MySQL性能優化教程一
編者注:這是一篇MySQL性能優化的教程,來著某公司的DBA,原是為了培訓公司員工用,現在轉載出來供大家一起學習提高。
背景及目標
● 用于員工培訓和分享。
● 針對用戶群為已經使用過mysql環境,并有一定開發經驗的工程師
● 針對高并發,海量數據的互聯網環境。
● 本文語言為口語,非學術標準用語。
● 以實戰和解決具體問題為主要目標,非應試,非常規教育。友情提醒,在校生學習本教程可能對成績提高有害無益。
● 非技術挑戰,非高端架構師培訓,請高手自動忽略。
Mysql 執行優化
認識數據索引
1.為什么使用數據索引能提高效率
■ 數據索引的存儲是有序的
■ 在有序的情況下,通過索引查詢一個數據是無需遍歷索引記錄的
■ 極端情況下,數據索引的查詢效率為二分法查詢效率,趨近于 log2(N)
2.如何理解數據索引的結構
■ 數據索引通常默認采用btree索引,(內存表也使用了hash索引)。
■ 單一有序排序序列是查找效率最高的(二分查找,或者說折半查找),使用樹形索引的目的是為了達到快速的更新和增刪操作。
■ 在極端情況下(比如數據查詢需求量非常大,而數據更新需求極少,實時性要求不高,數據規模有限),直接使用單一排序序列,折半查找速度最快。
◆實戰范例 : ip地址反查
資源:
Ip地址對應表,源數據格式為 startip, endip, area
源數據條數為 10萬條左右,呈很大的分散性
目標:
需要通過任意ip查詢該ip所屬地區
性能要求達到每秒1000次以上的查詢效率
挑戰:
如使用 between … and 數據庫操作,無法有效使用索引。
如果每次查詢請求需要遍歷10萬條記錄,根本不行。
方法:
一次性排序(只在數據準備中進行,數據可存儲在內存序列)
折半查找(每次請求以折半查找方式進行)
■ 在進行索引分析和SQL優化時,可以將數據索引字段想象為單一有序序列,并以此作為分析的基礎。
◆實戰范例:復合索引查詢優化實戰,同城異性列表
資源: 用戶表user,字段 sex性別;area 地區;lastlogin 最后登錄時間;其他略
目標:
查找同一地區的異性,按照最后登錄時間逆序
高訪問量社區的高頻查詢,如何優化。
查詢SQL: select * from user where area=’$area’ and sex=’$sex’ order by lastlogin desc limit 0,30;
挑戰:
建立復合索引并不難, area+sex+lastlogin 三個字段的復合索引,如何理解?
首先,忘掉btree,將索引字段理解為一個排序序列。
如果只使用area會怎樣?搜索會把符合area的結果全部找出來,然后在這里面遍歷,選擇命中sex的并排序。 遍歷所有 area=’$area’數據!
如果使用了area+sex,略好,仍然要遍歷所有area=’$area’ and sex=’$sex’數據,然后在這個基礎上排序!!
Area+sex+lastlogin復合索引時(切記lastlogin在最后),該索引基于area+sex+lastlogin 三個字段合并的結果排序,該列表可以想象如下。
廣州女$時間1
廣州女$時間2
廣州女$時間3
…
廣州男
….
深圳女
….
數據庫很容易命中到 area+sex的邊界,并且基于下邊界向上追溯30條記錄,搞定!在索引中迅速命中所有結果,無需二次遍歷!
3.如何理解影響結果集
■ 影響結果集是數據查詢優化的一個重要中間數據
◆ 查詢條件與索引的關系決定影響結果集
如上例所示,即便查詢用到了索引,但是如果查詢和排序目標不能直接在索引中命中,其可能帶來較多的影響結果。而這會直接影響到查詢效率
◆ 微秒級優化
● 優化查詢不能只看慢查詢日志,常規來說,0.01秒以上的查詢,都是不夠優化的。
● 實戰范例
和上案例類似,某游戲社區要顯示用戶動態,select * from userfeed where uid=$uid order by lastlogin desc limit 0,30; 初期默認以uid為索引字段, 查詢為命中所有uid=$uid的結果按照lastlogin排序。 當用戶行為非常頻繁時,該SQL索引命中影響結果集有數百乃至數千條記錄。查詢效率超過0.01秒,并發較大時數據庫壓力較大。
解決方案:將索引改為 uid+lastlogin 復合索引,索引直接命中影響結果集30條,查詢效率提高了10倍,平均在0.001秒,數據庫壓力驟降。
■ 影響結果集的常見誤區
◆ 影響結果集并不是說數據查詢出來的結果數或操作影響的結果數,而是查詢條件的索引所命中的結果數。
◆ 實戰范例
