













漫步云中網絡
閱讀本文前,最好能先了解以下的知識:
了解 OpenStack 將有助于對本文的理解。本文講解的是 Linux 虛擬網絡中的一般原理方法 , 雖不僅限于應用在 OpenStack 之中 , 但本文的實驗是以 OpenStack 為基礎的。OpenStack 是一個開源的 IaaS 云 , 您可以從 devstack 腳本 ( http://devstack.org/) 開始熟悉它。
了解 QEMU 也將有助于對本文的理解。QEMU 是一種支持多種 CPU 的機器模擬器 , 本文采用 QEMU 來創建虛擬機驗證本文中的試驗。
什么是云?
什么是云?我的理解是,為多租戶提供各層次上的服務(如操作系統層、中間件層、應用軟件層等)的可動態水平擴展的服務器集群稱之為云。所以云具有大規模、高可擴展性、按需服務、自動化、節能環保、高可靠性等特點。下圖1從軟件堆棧視角勾畫了云的架構:
圖 1. 云的架構
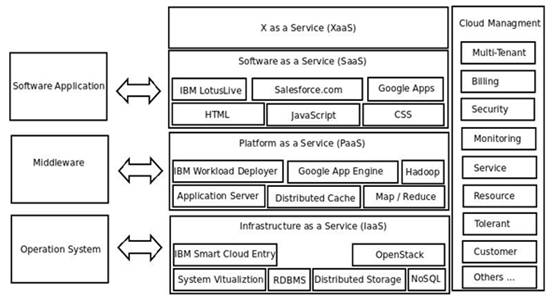
- IaaS, Infrastructure as a Service,基礎設施即服務:您可以簡單理解為將可伸縮的操作系統(虛機或實機)實例作為基礎設施服務賣給多租戶,然后按需計算費用。當然,將操作系統作為基礎設施服務只是 IaaS 中的一種,且是最主要的一種,我怕大家概念混淆所以就只重點提了這種。實際上,只要是基礎設施提供服務了從概念上講都應該叫 IaaS,比如說關系型數據庫,如果是集群部署的話,它也是基礎設施提供服務了,也應該叫 IaaS。這類產品如 IBM 的 Smart Cloud Entry,如開源的 OpenStack。
- PaaS, Platform as a Service, 平臺即服務:您可以簡單理解為將可伸縮的中間件資源作為平臺服務賣給多租戶,然后按需計算費用。舉個例子,如果 SaaS 應用程序的并發瞬間加大的話,PaaS 可以自動實時地啟動一個由 IaaS 提供的操作系統實例,然后自動在它上面部署中間件應用服務器(如 IBM 的 WebSphere),最后再部署一套該 SaaS 應用實例,并自動將它們納入到負載均衡體系之中,從而實現平臺服務的自動伸縮,這就是 PaaS。這類產品如 IBM 的 IWD,如 Google 的 App Engine。
- SaaS, Software as a Service, 軟件即服務:您可以簡單理解為可伸縮的分布式軟件作為軟件服務為用戶提供某種在線服務,如視頻服務,地圖服務等。
- XaaS, X as a Server, 一切即服務:只要是給多租戶按需提供服務都可以叫 XaaS, 像在 OpenStack 中,將網絡部分代碼單獨抽出來組成 Quantum 工程,就可以叫網絡即服務(NaaS, Network as a Service);像使用 xCat 自動部署裸機可以叫裸機即服務(MaaS, Bare-metal as a Service)。#p#
什么是云中網絡?
