













分散處理 Hadoop架構服務器角色
在Hadoop運算集群架構中,先分解任務,分工處理再匯總結果這些服務器依據用途可分成Master節點和Worker節點,Master負責分配任務,而Worker負責執行任務,如負責分派任務的操作,角色就像是Master節點。
Hadoop架構服務器角色分工
Hadoop運算集群中的服務器依用途分成Master節點和Worker節點。Master節點中安裝了JobTracker、NameNode、TaskTracker和DataNode程序,但Worker節點只安裝TaskTracker和DataNode。
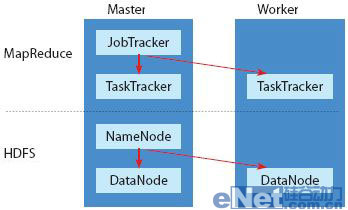
另外在系統的運行架構上,最簡單的Hadoop架構,可以分成上層的MapReduce運算層以及下層的HDFS數據層。
在Master節點的服務器中會執行兩套程序,一個是負責安排MapReduce運算層任務的JobTracker,以及負責管理HDFS數據層的NameNode程序。而在Worker節點的服務器中也有兩套程序,接受JobTracker指揮,負責執行運算層任務的是TaskTracker程序,而與NameNode對應的則是DataNode程序,負責執行數據讀寫動作,以及執行NameNode的副本策略。
在MapReduce運算層上,擔任Master節點的服務器負責分配運算任務, Master節點上的JobTracker程序會將 Map和Reduce程序的執行工作,指派給Worker服務器上的TaskTracker程序,由TaskTracker負責執行Map和Reduce工作,并將運算結果回復給Master節點上的JobTracker。
在HDFS數據層上,NameNode負責管理和維護HDFS的名稱空間、并且控制文件的任何讀寫操作,同時NameNode會將要處理的數據切割成一個個文件區塊(Block),每個區塊是64MB,例如1GB的數據就會切割成16個文件區塊。NameNode還會決定每一份文件區塊要建立幾個副本,一般來說,一個文件區塊總共會復制成3份,并且會分散儲存到3個不同Worker服務器的DataNode程序中管理,只要其中任何一份文件區塊遺失或損壞,NameNode會自動尋找位于其他DataNode上的副本來回復,維持3份的副本策略。
在一套Hadoop集群中,分配MapReduce任務的JobTracker只有1個,而TaskTracker可以有很多個。同樣地,負責管理HDFS文件系統的NameNode也只有一個,和JobTracker同樣位于Master節點中,而DataNode可以有很多個。
不過,Master節點中除了有JobTracker和NameNode以外,也會有TaskTracker和DataNode程序,也就是說Master節點的服務器,也可以在本地端扮演Worker角色的工作。
在部署上,因為Hadoop采用Java開發,所以Master服務器除了安裝操作系統如Linux之外,還要安裝Java運行環境,然后再安裝Master需要的程序,包括了NameNode、JobTracker和DataNode與TaskTracker。而在Worker服務器上,則只需安裝Linux、Java環境、DataNode和TaskTracker。












