會(huì)在有大量客戶(hù)機(jī)的時(shí)候?qū)φw的寫(xiě)入帶寬造成顯著的影響。
6.1.3 記錄追加
圖3(c)顯示了記錄追加操作的性能。N個(gè)客戶(hù)機(jī)同時(shí)追加數(shù)據(jù)到一個(gè)文件。記錄追加操作的性能受限于保存文件最后一個(gè)Chunk的Chunk服務(wù)器的帶寬,而與客戶(hù)機(jī)的數(shù)量無(wú)關(guān)。記錄追加的速度由一個(gè)客戶(hù)機(jī)的6.0MB/s開(kāi)始,下降到16個(gè)客戶(hù)機(jī)的4.8MB/s為止,速度的下降主要是由于不同客戶(hù)端的網(wǎng)絡(luò)擁塞以及網(wǎng)絡(luò)傳輸速度的不同而導(dǎo)致的。
我們的程序傾向于同時(shí)處理多個(gè)這樣的文件。換句話說(shuō),即N個(gè)客戶(hù)機(jī)同時(shí)追加數(shù)據(jù)到M個(gè)共享文件中,這里N和M都是數(shù)十或者數(shù)百以上。所以,在我們的實(shí)際應(yīng)用中,Chunk服務(wù)器的網(wǎng)絡(luò)擁塞并沒(méi)有成為一個(gè)嚴(yán)重問(wèn)題,如果Chunk服務(wù)器的某個(gè)文件正在寫(xiě)入,客戶(hù)機(jī)會(huì)去寫(xiě)另外一個(gè)文件。
6.2 實(shí)際應(yīng)用中的集群
我們現(xiàn)在來(lái)仔細(xì)評(píng)估一下Google內(nèi)部正在使用的兩個(gè)集群,它們具有一定的代表性。集群A通常被上百個(gè)工程師用于研究和開(kāi)發(fā)。典型的任務(wù)是被人工初始化后連續(xù)運(yùn)行數(shù)個(gè)小時(shí)。它通常讀取數(shù)MB到數(shù)TB的數(shù)據(jù),之后進(jìn)行轉(zhuǎn)化或者分析,最后把結(jié)果寫(xiě)回到集群中。集群B主要用于處理當(dāng)前的生產(chǎn)數(shù)據(jù)。集群B的任務(wù)持續(xù)的時(shí)間更長(zhǎng),在很少人工干預(yù)的情況下,持續(xù)的生成和處理數(shù)TB的數(shù)據(jù)集。在這兩個(gè)案例中,一個(gè)單獨(dú)的”任務(wù)”都是指運(yùn)行在多個(gè)機(jī)器上的多個(gè)進(jìn)程,它們同時(shí)讀取和寫(xiě)入多個(gè)文件。

6.2.1 存儲(chǔ)
如上表前五行所描述的,兩個(gè)集群都由上百臺(tái)Chunk服務(wù)器組成,支持?jǐn)?shù)TB的硬盤(pán)空間;兩個(gè)集群雖然都存儲(chǔ)了大量的數(shù)據(jù),但是還有剩余的空間。“已用空間”包含了所有的Chunk副本。實(shí)際上所有的文件都復(fù)制了三份。因此,集群實(shí)際上各存儲(chǔ)了18TB和52TB的文件數(shù)據(jù)。
兩個(gè)集群存儲(chǔ)的文件數(shù)量都差不多,但是集群B上有大量的死文件。所謂“死文件”是指文件被刪除了或者是被新版本的文件替換了,但是存儲(chǔ)空間還沒(méi)有來(lái)得及被回收。由于集群B存儲(chǔ)的文件較大,因此它的Chunk數(shù)量也比較多。
6.2.2 元數(shù)據(jù)
Chunk服務(wù)器總共保存了十幾GB的元數(shù)據(jù),大多數(shù)是來(lái)自用戶(hù)數(shù)據(jù)的、64KB大小的塊的Checksum。保存在Chunk服務(wù)器上其它的元數(shù)據(jù)是Chunk的版本號(hào)信息,我們?cè)?.5節(jié)描述過(guò)。
