簡(jiǎn)述Lucene的分析過程
回顧倒排索引的構(gòu)建
")
- 收集待建索引的原文檔(Document)
- 將原文檔傳給詞條化工具(Tokenizer)進(jìn)行文本詞條化
- 將第二步得到的詞條(Token)傳給語言分析工具(Linguistic modules)進(jìn)行語言學(xué)預(yù)處理,得到詞項(xiàng)(Term)
- 將得到的詞項(xiàng)(Term)傳給索引組件(Indexer),建立倒排索引
注:詳細(xì)文檔->倒排索引的理論過程見詞項(xiàng)詞典及倒排記錄表
分析操作的使用場(chǎng)景
1.如上,倒排索引的構(gòu)建階段
2.針對(duì)自由文本的查詢階段
QueryParser parser = new QueryParser(Version.LUCENE_36, field, analyzer);
Query query = parser.parse(queryString);
lucene的Analyzer接收表達(dá)式queryString中連續(xù)的獨(dú)立的文本片段,但不會(huì)接收整個(gè)表達(dá)式。
例如:對(duì)查詢語句"president obama" + harvard + professor,QueryParser會(huì)3次調(diào)用分析器,首先是處理文本“president obama”,然后是文本“harvard”,***處理“professor”。
3.搜索結(jié)果中高亮顯示被搜索內(nèi)容時(shí)(即結(jié)果摘要-Snippets的生成),也可能會(huì)用到分析操作
剖析lucene分析器
抽象類Analyzer
Analyzer類是一個(gè)抽象類,是所有分析器的基類。
其主要包含兩個(gè)接口,用于生成TokenStream(所謂TokenStream,后面我們會(huì)講到,是一個(gè)由分詞后的Token 結(jié)果組成的流,能夠不斷的得到下一個(gè)分成的Token。)。
接口:
1.TokenStream tokenStream(String fieldName, Reader reader)
2.TokenStream reusableTokenStream(String fieldName, Reader reader)
為了提高性能,使得在同一個(gè)線程中無需再生成新的TokenStream 對(duì)象,老的可以被重用,所以有reusableTokenStream 一說。
Analyzer 中有CloseableThreadLocal<Object> tokenStreams = newCloseableThreadLocal<Object>(); 成員變量, 保存當(dāng)前線程原來創(chuàng)建過的TokenStream , 可用函數(shù)setPreviousTokenStream 設(shè)定,用函數(shù)getPreviousTokenStream 得到。在reusableTokenStream 函數(shù)中,往往用getPreviousTokenStream 得到老的TokenStream 對(duì)象,然后將TokenStream 對(duì)象reset 一下,從而可以重新開始得到Token 流。
抽象類ReusableAnalyzerBase
ReusableAnalyzerBase extendsAnalyzer,顧名思義主要為tokenStream的重用。
其包含一個(gè)接口,用于生成TokenStreamComponents。
接口:
TokenStreamComponents createComponents(String fieldName,Reader reader);
reusableTokenStream的實(shí)現(xiàn)代碼分析:
- public final TokenStream reusableTokenStream(final String fieldName,
- final Reader reader) throws IOException {
- // 得到上一次使用的TokenStream
- TokenStreamComponents streamChain = (TokenStreamComponents)getPreviousTokenStream();
- final Reader r = initReader(reader);
- //如果沒有PreviousTokenStream則生成新的, 并且用setPreviousTokenStream放入成員變量,使得下一個(gè)可用。
- //如果上一次生成過TokenStream,則reset。reset失敗則生成新的。
- if (streamChain == null || !streamChain.reset(r)) {
- streamChain = createComponents(fieldName, r);
- setPreviousTokenStream(streamChain);
- }
- return streamChain.getTokenStream();
- }
內(nèi)部static類TokenStreamComponents
簡(jiǎn)單封裝輸入Tokenizer和輸出TokenStream。
最簡(jiǎn)單的一個(gè)Analyzer:SimpleAnalyzer
SimpleAnalyzer extendsReusableAnalyzerBase,實(shí)現(xiàn)createComponents方法。TokenStream的處理是將字符串最小化,生成按照空格分隔的Token流
- protected TokenStreamComponents createComponents( final String fieldName,
- final Reader reader) {
- return new TokenStreamComponents(new LowerCaseTokenizer(matchVersion , reader));
- }
抽象類TokenStream
TokenStream 主要包含以下幾個(gè)方法:
1. boolean incrementToken()用于得到下一個(gè)Token。IndexWriter調(diào)用此方法推動(dòng)Token流到下一個(gè)Token。實(shí)現(xiàn)類必須實(shí)現(xiàn)此方法并更新Attribute信息到下一個(gè)Token。
2. public void reset() 重設(shè)Token流到開始,使得此TokenStrean 可以重新開始返回各個(gè)分詞。
和原來的TokenStream返回一個(gè)Token 對(duì)象不同,Lucene 3.0 開始,TokenStream已經(jīng)不返回Token對(duì)象了,那么如何保存下一個(gè)Token 的信息呢?
