10G以太網:不只是一個更大的管道
原創【51CTO.COM 獨家翻譯】通過多隊列技術,10G以太網的速度可以達到9Gbit/s,我們拿它和用4個千兆網卡端口鏈路集合進行對比,從性能和經濟角度來看,四端口鏈路聚合(IEEE 802.3ad)被認為是"最佳點",但10G以太網比四端口鏈路集合解決方案消耗的CPU周期更少,并且速度也將近其2倍(9.5Gbit/s對比3.8Gbit/s),延遲也更小。
10G以太網卡也不是太貴,最貴的雙口10G以太網卡大約600-700美元,而普通的四端口千兆網卡也要400-500美元,更貴的10G以太網卡(>1000美元)提供的帶寬也更具競爭力(2x10G),每1美元換來的速率和每1瓦電力帶來的速率也更可觀,通常情況下,雙口10G以太網卡的用電量介于6W到14W之間,最好的四口千兆以太網卡耗電量低至4.3W,高的有8.4W。
10G以太網不只是一個更大的網絡通信管道,它的最大好處不是帶寬,而是通過端口整合降低了總體成本,要理解這一點我們看一下面這張圖便知。

圖 1 機柜中總是充滿了各種電纜
虛擬化服務器可能需要下面這些I/O端口:
控制臺和管理通信(以太網端口)
VM(虛擬機)遷移(以太網端口)
VM應用程序網絡I/O(以太網端口)
塊存儲I/O(光纖通道端口-FC)
文件存儲I/O(以太網端口)
出于速度和可用性方面的考慮,假設上述每種通信流量需要2個端口,那么每臺服務器就需要提供10個端口,如果你部署了基于IP的KVM系統和服務器遠程管理功能,那還得多準備一些端口。#p#
清理電纜混亂局面
一臺服務器上裝有6到12塊網卡就很多了,網卡數量越多,配置也越復雜,下圖是從VMware/英特爾白皮書中截取來的。
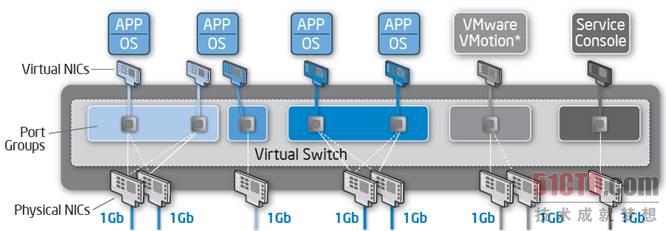
圖 2 物理網卡,端口組和虛擬網卡之間的關系
白皮書還沒有考慮存儲I/O,如果你使用兩塊FC卡,耗電量也會隨之增加14W(7Wx2),電纜也會多出兩根,我們以這樣一臺重度整合的服務器為例,最終它:
有10根I/O電纜(無KVM和服務器管理專用接口)
2塊4端口網卡x 5W+2塊FC卡x 7W=24W
24W并不大,實際上這已經是最好的情況,雙插槽服務器通常需要200-350W,四插槽服務器則要250-500W,因此I/O功耗約占總功耗的5-15%。
但10根I/O電纜卻是個大問題,端口和電纜越多,配置難度越大,排除故障所花的時間也會越長,不難想象,這種布線會浪費掉系統管理員太多時間,也會浪費掉太多的錢。
最大的問題當然是成本,首先,光纖通道電纜不便宜,但它和FC HBA,FC交換機和SFP比起來還是小兒科,每臺服務器連接8根以太網電纜也不便宜,雖然電纜成本可以忽略不計,但敷設成本可不能忽略。
整合來救援
解決上述問題的辦法就是"I/O匯聚"或"I/O整合",即將所有I/O流引入一根電纜,結果就是使用一套I/O基礎設施(以太網卡,電纜和交換機)支持所有I/O流,不再用不同的物理接口和電纜,而是在單張網卡(兩張就可以實現故障轉移)上整合了所有Vmotion,控制臺,VM通信和存儲通信,極大地降低了復雜性,耗電量,管理工作量和成本,你可能覺得這話怎么聽起來象是市場營銷人員口中說出來的,沒錯,要做到這一點確實很難。