在Master服務(wù)器上保存的元數(shù)據(jù)就小的多了,大約只有數(shù)十MB,或者說(shuō)平均每個(gè)文件100字節(jié)的元數(shù)據(jù)。這和我們?cè)O(shè)想的是一樣的,Master服務(wù)器的內(nèi)存大小在實(shí)際應(yīng)用中并不會(huì)成為GFS系統(tǒng)容量的瓶頸。大多數(shù)文件的元數(shù)據(jù)都是以前綴壓縮模式存放的文件名。Master服務(wù)器上存放的其它元數(shù)據(jù)包括了文件的所有者和權(quán)限、文件到Chunk的映射關(guān)系,以及每一個(gè)Chunk的當(dāng)前版本號(hào)。此外,針對(duì)每一個(gè)Chunk,我們都保存了當(dāng)前的副本位置以及對(duì)它的引用計(jì)數(shù),這個(gè)引用計(jì)數(shù)用于實(shí)現(xiàn)寫(xiě)時(shí)拷貝(alex注:即COW,copy-on-write)。
對(duì)于每一個(gè)單獨(dú)的服務(wù)器,無(wú)論是Chunk服務(wù)器還是Master服務(wù)器,都只保存了50MB到100MB的元數(shù)據(jù)。因此,恢復(fù)服務(wù)器是非常快速的:在服務(wù)器響應(yīng)客戶(hù)請(qǐng)求之前,只需要花幾秒鐘時(shí)間從磁盤(pán)上讀取這些數(shù)據(jù)就可以了。不過(guò),Master服務(wù)器會(huì)持續(xù)顛簸一段時(shí)間–通常是30到60秒–直到它完成輪詢(xún)所有的Chunk服務(wù)器,并獲取到所有Chunk的位置信息。
6.2.3 讀寫(xiě)速率

表三顯示了不同時(shí)段的讀寫(xiě)速率。在測(cè)試的時(shí)候,這兩個(gè)集群都運(yùn)行了一周左右的時(shí)間。(這兩個(gè)集群最近都因?yàn)樯?jí)新版本的GFS重新啟動(dòng)過(guò)了)。
集群重新啟動(dòng)后,平均寫(xiě)入速率小于30MB/s。當(dāng)我們提取性能數(shù)據(jù)的時(shí)候,集群B正進(jìn)行大量的寫(xiě)入操作,寫(xiě)入速度達(dá)到了100MB/s,并且因?yàn)槊總€(gè)Chunk都有三個(gè)副本的原因,網(wǎng)絡(luò)負(fù)載達(dá)到了300MB/s。
讀取速率要比寫(xiě)入速率高的多。正如我們?cè)O(shè)想的那樣,總的工作負(fù)載中,讀取的比例遠(yuǎn)遠(yuǎn)高于寫(xiě)入的比例。兩個(gè)集群都進(jìn)行著繁重的讀取操作。特別是,集群A在一周時(shí)間內(nèi)都維持了580MB/s的讀取速度。集群A的網(wǎng)絡(luò)配置可以支持750MB/s的速度,顯然,它有效的利用了資源。集群B支持的峰值讀取速度是1300MB/s,但是它的應(yīng)用只用到了380MB/s。
6.2.4 Master服務(wù)器的負(fù)載
表3的數(shù)據(jù)顯示了發(fā)送到Master服務(wù)器的操作請(qǐng)求大概是每秒鐘200到500個(gè)。Master服務(wù)器可以輕松的應(yīng)付這個(gè)請(qǐng)求速度,所以Master服務(wù)器的處理能力不是系統(tǒng)的瓶頸。
在早期版本的GFS中,Master服務(wù)器偶爾會(huì)成為瓶頸。它大多數(shù)時(shí)間里都在順序掃描某個(gè)很大的目錄(包含數(shù)萬(wàn)個(gè)文件)去查找某個(gè)特定的文件。因此我們修改了Master服務(wù)器的數(shù)據(jù)結(jié)構(gòu),通過(guò)對(duì)名字空間進(jìn)行二分查找來(lái)提高效率。現(xiàn)在Master服務(wù)器可以輕松的每秒鐘進(jìn)行數(shù)千次文件訪問(wèn)。如果有需要的話,我們可以通過(guò)在名稱(chēng)空間數(shù)據(jù)結(jié)構(gòu)之前設(shè)置名稱(chēng)查詢(xún)緩沖的方式進(jìn)一步提高速度。
6.2.5 恢復(fù)時(shí)間