在傳統的數據中心中,每個網口對應唯一一個物理機;有了云,一臺物理網卡可能會承載多個虛擬網卡。物理網卡與虛擬網卡之間的關系無外乎就是下列三種情況:
一對一,一個物理網卡對應對一個虛擬網卡,是下面一對多情況的一種特例
一對多,一個物理網卡對應多個虛擬網卡,是本文要介紹的情況
多對一,多個物理網對應一個虛擬網卡,即我們常說的 Bonding,用作負載均衡
圖 2. 虛擬網絡的主要內容
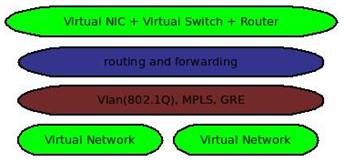
上圖 2 顯示了虛擬網絡的主要內容:
目前,對網絡的虛擬化主要集中在第 2 層和第 3 層
在 Linux 中,第 2 層通常使用 TAP 設備來實現虛擬網卡,使用 Linux Bridge 來實現虛擬交換機
在 Linux 中,第 3 層通常是基于 Iptable 的 NAT,路由及轉發
對于網絡隔離,可以采用傳統的基于 802.1Q 協議的 VLAN 技術,但這受限于 VLAN ID 大小范圍的限制,并且需要手動地在各物理交換機上配置 VLAN;也可以采用虛擬交換機軟件,如 Openvswitch,它可以自動創建 GRE 隧道來避免手動去為物理交換機配置 VLAN。
下面將結合一個生產環境中的網絡實例來講解如何實現一個虛擬網絡。#p#
云中網絡實驗
在生產環境中,按通用做法一般將云中網絡劃分為三大部分,公共網絡、管理&存儲網絡、服務網絡。
公共網絡:用于云向外部租戶提供 API 調用或者訪問
管理網絡:用于云中各物理機之間的通信
存儲網絡:用于 iSCSI 服務端與客戶端之間的流量,一般與管理網絡同
服務網絡:虛機內部使用的網絡
為了將上述網絡的實現原理講清楚,我們選擇了兩臺物理機做實驗,并將采用 NAT、Linux Bridge、VLAN 技術分步實現一個典型的 OpenStack 云的網絡拓撲。當然,這種網絡的原理是通用的,并不僅限于 OpenStack 云。
臺式機 (node1), 雙有線網卡, 將作為控制節點、存儲節點及一個計算節點
筆記本 (node2),一有線網卡,將作為一個計算節點
路由器,家中 ADSL 寬帶出口
交換機 , 用于連接各物理機
值得一提的是,如果采用了 VLAN 技術進行網絡隔離,且想要兩臺物理機上的虛機能夠互訪的話,交換機必須是支持 VLAN 的,且需要手動將交換機相應的端口配置成 Trunk 模式。因為我沒有支持 VLAN 的物理交換機,在本實驗中,我是采用直連線直接連接兩臺實驗機器的。
下圖 3 顯示了實驗網絡拓撲:
圖 3. OpenStack 實驗網絡拓撲
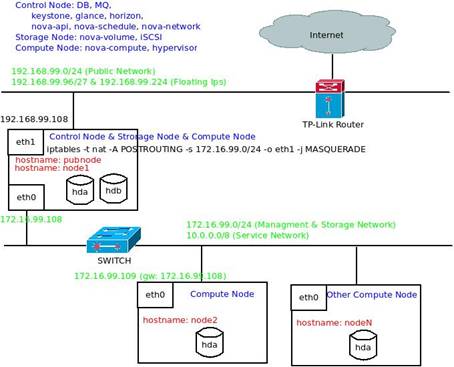
公共網絡:192.168.99.0/24 網段,外網用戶通過公共網絡上提供的服務來訪問云。注意:在實際的生產環境中,公共網絡一般采用外網 IP,因為我沒有外網 IP,所以用 192.168.99.0 網段模擬。將臺式機的一有線網卡 eth1 與 TP-Link 路由器相連即可。
管理&存儲網絡:172.16.99.0/24 網段,管理網絡用于 OpenStack 各組件以及 DB、MQ 之間進行通信;存儲網絡用于存儲節點和需要使用外部存儲的計算節點之間的通信。將臺式機的另一有線網卡 eth0 和筆記本電腦的有線網卡 eth0 連接到交換機即可。
服務網絡:10.0.0.0/8 網段,用于虛機內部。
兩個節點的基本網絡配置如下:
清單 1. node1 的基本網絡配置
- root@node1:/home/hua# cat /etc/network/interfaces
- auto lo
- iface lo inet loopback
- auto eth1
- iface eth1 inet dhcp
- up iptables -t nat -A POSTROUTING -s 172.16.99.0/24 -o eth1 -j MASQUERADE
- auto eth0
- iface eth0 inet static
- address 172.16.99.108
- netmask 255.255.255.0
- network 172.16.99.0
- broadcast 172.16.99.255
清單 2. node2 的基本網絡配置
cat /etc/sysconfig/network-scripts/ifcfg-eth0
