Oceanbase一個千億級海量數據庫
有一些同學問我,Oceanbase的創新點在哪里? 從大學的數據結構課程可以知道,數據量比較大時,有兩種數據結構很常用:哈希表和B+樹,分布式系統也是類似的。如下圖:
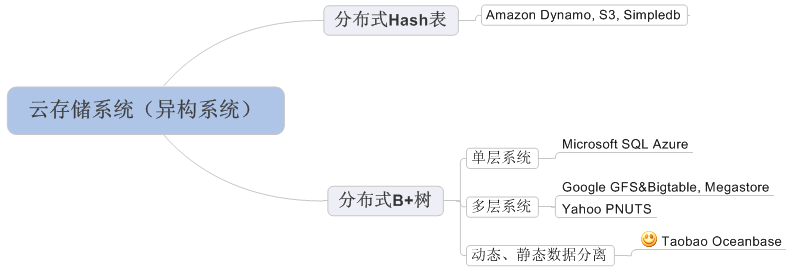
Amazon的系統實現了一個分布式哈希表,而Google Bigtable, Yahoo PNUTS,Microsoft SQL Azure實現了一顆分布式B+樹。分布式哈希表實現相對簡單,但只支持隨機讀取;而分布式B+樹支持范圍查詢,但實現比較復雜,主要有兩個難點:
1, 狀態數據的持久化和遷移。更新操作改變系統的狀態,數據庫系統中更新操作首先以事務提交日志(MySQL稱為binlog, NOSQL稱為commit log)寫入到磁盤,為了保證可靠性,commit log需要復制多份并保證它們之間的一致性。另外,機器宕機時需要通過commit log記錄的狀態修改信息將服務遷移到集群中的其它節點。
2, 子表的分裂和合并。B+樹實現的難點在于樹節點的分裂與合并,在分布式系統中,數據被順序劃分為大小在幾十到幾百MB大小的數據范圍,一般稱為子表,相當于B+樹結構中的葉子節點。由于每個子表在系統中存儲多份,需要保證多個副本之間的分裂點是一致的。由于子表在分裂的同時也有更新操作,保證多個副本之間一致是比較困難的。
對于這兩個問題,不同的系統有不同的解決方法:
1, 狀態維持。Google Bigtable將狀態數據寫入到GFS中,由GFS提供可靠性保證,但GFS本身是一個巨大的工程;Yahoo PNUTS將狀態數據寫入到分布式消息中間件,Yahoo內部稱為Yahoo Message Broker;Microsoft SQL Azure直接通過網絡將數據復制到多機,由于一臺機器服務多個子表,這些子表的副本可能分布在整個集群中,因此,任何兩臺機器都可能建立數據復制的網絡通道,需要處理與這些通道有關的異常情況。
2, 子表分裂。由于底層有GFS保證可靠性,Google Bigtable設計時保證每一個子表同時只被一臺機器(Tablet Server)服務;Yahoo PNUTS通過引入復雜的兩節點提交(Two-phase commit)協議協調多個副本之間的一致性,使得他們的分裂點相同;Microsoft SQL Azure干脆不支持子表分裂,犧牲一部分擴展性從而簡化系統設計。
淘寶Oceanbase設計之初對淘寶的在線存儲需求進行分析發現:淘寶的數據總量比較大,未來一段時間,比如五年之內的數據規模為百TB級別,千億條記錄,另外,數據膨脹很快,傳統的分庫分表對業務造成很大的壓力,必須設計自動化的分布式系統;然而,在線存儲每天的修改量很小,大多數情況下單機的內存就能存放下。因此,我們采用將動態數據和靜態數據分離的辦法。動態數據的數據量小,采用集中式的方法解決,這樣,狀態數據維持從一個分布式的問題轉化為單機的問題;靜態數據的數據量大,采用分布式的方法解決,因為靜態數據基本不變,實現時不需要復雜的線程同步機制,另外,保證靜態數據的多個副本之間一致性是比較容易的,簡化了子表的分裂和合并操作。通過這樣的權衡,淘寶Oceanbase以一種很簡單的方式滿足了未來一段時間的在線存儲需求,并且還獲得了一些其它特性,如高效支持跨行跨表事務,這對于淘寶的業務是非常重要的。另外,我們之所以敢于做這樣的權衡,還有一個重要的原因:我們內部已經思考了很多關于動態數據由集中式變為分布式的方案,即使我們對需求估計有些偏差,也可以很快修改原有系統進一步提高可擴展性。
【編輯推薦】