當(dāng)某個(gè)Chunk服務(wù)器失效了,一些Chunk副本的數(shù)量可能會(huì)低于復(fù)制因子指定的數(shù)量,我們必須通過(guò)克隆副本使Chunk副本數(shù)量達(dá)到復(fù)制因子指定的數(shù)量。恢復(fù)所有Chunk副本所花費(fèi)的時(shí)間取決于資源的數(shù)量。在我們的試驗(yàn)中,我們把集群B上的一個(gè)Chunk服務(wù)器Kill掉。這個(gè)Chunk服務(wù)器上大約有15000個(gè)Chunk,共計(jì)600GB的數(shù)據(jù)。為了減小克隆操作對(duì)正在運(yùn)行的應(yīng)用程序的影響,以及為GFS調(diào)度決策提供修正空間,我們?nèi)笔〉陌鸭褐胁l(fā)克隆操作的數(shù)量設(shè)置為91個(gè)(Chunk服務(wù)器的數(shù)量的40%),每個(gè)克隆操作最多允許使用的帶寬是6.25MB/s(50mbps)。所有的Chunk在23.2分鐘內(nèi)恢復(fù)了,復(fù)制的速度高達(dá)440MB/s。
在另外一個(gè)測(cè)試中,我們Kill掉了兩個(gè)Chunk服務(wù)器,每個(gè)Chunk服務(wù)器大約有16000個(gè)Chunk,共計(jì)660GB的數(shù)據(jù)。這兩個(gè)故障導(dǎo)致了266個(gè)Chunk只有單個(gè)副本。這266個(gè)Chunk被GFS優(yōu)先調(diào)度進(jìn)行復(fù)制,在2分鐘內(nèi)恢復(fù)到至少有兩個(gè)副本;現(xiàn)在集群被帶入到另外一個(gè)狀態(tài),在這個(gè)狀態(tài)下,系統(tǒng)可以容忍另外一個(gè)Chunk服務(wù)器失效而不丟失數(shù)據(jù)。
6.3 工作負(fù)荷分析(Workload Breakdown)
本節(jié)中,我們展示了對(duì)兩個(gè)GFS集群工作負(fù)載情況的詳細(xì)分析,這兩個(gè)集群和6.2節(jié)中的類(lèi)似,但是不完全相同。集群X用于研究和開(kāi)發(fā),集群Y用于生產(chǎn)數(shù)據(jù)處理。
6.3.1 方法論和注意事項(xiàng)
本章節(jié)列出的這些結(jié)果數(shù)據(jù)只包括客戶(hù)機(jī)發(fā)起的原始請(qǐng)求,因此,這些結(jié)果能夠反映我們的應(yīng)用程序?qū)FS文件系統(tǒng)產(chǎn)生的全部工作負(fù)載。它們不包含那些為了實(shí)現(xiàn)客戶(hù)端請(qǐng)求而在服務(wù)器間交互的請(qǐng)求,也不包含GFS內(nèi)部的后臺(tái)活動(dòng)相關(guān)的請(qǐng)求,比如前向轉(zhuǎn)發(fā)的寫(xiě)操作,或者重新負(fù)載均衡等操作。
我們從GFS服務(wù)器記錄的真實(shí)的RPC請(qǐng)求日志中推導(dǎo)重建出關(guān)于IO操作的統(tǒng)計(jì)信息。例如,GFS客戶(hù)程序可能會(huì)把一個(gè)讀操作分成幾個(gè)RPC請(qǐng)求來(lái)提高并行度,我們可以通過(guò)這些RPC請(qǐng)求推導(dǎo)出原始的讀操作。因?yàn)槲覀兊脑L問(wèn)模式是高度程式化,所以我們認(rèn)為任何不符合的數(shù)據(jù)都是誤差(alex注:Since our access patterns are highly stylized, we expect any error to be in the noise)。應(yīng)用程序如果能夠記錄更詳盡的日志,就有可能提供更準(zhǔn)確的診斷數(shù)據(jù);但是為了這個(gè)目的去重新編譯和重新啟動(dòng)數(shù)千個(gè)正在運(yùn)行的客戶(hù)機(jī)是不現(xiàn)實(shí)的,而且從那么多客戶(hù)機(jī)上收集結(jié)果也是個(gè)繁重的工作。