在Lucene 3.0 中,TokenStream 是繼承于AttributeSource,其包含Map,保存從class 到對(duì)象的映射,從而可以保存不同類型的對(duì)象的值。在TokenStream 中,經(jīng)常用到的對(duì)象是CharTermAttributeImpl,用來保存Token 字符串;PositionIncrementAttributeImpl 用來保存位置信息;OffsetAttributeImpl 用來保存偏移量信息。所以當(dāng)生成TokenStream 的時(shí)候, 往往調(diào)用CharTermAttribute tokenAtt = addAttribute(CharTermAttribute.class)將CharTermAttributeImpl添加到Map 中,并保存一個(gè)成員變量。在incrementToken() 中, 將下一個(gè)Token 的信息寫入當(dāng)前的tokenAtt , 然后使用CharTermAttributeImpl.buffer()得到Token 的字符串。
注:Lucene 3.1開始廢棄了TermAttribute和TermAttributeImpl,用CharTermAttribute和CharTermAttributeImpl代替。
Token attributes
如上述,Token的信息真正存在于各個(gè)AttributeImpl中,lucene內(nèi)建的所有Attribute接口都在org.apache.lucene.analysis.tokenattributes包中。
Token attributes API的使用
1. 調(diào)用addAttribute(繼承于AttributeSource)方法,返回一個(gè)對(duì)應(yīng)屬性接口的實(shí)現(xiàn)類,以獲得需要的屬性。
2. 遞歸TokenStream incrementToken()方法,遍歷Token流。當(dāng)incrementToken返回true時(shí),其中Token的屬性信息會(huì)將內(nèi)部狀態(tài)修改為下個(gè)詞匯單元。
3. lucene內(nèi)建Attribute接口都是可讀寫的,TokenStream 在遍歷Token流時(shí),會(huì)調(diào)用Attribute接口的set方法,修改屬性信息。
lucene內(nèi)建常用Attribute接口
1. CharTermAttribute 保存Token對(duì)應(yīng)的term文本,Lucene 3.1開始用CharTermAttribute代替TermAttribute
2. FlagsAttribute 自定義標(biāo)志位
3. OffsetAttribute startOffset是指Term的起始字符在原始文本中的位置,endOffset則表示Term文本終止字符的下一個(gè)位置。偏移量常用于搜索結(jié)果中高亮Snippets的生成
4. PayloadAttribute 保存有效負(fù)載
5. TypeAttribute 保存Token類型,默認(rèn)為"word",實(shí)際中可根據(jù)Term的詞性來做自定義操作
6. PositionIncrementAttribute
保存相對(duì)于前一個(gè)Term的位置信息,默認(rèn)值設(shè)為1,表示所有的Term都是連續(xù)的,在位置上是一個(gè)接一個(gè)的。如果位置增量大于1,則表示Term之間有空隙,可以用這個(gè)空隙來表示被刪除的Term項(xiàng)(如停用詞)。位置增量為0,則表示該Term項(xiàng)與前一個(gè)Term項(xiàng)在相同的位置上,0增量常用來表示詞項(xiàng)之間是同義詞。位置增量因子會(huì)直接影響短語查詢和跨度查詢,因?yàn)檫@些查詢需要知道各個(gè)Term項(xiàng)之間的距離。
注:并不是所有的Attribute信息都會(huì)保存在索引中,很多Attribute信息只在分析過程使用,Term進(jìn)索引后部分Attribute信息即丟棄。(如TypeAttribute、FlagsAttribute在索引階段都會(huì)被丟棄)
Lucene Token流 揭秘
lucene Token流的生成,主要依賴TokenStream 的兩個(gè)子類Tokenizer和TokenFilter

Tokenizer類的主要作用:接收Read對(duì)象,讀取字符串進(jìn)行分詞并創(chuàng)建Term項(xiàng)。
TokenFilter類使用裝飾者模式(lucene in action中作者寫的是組合模式,本人竊以為應(yīng)該是裝飾者模式),封裝另一個(gè)TokenStream類,主要負(fù)責(zé)處理輸入的Token項(xiàng),然后通過新增、刪除或修改Attribute的方式來修改Term流。
")
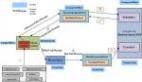
如上圖,當(dāng)Analyzer從它的tokenStream方法或者reusableTokenStream方法返回tokenStream對(duì)象后,它就開始用一個(gè)Tokenizer對(duì)象創(chuàng)建初始Term序列,然后再鏈接任意數(shù)量的TokenFilter來修改這些Token流。這被稱為分析器鏈(analyzer chain)。
一個(gè)簡(jiǎn)單的Analyzer:StopAnalyzer
- protected TokenStreamComponents createComponents(String fieldName,
- Reader reader) {
- //LowerCaseTokenizer接收Reader,根據(jù)Character.isLetter(char)來進(jìn)行分詞,并轉(zhuǎn)換為字符小寫
- final Tokenizer source = new LowerCaseTokenizer(matchVersion , reader);
- //只有一個(gè)分析器鏈StopFilter,來去除停用詞
- return new TokenStreamComponents(source, new StopFilter(matchVersion ,
- source, stopwords));
- }
StopAnalyzer測(cè)試
- String text = "The quick brown fox jumped over the lazy dog";
- System. out.println("Analyzing \"" + text + "\"");
- Analyzer analyzer = new StopAnalyzer(Version.LUCENE_36);
- String name = analyzer.getClass().getSimpleName();
- System. out.println("" + name + ":");
- System. out.print("" );
- AnalyzerUtils. displayTokens(analyzer, text);
- System. out.println("\n" );
結(jié)果輸出
Analyzing "The quick brown fox jumped over the lazy dog"
StopAnalyzer:
[quick] [brown] [fox] [jumped] [over] [lazy] [dog]
原文鏈接:http://www.cnblogs.com/lori/archive/2012/08/24/2654275.html
【編輯推薦】