













云計算背后的秘密(7)-YunTable的故事
在本系列之前的一篇文章,和大家提到過,其實業界已經出現很多NoSQL產品,那么筆者為什么在這些產品的基礎上,研發新的NoSQL數據庫呢? 因為在研發YunEngine的時候,筆者發現在業界還缺乏一款在架構上非常簡潔,并同時可以適應各種云計算場景的NoSQL數據庫,所以在那時本人就開始進行YunTable的開發工作。
YunTable的目標并不是做一個像BigTable那樣大而全的數據庫,而是主要做一個精簡版的分布式Key-Value數據庫,上層的云計算應用將會根據其自身的需求去利用YunTable或者做修改,從而使YunTable能適應云計算各種場景,并且非常易用。YunTable已經在10月初正式開源,并發布其0.8版,官方地址是http://code.google.com/p/yuntable/。下面將對YunTable進行分析和介紹,包括它的設計、架構和如何適應不同的云計算環境。
YunTable的設計
談到一個NoSQL數據庫的設計時,肯定離不開數據模型、分布式架構和數據存儲這三方面。
在數據模型上,YunTable是Key-Value的,雖然Key-value這種數據模型在結構方面和傳統的關系型相比較簡單,有點類似常見的HashTable,一個Key對應一個Value,但是其能提供非常快的查詢速度、大的數據存放量和高并發地操作,并非常適合通過主鍵(Key)來對數據進行查詢和修改等操作,雖然不支持復雜的操作,但是可以通過上層的開發來彌補這個缺陷。
在分布式架構方面,YunTable選擇了Single Master模式來管理整個集群,雖然這個模式存在單點失敗的隱患,但是不論是在實現,還是在語義方面都非常簡單,而且為了避免Master出現單點失敗的情況,YunTable將會在今后版本中引入Shadow-Master這種機制。
在數據存儲方面,YunTable選擇了SSTable這種文件格式。簡單而言,SSTable是一個用于存儲已排序Key-Value對的文件格式,并且是不可變動的(Immutable),也就是寫了之后,只能將其更新附加在其之后,而不能直接進行修改,這樣是為了讓系統能執行Disk所擅長的順序訪問,而不是隨機訪問。在內部格式方面,SSTable文件主要有Index和Data Block這兩部分組成。在實際運行時,系統常會把Index載入內存,以確保查詢的效率。
YunTable的架構
在架構方面,主要可分為Region、Master和Client這三個模塊,而且這三個模塊都是獨立的,并負責各自的業務邏輯。
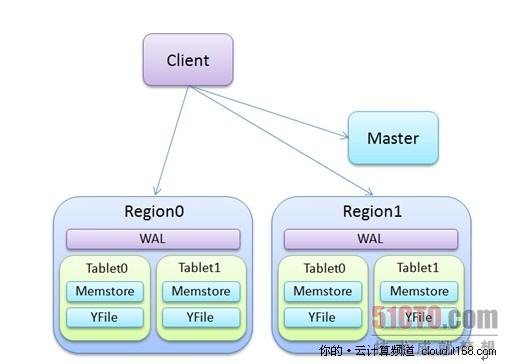
▲圖1. YunTable的架構
首先,介紹一下Master節點,Master節點在功能上面屬于比較“輕”調,主要負責維護Table和Region節點之間的對應關系,實際數據的查詢和輸入則都通過Region節點和Client端之間的交互完成,和Master節點無關,這樣能有效地減輕Master節點的負擔,使得其能支撐百臺服務器以上的集群。舉個例子,比如,當一個Client端需要處理某個Table的時候,它只需在***次處理時候,向Master請求和這個Table相關的Region節點的地址,當之后再次處理到這個Table的時候,Client端無需再和Master節點進行溝通,而是直接和相關的Region節點進行交互即可。
其次,談談Region節點,其作用是負責處理來自Client端的請求,并存儲和管理大量的數據,Region節點非常類似BigTable論文中所提到的Tablet服務器。每個Region服務器管理多個Tablet,每個Tablet對應一個Table,并負責存儲屬于這個Table的數據。除了管理多個Tablet之外,Region服務器還自帶WAL日志,全稱為“Write-Ahead Log”,主要用于暫存那些***的數據更新請求,以避免當Tablet中的Memstore被意外關閉時所造成的數據丟失,而當Memstore完成對數據的寫入之后,WAL也會清空那些對應的數據。用于存儲數據的Tablet主要有兩大部分組成:其一是Memstore:其是緩存在內存中的數據文件,主要存儲***添加的數據,當Memstore存儲的數據接近限定值時,在Memstore上緩存的數據都將會被沖刷(Flush)到YFile中;其二是YFile,它是主要用于存儲數據的持久化文件,它是基于上面提到的SSTable格式,YFile只會在當Memstore被觸發沖刷時創建,平時常被順序讀,這樣能有效地利用硬盤順序讀性能好的特性,文件的位置在其所屬Tablet的目錄中。
現在Client端主要以名為“YunCli”的命令行為主,主要用于讓用戶輸入與數據處理相關的命令,并與后端的Master節點和Region節點進行交互,但隨著時間的發展,在形式上,Client端有可能是類似JDBC的驅動等。
如何適應不同的云計算環境
云計算主要常見的有兩類場景:需要低延遲和高并發的讀寫能力,數據量雖大,但稱不上海量,估計最多在TB級別,大部分現在使用RDBMS的Web應用基本上都屬于這一類,有點類似傳統的OLTP(聯機事務處理);海量數據的存儲和操作,比如PB級別的,這方面的例子有傳統的數據倉庫、Google海量的Web頁面和圖片存儲等,有點類似傳統的OLAP(聯機分析處理)。
那么YunTable是如何適應這兩種環境?首先,堅持Key-Value、Single-Master和SSTable這樣經典和通用的設計。其次,在數據存儲方面,加入Hotness這個機制,主要是通過設置Hotness值來決定之前為了完成查詢而讀取到內存中的Data Block的生存時間,假設如果是低延遲的情況,那么將Hotness值設置長一點,如果是海量數據,則相反。
***,YunTable作為新一代的PaaS平臺YunEngine的后端數據庫已經投入實際運行中,而且即將發布其0.9版,在這個版本中,YunTable的單點性能和穩定性將會走上一個新的臺階。還有,下一篇將繼續給大家關注NoSQL。
作者簡介
吳朱華,之前在IBM中國研究院參與過多個云計算產品的開發工作,現在專注于YunTable(http://code.google.com/p/yuntable/)和YunEngine(http://yunengine.com/)的研發,并即將發表《剖析云計算》一書,敬請期待。
【編輯推薦】
- 云計算背后的秘密(3)-BigTable
- 云計算背后的秘密(2)-GFS
- 云計算背后的秘密(1)-MapReduce
- 云計算背后的秘密(4)-Chubby
- 云計算背后的秘密(6)-NoSQL數據庫綜述