應(yīng)該避免從我們的工作負(fù)荷數(shù)據(jù)中過(guò)度的歸納出普遍的結(jié)論(alex注:即不要把本節(jié)的數(shù)據(jù)作為基礎(chǔ)的指導(dǎo)性數(shù)據(jù))。因?yàn)镚oogle完全控制著GFS和使用GFS的應(yīng)用程序,所以,應(yīng)用程序都針對(duì)GFS做了優(yōu)化,同時(shí),GFS也是為了這些應(yīng)用程序而設(shè)計(jì)的。這樣的相互作用也可能存在于一般程序和文件系統(tǒng)中,但是在我們的案例中這樣的作用影響可能更顯著。
6.3.2 Chunk服務(wù)器工作負(fù)荷

表4顯示了操作按涉及的數(shù)據(jù)量大小的分布情況。讀取操作按操作涉及的數(shù)據(jù)量大小呈現(xiàn)了雙峰分布。小的讀取操作(小于64KB)一般是由查找操作的客戶(hù)端發(fā)起的,目的在于從巨大的文件中查找小塊的數(shù)據(jù)。大的讀取操作(大于512KB)一般是從頭到尾順序的讀取整個(gè)文件。
在集群Y上,有相當(dāng)數(shù)量的讀操作沒(méi)有返回任何的數(shù)據(jù)。在我們的應(yīng)用中,尤其是在生產(chǎn)系統(tǒng)中,經(jīng)常使用文件作為生產(chǎn)者-消費(fèi)者隊(duì)列。生產(chǎn)者并行的向文件中追加數(shù)據(jù),同時(shí),消費(fèi)者從文件的尾部讀取數(shù)據(jù)。某些情況下,消費(fèi)者讀取的速度超過(guò)了生產(chǎn)者寫(xiě)入的速度,這就會(huì)導(dǎo)致沒(méi)有讀到任何數(shù)據(jù)的情況。集群X通常用于短暫的數(shù)據(jù)分析任務(wù),而不是長(zhǎng)時(shí)間運(yùn)行的分布式應(yīng)用,因此,集群X很少出現(xiàn)這種情況。
寫(xiě)操作按數(shù)據(jù)量大小也同樣呈現(xiàn)為雙峰分布。大的寫(xiě)操作(超過(guò)256KB)通常是由于Writer使用了緩存機(jī)制導(dǎo)致的。Writer緩存較小的數(shù)據(jù),通過(guò)頻繁的Checkpoint或者同步操作,或者只是簡(jiǎn)單的統(tǒng)計(jì)小的寫(xiě)入(小于64KB)的數(shù)據(jù)量(alex注:即匯集多次小的寫(xiě)入操作,當(dāng)數(shù)據(jù)量達(dá)到一個(gè)閾值,一次寫(xiě)入),之后批量寫(xiě)入。
再來(lái)觀察一下記錄追加操作。我們可以看到集群Y中大的記錄追加操作所占比例比集群X多的多,這是因?yàn)榧篩用于我們的生產(chǎn)系統(tǒng),針對(duì)GFS做了更全面的調(diào)優(yōu)。

表5顯示了按操作涉及的數(shù)據(jù)量的大小統(tǒng)計(jì)出來(lái)的總數(shù)據(jù)傳輸量。在所有的操作中,大的操作(超過(guò)256KB)占據(jù)了主要的傳輸量。小的讀取(小于64KB)雖然傳輸?shù)臄?shù)據(jù)量比較少,但是在讀取的數(shù)據(jù)量中仍占了相當(dāng)?shù)谋壤@是因?yàn)樵谖募须S機(jī)Seek的工作負(fù)荷而導(dǎo)致的。
6.3.3 記錄追加 vs. 寫(xiě)操作
記錄追加操作在我們的生產(chǎn)系統(tǒng)中大量使用。對(duì)于集群X,記錄追加操作和普通寫(xiě)操作的比例按照字節(jié)比是108:1,按照操作次數(shù)比是8:1。對(duì)于作為我們的生產(chǎn)系統(tǒng)的集群Y來(lái)說(shuō),這兩個(gè)比例分別是3.7:1和2.5:1。更進(jìn)一步,這一組數(shù)據(jù)說(shuō)明在我們的兩個(gè)集群上,記錄追加操作所占比例都要比寫(xiě)操作要大。對(duì)于集群X,在整個(gè)測(cè)量過(guò)程中,記錄追加操作所占比率都比較低,因此結(jié)果會(huì)受到一兩個(gè)使用某些特定大小的buffer的應(yīng)用程序的影響。