● 某游戲數據庫使用了innodb,innodb是行級鎖,理論上很少存在鎖表情況。出現了一個SQL語句(delete from tabname where xid=…),這個SQL非常用SQL,僅在特定情況下出現,每天出現頻繁度不高(一天僅10次左右),數據表容量百萬級,但是這個xid未建立索引,于是悲慘的事情發生了,當執行這條delete 的時候,真正刪除的記錄非常少,也許一到兩條,也許一條都沒有;但是!由于這個xid未建立索引,delete操作時遍歷全表記錄,全表被delete操作鎖定,select操作全部被locked,由于百萬條記錄遍歷時間較長,期間大量select被阻塞,數據庫連接過多崩潰。
這種非高發請求,操作目標很少的SQL,因未使用索引,連帶導致整個數據庫的查詢阻塞,需要極大提高警覺。
■ 總結:
◆ 影響結果集是搜索條件索引命中的結果集,而非輸出和操作的結果集。
◆ 影響結果集越趨近于實際輸出或操作的目標結果集,索引效率越高。
◆ 請注意,我這里永遠不會講關于外鍵和join的優化,因為在我們的體系里,這是根本不允許的! 架構優化部分會解釋為什么。
#p#
理解執行狀態
1.常見分析手段
● 慢查詢日志,關注重點如下
■ 是否鎖定,及鎖定時間
◆ 如存在鎖定,則該慢查詢通常是因鎖定因素導致,本身無需優化,需解決鎖定問題。
■ 影響結果集
◆ 如影響結果集較大,顯然是索引項命中存在問題,需要認真對待。
● Explain 操作
■ 索引項使用
◆ 不建議用using index做強制索引,如未如預期使用索引,建議重新斟酌表結構和索引設置。
■ 影響結果集
◆ 這里顯示的數字不一定準確,結合之前提到對數據索引的理解來看,還記得嘛?就把索引當作有序序列來理解,反思SQL。
● Set profiling , show profiles for query操作
■ 執行開銷
◆ 注意,有問題的SQL如果重復執行,可能在緩存里,這時要注意避免緩存影響。通過這里可以看到。
◆ 執行時間超過0.005秒的頻繁操作SQL建議都分析一下。
◆ 深入理解數據庫執行的過程和開銷的分布
● Show processlist
■ 狀態清單
◆ Sleep 狀態, 通常代表資源未釋放,如果是通過連接池,sleep狀態應該恒定在一定數量范圍內
♦ 實戰范例: 因前端數據輸出時(特別是輸出到用戶終端)未及時關閉數據庫連接,導致因網絡連接速度產生大量sleep連接,在網速出現異常時,數據庫 too many connections 掛死。
♦ 簡單解讀,數據查詢和執行通常只需要不到0.01秒,而網絡輸出通常需要1秒左右甚至更長,原本數據連接在0.01秒即可釋放,但是因為前端程序未執行close操作,直接輸出結果,那么在結果未展現在用戶桌面前,該數據庫連接一直維持在sleep狀態!
◆ Waiting for net, reading from net, writing to net
♦ 偶爾出現無妨
♦ 如大量出現,迅速檢查數據庫到前端的網絡連接狀態和流量
♦ 案例: 因外掛程序,內網數據庫大量讀取,內網使用的百兆交換迅速爆滿,導致大量連接阻塞在waiting for net,數據庫連接過多崩潰
◆ Locked狀態
♦ 有更新操作鎖定
♦ 通常使用innodb可以很好的減少locked狀態的產生,但是切記,更新操作要正確使用索引,即便是低頻次更新操作也不能疏忽。如上影響結果集范例所示。
♦ 在myisam的時代,locked是很多高并發應用的噩夢。所以mysql官方也開始傾向于推薦innodb。
◆ Copy to tmp table
♦ 索引及現有結構無法涵蓋查詢條件,才會建立一個臨時表來滿足查詢要求,產生巨大的恐怖的i/o壓力。
♦ 很可怕的搜索語句會導致這樣的情況,如果是數據分析,或者半夜的周期數據清理任務,偶爾出現,可以允許。頻繁出現務必優化之。
♦ Copy to tmp table 通常與連表查詢有關,建議逐漸習慣不使用連表查詢。
♦ 實戰范例:
某社區數據庫阻塞,求救,經查,其服務器存在多個數據庫應用和網站,其中一個不常用的小網站數據庫產生了一個恐怖的copy to tmp table 操作,導致整個硬盤i/o和cpu壓力超載。Kill掉該操作一切恢復。
◆ Sending data
♦ Sending data 并不是發送數據,別被這個名字所欺騙,這是從物理磁盤獲取數據的進程,如果你的影響結果集較多,那么就需要從不同的磁盤碎片去抽取數據,
♦ 偶爾出現該狀態連接無礙。
♦ 回到上面影響結果集的問題,一般而言,如果sending data連接過多,通常是某查詢的影響結果集過大,也就是查詢的索引項不夠優化。