- DEVICE=eth0
- HWADDR=00:21:86:94:63:27
- ONBOOT=yes
- BOOTPROTO=static
- USERCTL=yes
- PEERDNS=yes
- IPV6INIT=no
- NM_CONTROLLED=yes
- TYPE=Ethernet
- NETMASK=255.255.255.0
- IPADDR=172.16.99.109
- NETWORK=172.16.99.0
- GATEWAY=172.16.99.108
- DNS1=202.106.195.68
- DNS2=202.106.46.151
我雖然只用了兩臺物理機來模擬實際生產環境的部署模型, 但文中的這種部署結構是典型的,如果是大規模部署的話,只需要將控制節點上的每一個進程(如 DB、MQ、glance、keystone、nova-api、nova-schedule、nova-network 等)分布部署在每一臺物理機即可。想要進一步的 HA 的話,可以:
- 將 DB 配置成集群模式
- 將 MQ 配置成集群模式
- 采用 multi-host 模式,將 nova-network 同時安裝在計算節點 (nova-compute) 上
- 將 nova-api、nova-schedule 這些無狀態的服務也同時部署在計算節點上,再加上負載均衡器分發負載
- 采用多網卡做 Bonding
NAT
node2 可以通過 NAT 方式訪問外網,數據流向如下:
1、node2 中需設置網關指向 node1 的 eth0,例:
- GATEWAY=172.16.99.108
2、在 node1 中打開 ipv4 轉發功能,這樣,node1 會相當于一臺路由器,在 eth0 收到來自 node2 的數據之后,會將數據包轉發到其他網卡 eth1,
- sysctl -w net.ipv4.ip_forward=1
3、在 node1 上設置 NAT 規則,這樣,從 node2(172.16.99.0/24 網段)發出的數據包看來起就像從 node1 的 eth1 發出的一樣:
- iptables -t nat -A POSTROUTING -s 172.16.99.0/24 -o eth1 -j MASQUERADE
Linux Bridge
網橋 ( Bridge ) 工作在二層,了解鏈路層協議,按幀轉發數據。就是交我們常說的交換機,所以連接到網橋的設備處于同一網段。
圖 4. 網橋示例
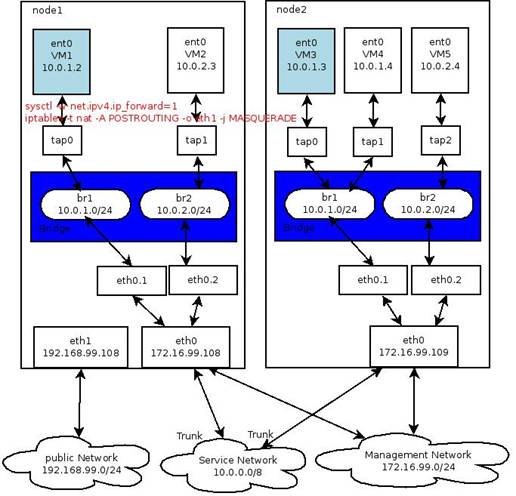
上圖 4 顯示了 node1 網橋中的 VM1 與 node2 網橋中的 VM2 是如何通信的。在 openstack 中,這是典型的 multi-host 模式,即每一個計算節點均部署了網絡服務來提供網關服務。Linux Bridge 充當了交換機的功能,而將 sysctl -w net.ipv4.ip_forward 設置為 1 也相當于 node1 同時充當了一個路由器(路由器的實質就是一個具有多個網卡的機器,因為它的多網卡同時具有這些不同網段的 IP 地址,所以它能將一個網絡的流量路由轉發到另一個網絡)。
網橋,交換機,是用來連接兩個 LAN 的。 是根據 MAC 與端口的映射進行轉發的,而在虛機的網卡都是知道的,若從轉發數據庫知道目的 MAC 地址,以太網幀就只會正確的網橋端口傳輸,否則,就會擴散到網橋設備的所有端口。
因為網橋工作在第二層,所以 eth0.1, tap0, tap1 這些網卡均不需要設置 IP(因為對于上層路由器來說,它們是同一個子網,只需要將 IP 設置在 br1 上即可)。同時, 對 Linux 而言,網橋是虛擬設備,因此,除非將一個或多個真實設備綁定到網橋設備上,否則它就無法接收或傳輸任何東西。所以需要將一個真實設備(如 eth0)或者真實設備的 vlan 接口(如 eth0.1) 加入到網橋。對于前一種情況,將 eth0 加入到網橋之后,eth0 便不再具有 IP,這時候它與 tap0 這些虛擬網卡均通過 br1 處于 10.0.1.0/24 網絡,當然我們也可以為網橋 br1 設置一個別名讓它也具有 172.16.99.0/24 網管網段的 IP 地址。)
下面,我們來實現這個示例網橋,在 node1 與 node2 上分別執行下述腳本(對重要命令的描述請參見注釋):