如果所有通信全部走一根電纜,VM遷移和備份程序產生的流量足以讓存儲通信窒息,整個虛擬集群將會處于半死狀態,因為存儲通信是集群每個操作的開始和結束,因此給存儲I/O預留足夠的帶寬相當重要,幸運的是,在現代虛擬化平臺上要做到這一點很簡單,VMware稱之為流量整形,它允許你為某一些VM設置峰值和平均帶寬限制,只需要將VM加入端口組(Port Group),然后限制端口組的流量即可。對Vmotion流量也可以做類似的限制,只需要限制連接到Vmotion內核端口組的vSwitch的流量。
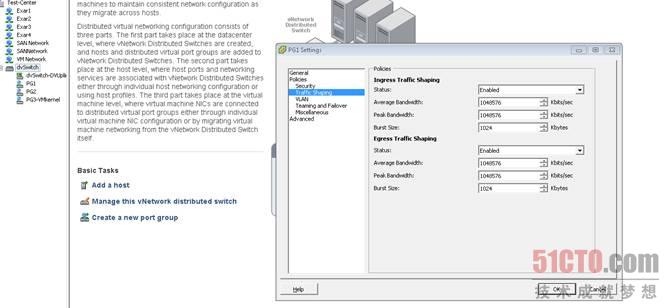
圖 3 VMware流量整形設置#p#
流量整形對出站通信非常管用,出站通信源于由Hypervisor管理和控制的內存空間,它和接收/入站通信完全不是一回事,入站通信首先是由網卡控制的,如果網卡在Hypervisor收到數據包之前將其丟掉,入站流量整形就沒意義了。
出站流量整形在所有VMware vSphere版本中均可用,實際上,它屬于標準vSwitch中的一個功能,區分入站和出站流量整形僅在最新的vNetwork分布式交換機(vNetwork Distributed Switch)上可用,這個高級功能只有你具有VMware vSphere企業增強版許可才能使用。
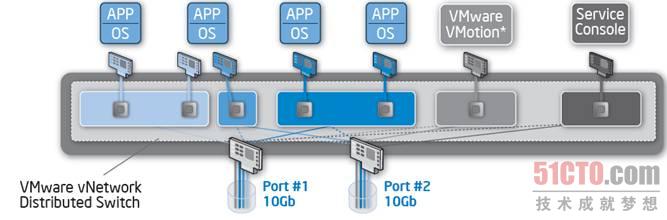
圖 4 vNetwork分布式交換機
如果使用正確的(虛擬化)軟件和配置整合10G以太網,我們可以將控制臺,存儲(iSCSI,NFS)和普通的網絡通信整合進兩個高性能的10G以太網卡。
解決虛擬化I/O難題
第一步:IOMMU和VT-d
解決高CPU負載,高延遲和低吞吐量的解決方案分為三個步驟,第一個解決方案是繞過Hypervisor,直接給網絡密集的VM指定網卡,這種做法有幾個優點,VM可以直接訪問本地設備驅動程序,因此可以使用各種硬件加速功能,由于網卡還沒有共享,所有隊列和緩沖區只對一個VM可用。
但是,即使Hypervisor允許VM直接訪問本地驅動程序,VM無法繞過Hypervisor的內存管理,客戶機OS(操作系統)也就不能訪問真實的物理內存,只能訪問由Hypervisor管理的虛擬內存映射,當Hypervisor給驅動程序發送地址時,它發出的是虛擬地址,而不是物理地址(下圖白色箭頭)。
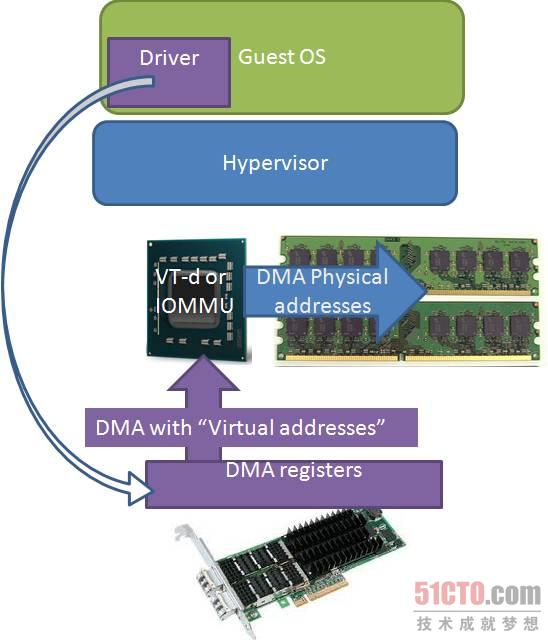
圖 5 客戶機OS只能訪問虛擬地址#p#
英特爾使用VT-d,AMD使用新的IOMMU技術解決了這個問題,I/O集線器將虛擬或客戶機OS假物理地址(紫色)轉換成真實的物理地址(藍色)。新的IOMMU通過給不同的設備分配不同的物理內存子集,實現了不同I/O設備相互隔離。
虛擬服務器很少使用這項功能,因為它使虛擬機遷移變成不可能完成的任務,相反,它們是從底層硬件解耦虛擬機,直接將VM分配給底層硬件,因此AMD IOMMU和英特爾VT-d技術單獨使用沒有多大用處,這僅僅是I/O虛擬化難題的1/3。
