













SEO新手 淺談搜索引擎工作原理
搜索引擎工作原理如下:
也許很多人會問,現在互聯網發展到今時今日,已成為了區別于現實世界的另一個世界,也就是虛擬的世界,那么他的網頁數量到目前究竟有多少呢?如果要具體說出一個確切的數據,肯定沒有人能夠回答的出來的,但是我敢肯定的說,目前的網頁數量至少是以千億來計算,因為這是一個隨時變化的數據,而且數據非常龐大,沒有人能精確算出來。這些網頁,組成不同的網站,存儲在世界各地不同的服務器上,并且分布在世界各地數據中心和機房里。
也許還有大部分人認為,當我們在搜索框里敲入搜索請求,搜索引擎就會實時地從世界各地的服務器上進行查詢信息、收集整理,并把查詢結果排序展示在用戶面前。包括我之前還沒有接觸搜索引擎時,也是認為搜索引擎就是這樣子工作的,但是今天我知道這是一個錯誤的認為,搜索引擎不是這樣工作的。
全球這么多網頁,搜搜引擎是不可能進行實時地全部抓取,并整理排序的,對全球網頁進行全部抓取需要很大的儲存空間和技術,目前沒有哪一個搜索引擎能承受的起的。據統計,如果搜索引擎是進行實時工作的話,當你發出你的搜索請求到看到搜索結果,這個“實時”可能要等上好幾年甚至更長。
那么面對如此龐大的數據庫,搜索引擎又是如何去工作的呢?就此,漠陽子SEO博客給大家分析一下!
我們通俗地說,其實是這么一回事,搜索引擎盡***的能力,預先就去深入大量網站,把這些網頁的部分認為是有價值的信息預先存儲在自己的服務器上;然后,當用戶搜索時,再從自己的服務器上把適合的信息展現出來。就好比如我們在互聯網上找資料和在自己電腦上找資料的區別。
從搜索引擎的基本技術來講,包括抓取、索引、排序三個方面。
***,抓取
相信大家對于搜索引擎里所說的“蜘蛛”、“機器人”不會很陌生,他就像是搜索引擎的一大猛將,根據一定的程序規則,這位“猛將”在互聯網上進行掃描,以網站的鏈接為橋梁進行不斷的爬行。從而所進過的新站、舊站,只要是它認為是有價值的信息,就進行抓取,并收入囊中。
第二,索引
每一個搜索引擎都會有自己的一套分析索引系統,對抓取回來的網頁進行相關的提取,比如網頁的URL、編碼、頁面內容、鏈接、生成時間、關鍵詞等,通過一定的算法進行復雜的計算,并計算出網頁的相關度(關鍵詞、重要性),然后建立一個索引數據庫。
第三。排序
排序,簡單地說就是當用戶輸入關鍵詞并發出搜索請求后,搜索引擎的系統就會根據你的關鍵詞在網頁索引數據庫里進行查找,然后再顯示在搜索結果上返回給用戶。按照自然排名來說,這些索引數據庫里的網頁事先已經計算好相關度的了,越接近搜索請求的要求就越排在前面。這也是為什么我們要對網站進行優化的關鍵所在,想必每個網站都是想躋身在前面的。
***我們來看一幅搜索引擎工作原理的圖,這樣會更直觀明了。
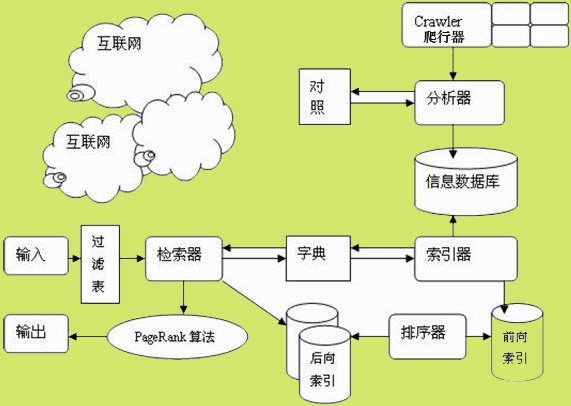
如果圖片不清楚的話,大家可以點擊查看大圖的。希望本文能夠給你帶來幫助。
【編輯推薦】