如同我們所預(yù)期的,我們的數(shù)據(jù)修改操作主要是記錄追加操作而不是覆蓋方式的寫(xiě)操作。我們測(cè)量了第一個(gè)副本的數(shù)據(jù)覆蓋寫(xiě)的情況。這近似于一個(gè)客戶(hù)機(jī)故意覆蓋剛剛寫(xiě)入的數(shù)據(jù),而不是增加新的數(shù)據(jù)。對(duì)于集群X,覆蓋寫(xiě)操作在寫(xiě)操作所占據(jù)字節(jié)上的比例小于0.0001%,在所占據(jù)操作數(shù)量上的比例小于0.0003%。對(duì)于集群Y,這兩個(gè)比率都是0.05%。雖然這只是某一片斷的情況,但是仍然高于我們的預(yù)期。這是由于這些覆蓋寫(xiě)的操作,大部分是由于客戶(hù)端在發(fā)生錯(cuò)誤或者超時(shí)以后重試的情況。這在本質(zhì)上應(yīng)該不算作工作負(fù)荷的一部分,而是重試機(jī)制產(chǎn)生的結(jié)果。
6.3.4 Master的工作負(fù)荷

表6顯示了Master服務(wù)器上的請(qǐng)求按類(lèi)型區(qū)分的明細(xì)表。大部分的請(qǐng)求都是讀取操作查詢(xún)Chunk位置信息(FindLocation)、以及修改操作查詢(xún)lease持有者的信息(FindLease-Locker)。
集群X和Y在刪除請(qǐng)求的數(shù)量上有著明顯的不同,因?yàn)榧篩存儲(chǔ)了生產(chǎn)數(shù)據(jù),一般會(huì)重新生成數(shù)據(jù)以及用新版本的數(shù)據(jù)替換舊有的數(shù)據(jù)。數(shù)量上的差異也被隱藏在了Open請(qǐng)求中,因?yàn)榕f版本的文件可能在以重新寫(xiě)入的模式打開(kāi)時(shí),隱式的被刪除了(類(lèi)似UNIX的open函數(shù)中的“w”模式)。
FindMatchingFiles是一個(gè)模式匹配請(qǐng)求,支持“ls”以及其它類(lèi)似的文件系統(tǒng)操作。不同于Master服務(wù)器的其它請(qǐng)求,它可能會(huì)檢索namespace的大部分內(nèi)容,因此是非常昂貴的操作。集群Y的這類(lèi)請(qǐng)求要多一些,因?yàn)樽詣?dòng)化數(shù)據(jù)處理的任務(wù)進(jìn)程需要檢查文件系統(tǒng)的各個(gè)部分,以便從全局上了解應(yīng)用程序的狀態(tài)。與之不同的是,集群X的應(yīng)用程序更加傾向于由單獨(dú)的用戶(hù)控制,通常預(yù)先知道自己所需要使用的全部文件的名稱(chēng)。
#p#
7. 經(jīng)驗(yàn)
在建造和部署GFS的過(guò)程中,我們經(jīng)歷了各種各樣的問(wèn)題,有些是操作上的,有些是技術(shù)上的。
起初,GFS被設(shè)想為我們的生產(chǎn)系統(tǒng)的后端文件系統(tǒng)。隨著時(shí)間推移,在GFS的使用中逐步的增加了對(duì)研究和開(kāi)發(fā)任務(wù)的支持。我們開(kāi)始增加一些小的功能,比如權(quán)限和配額,到了現(xiàn)在,GFS已經(jīng)初步支持了這些功能。雖然我們生產(chǎn)系統(tǒng)是嚴(yán)格受控的,但是用戶(hù)層卻不總是這樣的。需要更多的基礎(chǔ)架構(gòu)來(lái)防止用戶(hù)間的相互干擾。