清單 3. node1 與 node2 的 Linux Bridge 配置腳本
- #!/bin/sh
- TAP=tap0
- BRIDGE=br1
- IFACE=eth0
- MANAGE_IP=172.16.99.108
- SERVICE_IP=10.0.1.1
- GATEWAY=10.0.1.1
- BROADCAST=10.0.1.255
- # 設置物理網卡為混雜模式
- ifdown $IFACE
- ifconfig $IFACE 0.0.0.0 promisc up
- # 創建網橋,并物理網卡加入網橋,同時設置網橋的 IP 為服務網絡網段
- brctl addbr $BRIDGE
- brctl addif $BRIDGE $IFACE
- brctl stp $BRIDGE on
- ifconfig $BRIDGE $SERVICE_IP netmask 255.255.255.0 broadcast $BROADCAST
- route add default gw $GATEWAY
- # 在網橋上設置多 IP,讓它同時具有管理網段的 IP
- ifconfig ${BRIDGE}:0 $MANAGE_IP netmask 255.255.255.0 broadcast 172.16.99.255
注意,上述黑體的一句在 node2 中需要作相應修改,其余不變,如下:
- MANAGE_IP=172.16.99.109
VLAN
圖 4 同樣適用于 VLAN 網絡,下面我們來實現它。在 node1 與 node2 上分別執行下述腳本:
清單 4. node1 與 node2 的 VLAN 配置腳本
- MAC=c8:3a:35:d7:86:da
- IP=10.0.1.1/24
- ip link add link eth1 name eth1.1 type vlan id 1
- ip link set eth1.1 up
- brctl addbr br1
- brctl setfd br1 0
- brctl stp br1 on
- ip link set br1 address $MAC
- ip link set br1 up
- brctl addif br1 eth1.1
- ip addr add $IP dev br1
注意,上述黑體的一句在 node2 中需要作相應修改,其余不變,如下:
- MAC= c8:3a:35:d7:86:db
測試
我們采用 QEMU 創建虛擬機來進行測試,其中網絡部分的配置為:
- <interface type='bridge'>
- <mac address='52:54:00:00:01:89'/>
- <source bridge='br1'/>
- <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
- </interface>
我們使用一個現成的鏡像,下載地址:
- curl http://wiki.qemu.org/download/linux-0.2.img.bz2 -o /bak/kvmimages/linux-0.2.img
在 node1 與 node2 上分別用下列配置定義兩個虛機,注意,下面打粗體的部分(<mac address='52:54:00:00:01:89'/>)在兩個節點中請設置不一樣的值。
cat /etc/libvirt/qemu/test.xml
清單 5. node1 與 node2 的虛機定義文件
- <domain type='qemu'>
- <name>VM1</name>
- <uuid></uuid>
- <memory>393216</memory>
- <currentMemory>393216</currentMemory>
- <vcpu>1</vcpu>
- <os>
- <type arch='i686' machine='pc-1.0'>hvm</type>
- <boot dev='hd'/>
- </os>
- <features>
- <acpi/>
- </features>
- <clock offset='utc'/>
- <on_poweroff>destroy</on_poweroff>
- <on_reboot>restart</on_reboot>