♦ 如果出現大量相似的SQL語句出現在show proesslist列表中,并且都處于sending data狀態,優化查詢索引,記住用影響結果集的思路去思考。
◆ Freeing items
♦ 理論上這玩意不會出現很多。偶爾出現無礙
♦ 如果大量出現,內存,硬盤可能已經出現問題。比如硬盤滿或損壞。
◆ Sorting for …
♦ 和Sending data類似,結果集過大,排序條件沒有索引化,需要在內存里排序,甚至需要創建臨時結構排序。
◆ 其他
♦ 還有很多狀態,遇到了,去查查資料。基本上我們遇到其他狀態的阻塞較少,所以不關心。
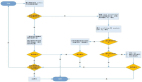
2.分析流程
● 基本流程
■ 詳細了解問題狀況
◆ Too many connections 是常見表象,有很多種原因。
◆ 索引損壞的情況在innodb情況下很少出現。
◆ 如出現其他情況應追溯日志和錯誤信息。
■ 了解基本負載狀況和運營狀況
◆ 基本運營狀況
♦ 當前每秒讀請求
♦ 當前每秒寫請求
♦ 當前在線用戶
♦ 當前數據容量
◆ 基本負載情況
♦ 學會使用這些指令
Top
Vmstat
uptime
iostat
df
♦ Cpu負載構成
特別關注i/o壓力( wa%)
多核負載分配
♦ 內存占用
Swap分區是否被侵占
如Swap分區被侵占,物理內存是否較多空閑
♦ 磁盤狀態
硬盤滿和inode節點滿的情況要迅速定位和迅速處理
■ 了解具體連接狀況
◆ 當前連接數
♦ Netstat –an|grep 3306|wc –l
♦ Show processlist
◆ 當前連接分布 show processlist
♦ 前端應用請求數據庫不要使用root帳號!
Root帳號比其他普通帳號多一個連接數許可。
前端使用普通帳號,在too many connections的時候root帳號仍可以登錄數據庫查詢 show processlist!
記住,前端應用程序不要設置一個不叫root的root帳號來糊弄!非root賬戶是骨子里的,而不是名義上的。
♦ 狀態分布
不同狀態代表不同的問題,有不同的優化目標。
參見如上范例。
雷同SQL的分布
是否較多雷同SQL出現在同一狀態
◆ 當前是否有較多慢查詢日志
♦ 是否鎖定
♦ 影響結果集
■ 頻繁度分析
◆ 寫頻繁度
♦ 如果i/o壓力高,優先分析寫入頻繁度
♦ Mysqlbinlog 輸出最新binlog文件,編寫腳本拆分
♦ 最多寫入的數據表是哪個
♦ 最多寫入的數據SQL是什么
♦ 是否存在基于同一主鍵的數據內容高頻重復寫入?
涉及架構優化部分,參見架構優化-緩存異步更新
◆ 讀取頻繁度
♦ 如果cpu資源較高,而i/o壓力不高,優先分析讀取頻繁度
♦ 程序中在封裝的db類增加抽樣日志即可,抽樣比例酌情考慮,以不顯著影響系統負載壓力為底線。
♦ 最多讀取的數據表是哪個
♦ 最多讀取的數據SQL是什么
該SQL進行explain 和set profiling判定
注意判定時需要避免query cache影響
比如,在這個SQL末尾增加一個條件子句 and 1=1 就可以避免從query cache中獲取數據,而得到真實的執行狀態分析。
♦ 是否存在同一個查詢短期內頻繁出現的情況
涉及前端緩存優化
■ 抓大放小,解決顯著問題
◆ 不苛求解決所有優化問題,但是應以保證線上服務穩定可靠為目標。
◆ 解決與評估要同時進行,新的策略或解決方案務必經過評估后上線。
3.總結
● 要學會怎樣分析問題,而不是單純拍腦袋優化
■ 慢查詢只是最基礎的東西,要學會優化0.01秒的查詢請求。
● 當發生連接阻塞時,不同狀態的阻塞有不同的原因,要找到原因,如果不對癥下藥,就會南轅北轍
■ 范例:如果本身系統內存已經超載,已經使用到了swap,而還在考慮加大緩存來優化查詢,那就是自尋死路了。
● 監測與跟蹤要經常做,而不是出問題才做
■ 讀取頻繁度抽樣監測
◆ 全監測不要搞,i/o嚇死人。
◆ 按照一個抽樣比例抽樣即可。
◆ 針對抽樣中發現的問題,可以按照特定SQL在特定時間內監測一段全查詢記錄,但仍要考慮i/o影響。
■ 寫入頻繁度監測
◆ 基于binlog解開即可,可定時或不定時分析。
■ 微慢查詢抽樣監測
◆ 高并發情況下,查詢請求時間超過0.01秒甚至0.005秒的,建議酌情抽樣記錄。
■ 連接數預警監測
◆ 連接數超過特定閾值的情況下,雖然數據庫沒有崩潰,建議記錄相關連接狀態。
● 學會通過數據和監控發現問題,分析問題,而后解決問題順理成章。特別是要學會在日常監控中發現隱患,而不是問題爆發了才去處理和解決。
【編輯推薦】