我們最大的問(wèn)題是磁盤(pán)以及和Linux相關(guān)的問(wèn)題。很多磁盤(pán)都聲稱(chēng)它們支持某個(gè)范圍內(nèi)的Linux IDE硬盤(pán)驅(qū)動(dòng)程序,但是實(shí)際應(yīng)用中反映出來(lái)的情況卻不是這樣,它們只支持最新的驅(qū)動(dòng)。因?yàn)閰f(xié)議版本很接近,所以大部分磁盤(pán)都可以用,但是偶爾也會(huì)有由于協(xié)議不匹配,導(dǎo)致驅(qū)動(dòng)和內(nèi)核對(duì)于驅(qū)動(dòng)器的狀態(tài)判斷失誤。這會(huì)導(dǎo)致數(shù)據(jù)因?yàn)閮?nèi)核中的問(wèn)題意外的被破壞了。這個(gè)問(wèn)題促使我們使用Checksum來(lái)校驗(yàn)數(shù)據(jù),同時(shí)我們也修改內(nèi)核來(lái)處理這些因?yàn)閰f(xié)議不匹配帶來(lái)的問(wèn)題。
較早的時(shí)候,我們?cè)谑褂肔inux 2.2內(nèi)核時(shí)遇到了些問(wèn)題,主要是fsync()的效率問(wèn)題。它的效率與文件的大小而不是文件修改部分的大小有關(guān)。這在我們的操作日志文件過(guò)大時(shí)給出了難題,尤其是在我們尚未實(shí)現(xiàn)Checkpoint的時(shí)候。我們費(fèi)了很大的力氣用同步寫(xiě)來(lái)解決這個(gè)問(wèn)題,但是最后還是移植到了Linux2.4內(nèi)核上。
另一個(gè)和Linux相關(guān)的問(wèn)題是單個(gè)讀寫(xiě)鎖的問(wèn)題,也就是說(shuō),在某一個(gè)地址空間的任意一個(gè)線程都必須在從磁盤(pán)page in(讀鎖)的時(shí)候先hold住,或者在mmap()調(diào)用(寫(xiě)鎖)的時(shí)候改寫(xiě)地址空間。我們發(fā)現(xiàn)即使我們的系統(tǒng)負(fù)載很輕的情況下也會(huì)有偶爾的超時(shí),我們花費(fèi)了很多的精力去查找資源的瓶頸或者硬件的問(wèn)題。最后我們終于發(fā)現(xiàn)這個(gè)單個(gè)鎖在磁盤(pán)線程交換以前映射的數(shù)據(jù)到磁盤(pán)的時(shí)候,鎖住了當(dāng)前的網(wǎng)絡(luò)線程,阻止它把新數(shù)據(jù)映射到內(nèi)存。由于我們的性能主要受限于網(wǎng)絡(luò)接口,而不是內(nèi)存copy的帶寬,因此,我們用pread()替代mmap(),用了一個(gè)額外的copy動(dòng)作來(lái)解決這個(gè)問(wèn)題。
盡管偶爾還是有其它的問(wèn)題,Linux的開(kāi)放源代碼還是使我們能夠快速探究和理解系統(tǒng)的行為。在適當(dāng)?shù)臅r(shí)候,我們會(huì)改進(jìn)內(nèi)核并且和公開(kāi)源碼組織共享這些改動(dòng)。
#p#
8. 相關(guān)工作
和其它的大型分布式文件系統(tǒng),比如AFS[5]類(lèi)似,GFS提供了一個(gè)與位置無(wú)關(guān)的名字空間,這使得數(shù)據(jù)可以為了負(fù)載均衡或者災(zāi)難冗余等目的在不同位置透明的遷移。不同于AFS的是,GFS把文件分布存儲(chǔ)到不同的服務(wù)器上,這種方式更類(lèi)似Xfs[1]和Swift[3],這是為了提高整體性能以及災(zāi)難冗余的能力。
由于磁盤(pán)相對(duì)來(lái)說(shuō)比較便宜,并且復(fù)制的方式比RAID[9]方法簡(jiǎn)單的多,GFS目前只使用復(fù)制的方式來(lái)進(jìn)行冗余,因此要比xFS或者Swift占用更多的裸存儲(chǔ)空間(alex注:Raw storage,裸盤(pán)的空間)。