第二步:多隊列
接下來是使網卡變得更強大,而不是讓Hypervisor對所有接收到的數據包進行排序,然后再發送給正確的VM,網卡變成一個完整的硬件開關,將所有數據包排序后放入多個隊列,每個VM一個。
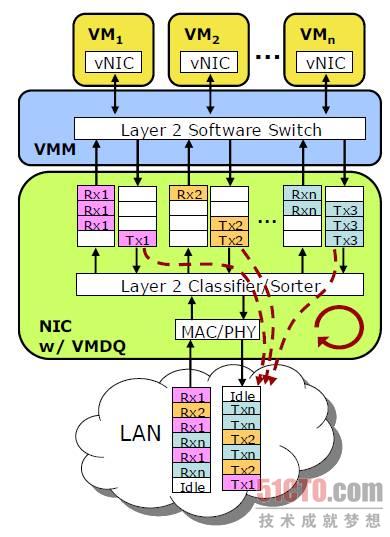
圖 6 虛擬機多隊列傳輸
更少的中斷和CPU負載。如果讓Hypervisor處理數據包交換,這意味著CPU 0要被中斷,檢查接收到的數據包,并確定目標VM,目標VM和相關的CPU立即中斷,使用網卡中的硬件開關,數據包被立即發送到正確的隊列,相關CPU立即中斷,并開始接收數據包。
更短的延遲。單個隊列負責接收和轉發多個VM的數據包會受不了,因此可能會出現丟包,讓每個VM擁有自己的隊列,吞吐量更高,延遲更低。
雖然虛擬機設備隊列(Virtual Machine Devices Queues)解決了許多問題,但仍然還有一些CPU開銷存在,每次CPU中斷時,Hypervisor必須從Hypervisor空間將數據復制到VM內存空間。
最后的難題:SR-IOV
最后一步是給你多個隊列設備中的每個隊列添加一些緩沖區和Rx/Tx描述符,單塊網卡可以偽裝成數十個"小"網卡,這也是PCI SIG做的工作,它們稱每個小網卡為一個虛函數(virtual functions,VF),根據PCI SIG SR-IOV規范,每塊網卡最大可以提供256個虛函數(注意:SR-IOV規范不限于網卡,其它I/O設備也可以有SR-IOV功能)。
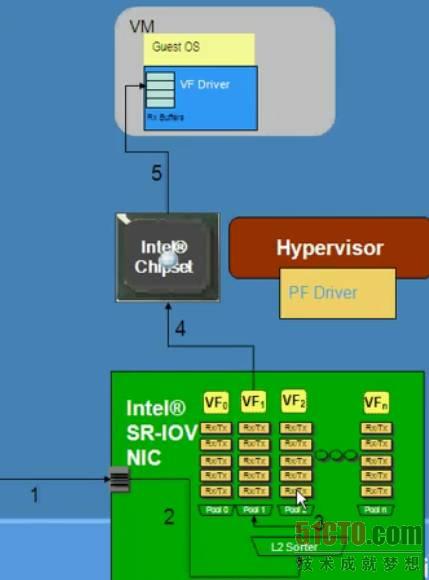
圖 7 具有SR-IOV功能的網卡可以創建多個虛函數#p#
確保系統中有帶有IOMMU/VT-d的芯片組,最終結果是,在無Hypervisor的幫助下,每個虛函數可以DMA數據包進出,這意味著CPU從網卡的內存空間將數據復制到VM的內存空間沒有必要,帶有VT-d/IOMMU功能的芯片組確保虛函數的DMA傳輸,并且不互相干擾,VM通過標準的半虛擬化驅動程序(如VMware的VMXnet)連接到這些虛函數,因此你可以任意遷移VM。
難題就這些,多隊列,DMA傳輸虛擬地址到物理地址的轉換,以及多頭網卡一起為你提供比模擬硬件更高的吞吐量,更低的延遲和更低的CPU消耗。同時,它們提供了兩個優勢使得虛擬仿真硬件變得非常流行:能跨多個VM共享一個硬件設備,并能夠從底層硬件分離出虛擬機。
SR-IOV支持
當然,這是所有理論,直到所有軟件和硬件層一起工作支持,你需要VT-d或IOMMU芯片組,主板BIOS必須識別這些虛函數,每個虛函數必須獲得內存映射IO空間,如其它PCI設備,支持SR-IOV的Hypervisor也是必需的。最后,但并非不重要,網卡廠商必須為操作系統和Hypervisor提供SR-IOV驅動。
在英特爾的強力支持下,支持SR-IOV的開源Hypervisor(Xen,KVM)和商業產品衍生物(Red Hat,Citrix)已經進入市場,截至2009年底,Xen和KVM都支持SR-IOV,更具體地說是英特爾10G以太網82599控制器,它可以提供高達64個虛函數,Citrix在XenServer 5.6中宣布開始支持SR-IOV,而VMware的ESX和微軟的Hyper-V卻遲遲未支持。
Neterion的解決方案
ESX 5.0和Windows Server 2008的繼任者將支持SR-IOV,由于大多數數據中心的主要Hypervisor是VMware的ESX,這意味著在獲得SR-IOV的好處之前,很大一部分已經虛擬化的服務器將不得不等待一年或更長時間。

圖 8 Neterion網卡
Neterion是多設備隊列的開創者,除了標準的SR-IOV和VMware NetQueue支持外,X3100網卡也含有專利實現。
圖 9 Neterion X3100網卡屬性#p#
專有解決方案只有在它們能提供更多好處時才有意義,Neterion聲稱網卡芯片對網絡優先級和服務質量有廣泛的硬件支持,硬件支持應該優于Hypervisor流量整形,特別是在接收端,如果突發流量導致網卡在接收端丟包,Hypervisor什么也做不了,因為它根本就沒見著數據包通過。為了強調這一點,Neterion為X3100配備了64MB接收緩沖區,而同水平的競爭性產品最大才提供512KB接收緩沖區,即使網絡流量相對暴漲,這個巨大的接收緩沖區應確保QoS得到保證。
在IBM,惠普,戴爾,富士通和日立服務器上均可看到Neterion網卡,Neterion是Exar的子公司,但它擁有自己的分銷渠道,這個網卡的價格大約在745美元左右。
競爭對手:Solarflare
Solarflare是一個相對年輕的公司,成立于2001年,Solarflare的主要宗旨是"讓以太網[銅]變得更好", Solarflare網卡也支持光學媒體,但最扯眼球的是它推出的10G以太網銅產品,2006年,Solarflare第一家發布10G Base-T PHY產品,10G Base-T允許在很常見和便宜的CAT5E,CAT6和CAT6A UTP電纜上實現10Gbit/s的傳輸速度。Solarflare也提倡在HPC領域使用10GbE,并聲稱可以做到讓10GbE的延遲低至4?s。在今年6月,Solarflare發布了雙端口10G Base-T網卡SFN5121T,功耗12.9W。今年1月,Solarflare決定開始直接面向最終用戶銷售網卡。

圖 10 Solarflare網卡
當我們拿到SFP+ Neterion X3120樣品時,我們發現它和SFN5121T的光學弟兄產品SFN5122F差不多,這兩款Solarflare網卡均支持SR-IOV,使用的都是PCIe 2.0標準,SFP+ SFN5122F功耗非常低,只有4.9W,Solarflare設計了他們自己的PHY,減少了網卡上的芯片數量。雖然我們的功率測試方法比較粗糙,但我們可以證實,Solarflare網卡是本次測試三款網卡功耗最低的。
Solarflare的網卡價格也更高一點,網上公開報價大約815美元。
舊網卡