與AFS、xFS、Frangipani[12]以及Intermezzo[6]等文件系統(tǒng)不同的是,GFS并沒(méi)有在文件系統(tǒng)層面提供任何Cache機(jī)制。我們主要的工作在單個(gè)應(yīng)用程序執(zhí)行的時(shí)候幾乎不會(huì)重復(fù)讀取數(shù)據(jù),因?yàn)樗鼈兊墓ぷ鞣绞揭词橇魇降淖x取一個(gè)大型的數(shù)據(jù)集,要么是在大型的數(shù)據(jù)集中隨機(jī)Seek到某個(gè)位置,之后每次讀取少量的數(shù)據(jù)。
某些分布式文件系統(tǒng),比如Frangipani、xFS、Minnesota’s GFS[11]、GPFS[10],去掉了中心服務(wù)器,只依賴(lài)于分布式算法來(lái)保證一致性和可管理性。我們選擇了中心服務(wù)器的方法,目的是為了簡(jiǎn)化設(shè)計(jì),增加可靠性,能夠靈活擴(kuò)展。特別值得一提的是,由于處于中心位置的Master服務(wù)器保存有幾乎所有的Chunk相關(guān)信息,并且控制著Chunk的所有變更,因此,它極大地簡(jiǎn)化了原本非常復(fù)雜的Chunk分配和復(fù)制策略的實(shí)現(xiàn)方法。我們通過(guò)減少M(fèi)aster服務(wù)器保存的狀態(tài)信息的數(shù)量,以及將Master服務(wù)器的狀態(tài)復(fù)制到其它節(jié)點(diǎn)來(lái)保證系統(tǒng)的災(zāi)難冗余能力。擴(kuò)展能力和高可用性(對(duì)于讀取)目前是通過(guò)我們的影子Master服務(wù)器機(jī)制來(lái)保證的。對(duì)Master服務(wù)器狀態(tài)更改是通過(guò)預(yù)寫(xiě)日志的方式實(shí)現(xiàn)持久化。為此,我們可以調(diào)整為使用類(lèi)似Harp[7]中的primary-copy方案,從而提供比我們現(xiàn)在的方案更嚴(yán)格的一致性保證。
我們解決了一個(gè)難題,這個(gè)難題類(lèi)似Lustre[8]在如何在有大量客戶(hù)端時(shí)保障系統(tǒng)整體性能遇到的問(wèn)題。不過(guò),我們通過(guò)只關(guān)注我們的應(yīng)用程序的需求,而不是提供一個(gè)兼容POSIX的文件系統(tǒng),從而達(dá)到了簡(jiǎn)化問(wèn)題的目的。此外,GFS設(shè)計(jì)預(yù)期是使用大量的不可靠節(jié)點(diǎn)組建集群,因此,災(zāi)難冗余方案是我們?cè)O(shè)計(jì)的核心。
GFS很類(lèi)似NASD架構(gòu)[4]。NASD架構(gòu)是基于網(wǎng)絡(luò)磁盤(pán)的,而GFS使用的是普通計(jì)算機(jī)作為Chunk服務(wù)器,就像NASD原形中方案一樣。所不同的是,我們的Chunk服務(wù)器采用惰性分配固定大小的Chunk的方式,而不是分配變長(zhǎng)的對(duì)象存儲(chǔ)空間。此外,GFS實(shí)現(xiàn)了諸如重新負(fù)載均衡、復(fù)制、恢復(fù)機(jī)制等等在生產(chǎn)環(huán)境中需要的特性。
不同于與Minnesota’s GFS和NASD,我們并不改變存儲(chǔ)設(shè)備的Model(alex注:對(duì)這兩個(gè)文件系統(tǒng)不了解,因?yàn)椴惶靼赘淖兇鎯?chǔ)設(shè)備的Model用來(lái)做什么,這不明白這個(gè)model是模型、還是型號(hào))。我們只關(guān)注用普通的設(shè)備來(lái)解決非常復(fù)雜的分布式系統(tǒng)日常的數(shù)據(jù)處理。