從歷史角度來看總能發現一些有趣的東西,這些新網卡會不會大比分勝過舊的呢?為此我們測試了有一定歷史的Neterion XFrame-E,我們也嘗試增加支持SR-IOV,有超大接收緩沖區,更多隊列的英特爾82599,我們將這些網卡插入了超微Twin2進行測試。
基準測試配置
我們拿到的Twin?每個節點都使用的是相同的網卡,我們使用Ixchariot 5.4和Nttcp做了點對點測試。

圖 11#p#
虛擬化節點
處理器:英特爾至強E5504(2GHz,四核)和英特爾至強X5670(2.93GHz,六核)
主板:超微X8DTT-IBXF(英特爾5500芯片組)
內存:24GB DDR3-1066
硬盤:WD1000FYPS,英特爾X25-E SLC 32GB(用于IOmeter測試)
Hypervisor:VMware ESX 4 b261974(ESX4.0u2)
虛擬化節點配備了低端的4核和高端的6核測試CPU負載,四個VM使用半虛擬化網絡驅動VMXnet,這個虛擬化節點通過光纖連接到一個幾乎相同的運行Windows Server 2008 R2企業版的節點,唯一的不同是CPU,Windows 2008節點采用的是至強E5540(2.53GHz,四核)。
驅動
超微AOC-STG-I2(英特爾82598):ESX默認ixgbe 2.0.38.2.5-NAPI (261974, 24/05/2010)
Neterion x3120 IOV:ESX vxge 2.0.28.21239 (293373, 06/09/2010)
Solarflare Solarstorm SFN5122F:ESX sfc 3.0.5.2179 (16/07/2010)
Neterion xFrame-E:s2io 2.2.16.19752 (23/07/2010)
所有測試都開啟了netqueue。
本地帶寬:Windows Server 2008
我們的首先測試兩個安裝Windows Server 2008 R2企業版的節點,我們使用IxChariot 5.4測試吞吐量,執行了兩個分項測試:一種是標準的以太網幀長度(1.5KB),另一種是9KB巨型幀。所有測試開啟4個線程,Windows Server 2008最有趣的一個增強是接收端縮放(Receive-Side Scaling,RSS),它負責將接收處理分散到多個CPU核心,RSS在驅動屬性中啟用。
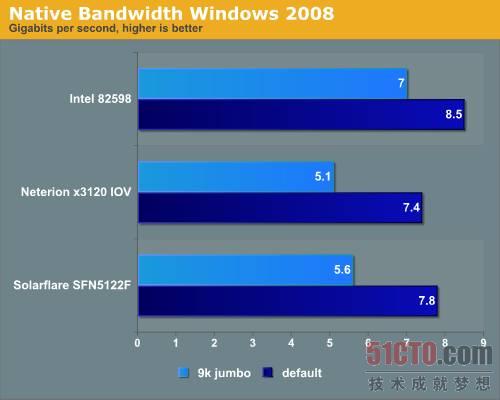
圖 12 在Windows Server 2008上進行本地帶寬測試的結果#p#
三個參與測試的網卡在傳輸巨型幀時的表現都很糟糕,巨型幀將每塊網卡的CPU負載從13-14%降低到了10%,但速度僅有5-5.6Gbit/s,讓人相當失望。Solarflare和Neterion網卡顯然是為虛擬化環境制造的,我們使用標準以太網幀測試時,Neterion和英特爾網卡的的CPU負載保持在14%左右,而Solarflare網卡需要10%左右的CPU負載,當我們開啟巨型幀后,所有網卡都需要大約10%的CPU負載(至強E5504 2GHz)。
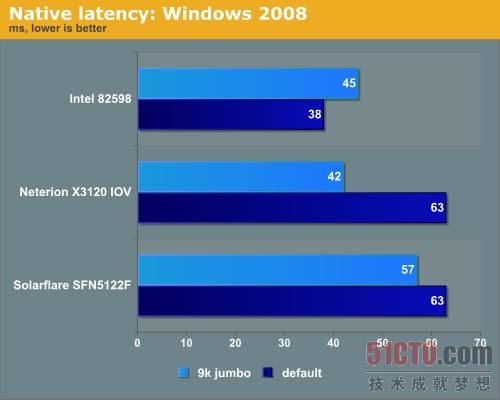
圖 13 在Windows Server 2008上進行延遲測試的結果
Solarflare網卡的延遲比其它的要高,因為Solarflare為Linux開源網絡堆棧OpenOnload做了許多工作,我們猜測Solarflare聲稱的低延遲是Linux下的網卡延遲,因為在HPC集群世界Linux占據主導地位,延遲比帶寬更重要,因此Solarflare的做法很有意義。
ESX 4.0性能
讓我們看看這些網卡在虛擬環境中能做什么,在ESX 4.1中做了一些測試后,我們返回到ESX 4.0u2,因為有大量的驅動問題,這肯定不是網卡廠商一家的責任,顯然,VMDirectPath在ESX 4.1中遭到了破壞,幸運的是,已經有人提交了BUG報告,相信在update 1中這個問題會得到解決。
我們從Windows Server 2008節點開始測試NTttcp。
NTttcp -m 4,0, [ip number] -a 4 -t 120
在虛擬節點上,我們使用Windows 2008創建了4個VM,每個VM開啟4個網絡負載線程,換句話說就是,總共會有16個活動線程,它們發送的數據包全部都要經過一個網卡端口。
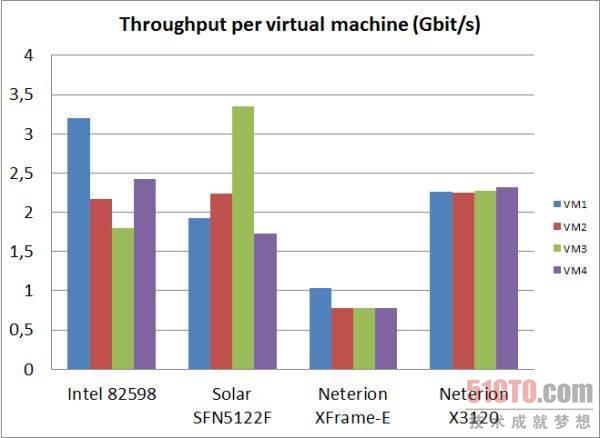
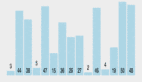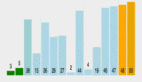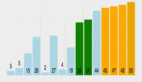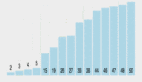
圖 14 單虛擬機吞吐量測試#p#
英特爾網卡實現了最高的吞吐量(9.6Gb/s),緊隨其后的是Solarflare(9.2Gb/s)和Neterion X3100(9.1Gb/s),老式的Xframe-E最高極限是3.4Gb/s,前3強在吞吐量方面幾乎不相上下,但從上圖可以看出,Neterion的X3120是唯一一塊跨4個VM實現良好的網絡流量負載均衡的網卡,所有VM獲得的帶寬幾乎一致(2.2-2.3Gb/s),Solarflare SF5122F和英特爾82598表現也不差,VM獲得的最低帶寬也有1.8Gb/s,使用帶寬測試套件Ixia Chariot 5.4獲得的結果也是這樣。此外,我們還測量了響應時間。
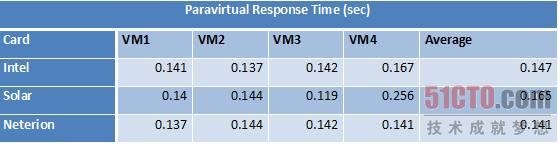
圖 15 半虛擬化響應時間
從平均響應時間我們可以看出,Neterion網卡以微小的優勢勝出,Solarflare SF5122則表現最差,因為有一個VM出現了雙倍延遲。下面再來看看這些網卡在循環傳輸VM產生的網絡流量時的CPU負載對比情況,這個測試是在至強E5504(2GHz)和至強X5670(2.93GHz)上完成的,所有CPU的超線程都被禁用了。
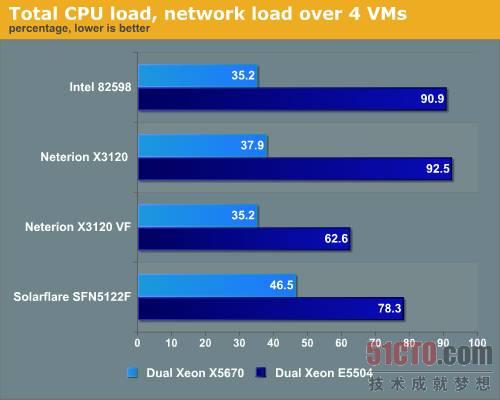
圖 16 CPU負載測試