我們通過(guò)原子的記錄追加操作實(shí)現(xiàn)了生產(chǎn)者-消費(fèi)者隊(duì)列,這個(gè)問(wèn)題類(lèi)似River[2]中的分布式隊(duì)列。River使用的是跨主機(jī)的、基于內(nèi)存的分布式隊(duì)列,為了實(shí)現(xiàn)這個(gè)隊(duì)列,必須仔細(xì)控制數(shù)據(jù)流;而GFS采用可以被生產(chǎn)者并發(fā)追加記錄的持久化的文件的方式實(shí)現(xiàn)。River模式支持m-到-n的分布式隊(duì)列,但是缺少由持久化存儲(chǔ)提供的容錯(cuò)機(jī)制,GFS只支持m-到-1的隊(duì)列。多個(gè)消費(fèi)者可以同時(shí)讀取一個(gè)文件,但是它們輸入流的區(qū)間必須是對(duì)齊的。
#p#
9. 結(jié)束語(yǔ)
Google文件系統(tǒng)展示了一個(gè)使用普通硬件支持大規(guī)模數(shù)據(jù)處理的系統(tǒng)的特質(zhì)。雖然一些設(shè)計(jì)要點(diǎn)都是針對(duì)我們的特殊的需要定制的,但是還是有很多特性適用于類(lèi)似規(guī)模的和成本的數(shù)據(jù)處理任務(wù)。
首先,我們根據(jù)我們當(dāng)前的和可預(yù)期的將來(lái)的應(yīng)用規(guī)模和技術(shù)環(huán)境來(lái)評(píng)估傳統(tǒng)的文件系統(tǒng)的特性。我們的評(píng)估結(jié)果將我們引導(dǎo)到一個(gè)使用完全不同于傳統(tǒng)的設(shè)計(jì)思路上。根據(jù)我們的設(shè)計(jì)思路,我們認(rèn)為組件失效是常態(tài)而不是異常,針對(duì)采用追加方式(有可能是并發(fā)追加)寫(xiě)入、然后再讀取(通常序列化讀取)的大文件進(jìn)行優(yōu)化,以及擴(kuò)展標(biāo)準(zhǔn)文件系統(tǒng)接口、放松接口限制來(lái)改進(jìn)整個(gè)系統(tǒng)。
我們系統(tǒng)通過(guò)持續(xù)監(jiān)控,復(fù)制關(guān)鍵數(shù)據(jù),快速和自動(dòng)恢復(fù)提供災(zāi)難冗余。Chunk復(fù)制使得我們可以對(duì)Chunk服務(wù)器的失效進(jìn)行容錯(cuò)。高頻率的組件失效要求系統(tǒng)具備在線修復(fù)機(jī)制,能夠周期性的、透明的修復(fù)損壞的數(shù)據(jù),也能夠第一時(shí)間重新建立丟失的副本。此外,我們使用Checksum在磁盤(pán)或者IDE子系統(tǒng)級(jí)別檢測(cè)數(shù)據(jù)損壞,在這樣磁盤(pán)數(shù)量驚人的大系統(tǒng)中,損壞率是相當(dāng)高的。
我們的設(shè)計(jì)保證了在有大量的并發(fā)讀寫(xiě)操作時(shí)能夠提供很高的合計(jì)吞吐量。我們通過(guò)分離控制流和數(shù)據(jù)流來(lái)實(shí)現(xiàn)這個(gè)目標(biāo),控制流在Master服務(wù)器處理,而數(shù)據(jù)流在Chunk服務(wù)器和客戶(hù)端處理。當(dāng)一般的操作涉及到Master服務(wù)器時(shí),由于GFS選擇的Chunk尺寸較大(alex注:從而減小了元數(shù)據(jù)的大小),以及通過(guò)Chunk Lease將控制權(quán)限移交給主副本,這些措施將Master服務(wù)器的負(fù)擔(dān)降到最低。這使得一個(gè)簡(jiǎn)單、中心的Master不會(huì)成為成為瓶頸。我們相信我們對(duì)網(wǎng)絡(luò)協(xié)議棧的優(yōu)化可以提升當(dāng)前對(duì)于每客戶(hù)端的寫(xiě)入吞吐量限制。
GFS成功的實(shí)現(xiàn)了我們對(duì)存儲(chǔ)的需求,在Google內(nèi)部,無(wú)論是作為研究和開(kāi)發(fā)的存儲(chǔ)平臺(tái),還是作為生產(chǎn)系統(tǒng)的數(shù)據(jù)處理平臺(tái),都得到了廣泛的應(yīng)用。它是我們持續(xù)創(chuàng)新和處理整個(gè)WEB范圍內(nèi)的難題的一個(gè)重要工具。
【編輯推薦】