大多數情況下,9Gb/s的半虛擬化網絡流量足以拖垮兩顆四核2GHz至強CPU,雖然它是目前最慢的至強處理器,但也很少看到超過8Gb/s的,因此這些10GbE網卡是很耗CPU資源的,Solarflare網卡給低端至強留有一些喘息空間,Neterion網卡為了提供完美的負載均衡服務,消耗的CPU資源會更多。
但Neterion網卡有一個秘密武器:它是唯一一塊可以在VMware ESX中使用虛函數的網卡,當你使用了虛函數后,CPU負載一下子就會下降很多,我們的測量結果是63%,CPU負載越低伴隨著帶寬也會下降。
當我們使用最快的至強處理器測試時,結果發生了顯著的變化,從上圖可以看出,英特爾和Neterion更好地利用額外的處理核心和更快的時鐘頻率。
整合和窒息
如果我們將存儲、網絡和管理流量整合進一條或兩條10GbE電纜,一個更簡單,成本更低,更容易管理的數據中心就指日可待了,那么新網卡要如何才能應付這些I/O需求呢?我們決定使用一個iSCSI啟動器混合連接兩類VM,一個發送大量存儲通信,其它三個發送正常的網絡通信,測試時我們也沒有做優化配置,我們只是將一個VM連接到iSCSI啟動器,其它三個則在運行IxChariot。
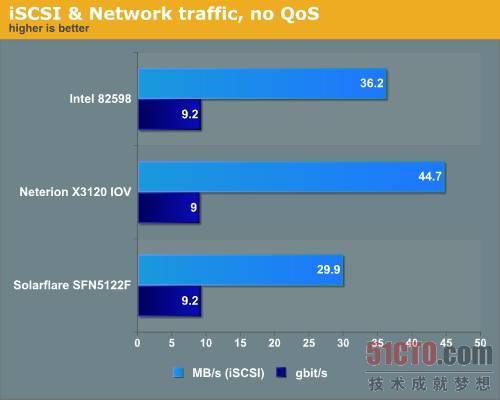
圖 17 iSCSI混合流量測試
從上圖不難看出,Neterion X3120憑借其獨有的4虛函數更有效地分散了負載,iSCSI VM在Neterion網卡上要快50%,優勢很明顯,讀取磁盤的速度快50%對最終用戶來說意義非同凡響,用戶體驗會完全不一樣。#p#
我們再來看看要控制這種殘酷的網絡流量需要多少CPU負載,虛擬節點上的兩個CPU都是至強X5670 2.93GHz。
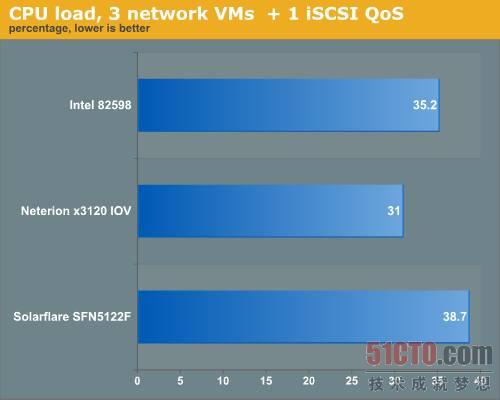
圖 18 CPU負載測試,3網絡VM+1 iSCSI QoS
Neterion網卡CPU負載稍微要低一點。
真正的理想狀態:整合I/O
接下來,我們重新配置了VM:
iSCSI VM以盡可能快的速度運行Iometer;
受限的兩個VM保證可以獲得2Gb/s;
允許使用IxChariot 測試的VM盡可能占用更多的帶寬。
這樣可以避免非受限的VM堵塞iSCSI VM,IxChariot允許我們按時間繪圖,我們想建立一個相互競爭的局面,因此我們決定只限制IxChariot VM。
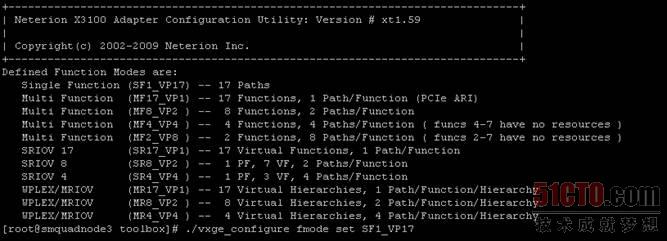
圖 19
Solarflare和英特爾網卡使用了VMware ESX 4.0出入站流量整形,Neterion網卡使用了硬件QoS和"多函數"功能。#p#
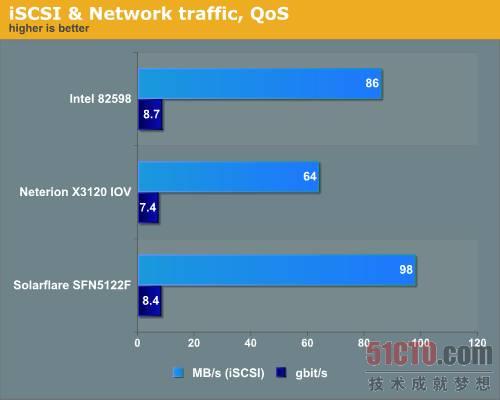
圖 20
從吞吐量來看,Solarflare和英特爾網卡表現更好,但僅從這個角度來衡量是很片面的,服務質量和流量整形的理想狀態是保證一定水平的性能,因此我們也應當重點思考如何讓那2個QoS VM能保證獲得穩定的2Gb/s帶寬。
細看服務質量
首先來看英特爾82598。
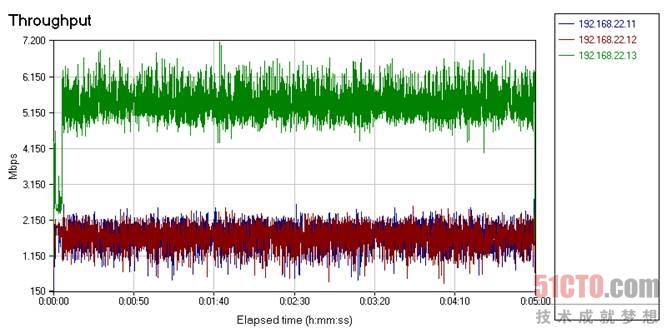
圖 21 英特爾82598吞吐量變化
從上圖可以看出,藍色和紅色線代表的吞吐量介于0.5-2.2Gb/s之間,由于我們的腳本構成了90%的接收幀,但做入站流量整形又沒有多大實際效果,要保持2Gb/s帶寬的確難度很大,Solarflare網卡亦是如此。
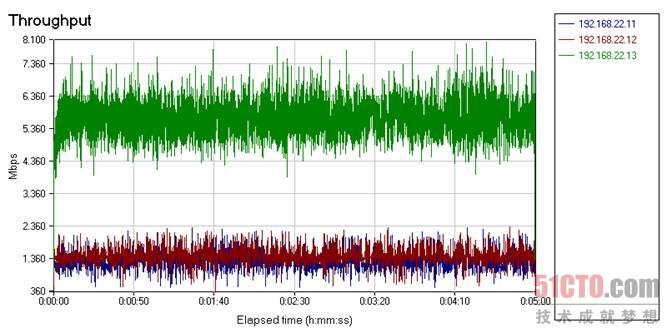
圖 22 Solarflare網卡吞吐量變化
重要的是要注意這只是Solarflare SF5122F的一個臨時方案,因為它支持SR-IOV,最大可以提供256個虛函數,ESX已正式支持SR-IOV,因此SF5122F可以表現得更好。下面來看看Neterion X3120網卡的Neterion SR-IOV。
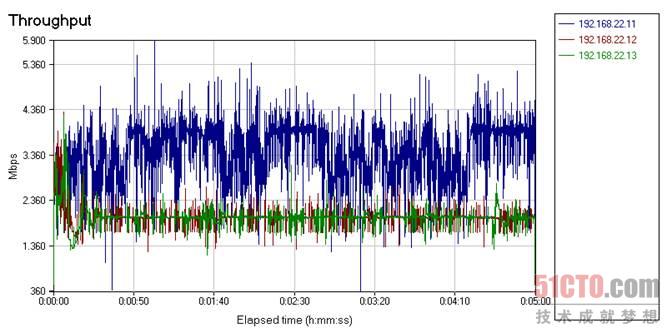
圖 23
如果我們忽略前面幾秒時間,你可以清楚地看到紅色和藍色線(現在的藍色線代表無QoS的VM)非常接近于2Gb/s,而開啟QoS的兩個VM在最糟糕的情況也達到了1.4Gb/s,大部分時間帶寬都非常接近2Gb/s,網卡中的64MB接收緩沖區和硬件QoS終于有了回報。#p#
我們的印象
首先討論一下本次評測的限制,英特爾網卡使用的是較舊的82598。

圖 24 參與測試的三塊網卡(左側是Neterion X3120,中間是Solarflare SFN5122F,右側是英特爾82598)
對于Windows Server 2008,我不會選擇Solarflare SFN5122F,因為英特爾82598才是最好的選擇,但Solarflare SFN5122F是功耗最低的網卡,并且實現了SR-IOV(256個VF,硬件QoS),因此我們做的測試(無SR-IOV的Windows 2008和ESX 4.0)無法展現這款網卡的真正潛力,如果在KVM和Xen下,開啟SR-IOV功能,加上Linux延時更低的TCP/IP堆棧,SFN5122F的表現會更好。
Neterion X3120除了實現標準SR-IOV外,還增加了自己獨有的功能,它率先提供虛函數功能,Neterion X3120 CPU負載更低,VM帶寬分配更公平(即使沒有QoS),加上大型接收緩沖區和硬件QoS,它很容易保證關鍵VM的最低帶寬需求。如果你想實踐SLA,這應該會降低成本。Neterion網卡允許你為"一般可預期的"峰值流量調整端口數量和帶寬,在沒有QoS和VF的情況下,你需要增加更多端口滿足極端峰值需要,否則就不能確保關鍵應用程序保持承諾的性能。
X3120也有缺點,它的散熱片比較大,因此是三塊網卡中功耗最大的,這方面Solarflare網卡最棒,此外,Neterion網卡需要更多調整才能表現得更好,因此Neterion X3120并不是完美的,但它目前絕對是最適合VMware vSphere的,除非你為服務器配置的功率非常低。
原文出處:http://www.anandtech.com/show/4014/10g-more-than-a-big-pipe
作者:Johan De Gelas
【51CTO.com獨家譯稿,非經授權謝絕轉載!合作媒體轉載請注明原文出處及出處!】