- <on_crash>destroy</on_crash>
- <devices>
- <emulator>/usr/bin/qemu-system-i386</emulator>
- <disk type='block' device='disk'>
- <driver name='qemu' type='raw'/>
- <source dev='/bak/kvmimages/linux-0.2.img'/>
- <target dev='hda' bus='ide'/>
- <address type='drive' controller='0' bus='0' unit='0'/>
- </disk>
- <controller type='ide' index='0'>
- <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/>
- </controller>
- <interface type='bridge'>
- <mac address='52:54:00:00:01:89'/>
- <source bridge='br1'/>
- <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
- </interface>
- <input type='tablet' bus='usb'/>
- <input type='mouse' bus='ps2'/>
- <graphics type='vnc' port='-1' autoport='yes' listen='127.0.0.1'>
- <listen type='address' address='127.0.0.1'/>
- </graphics>
- <video>
- <model type='cirrus' vram='9216' heads='1'/>
- <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/>
- </video>
- <memballoon model='virtio'>
- <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/>
- </memballoon>
- </devices>
- </domain>
然后用上述配置創建虛機(virsh define /etc/libvirt/qemu/test.xml ),接著啟動虛機( virsh start test ),最后設置虛機的 IP 和默認網關, 如下:
VM1:
- ifconfig eth0 10.0.1.2 netmask 255.255.255.0 broadcast 10.0.1.255
- route add default gw 10.0.1.1
VM3:
- ifconfig eth0 10.0.1.3 netmask 255.255.255.0 broadcast 10.0.1.255
- route add default gw 10.0.1.1
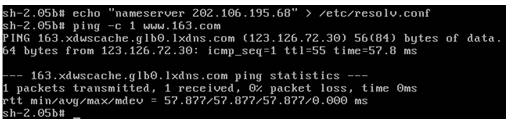
這時候在一虛機上 ping 另一虛機 , 如果能夠 ping 通,成功。若想要 ping 外網的話,還需在 /etc/resolv.conf 文件中添加域名,如下圖 5 所示:
圖 5. 驗證實驗是否成功
 #p#
#p#
OpenStack 云中網絡拓撲配置示例
在掌握了上述基本原理之后,應該不難理解下面 OpenStack 云中的網絡拓撲。
在 OpenStack 中,目前存在著 nova-network 與 quantum 兩種網絡組件。nova-network 僅支持下列三種網絡拓撲:
FlatManager, 不支持 VLAN,也不支持 DHCP 的扁平網絡
FlatDHCPManager,不支持 VLAN,但支持 DHCP 的扁平網絡
VlanManager,支持 VLAN,也支持 DHCP 的 VLAN 隔離網絡
如今 nova-network 的代碼已經全部挪到了 Quantum 工程中,但在網絡拓撲方面,二者的原理是一致的,所以下面只給出一個典型的 nova-network 的網絡配置,有了上面的基礎,現在看這段配置是否會感到很親切呢?
清單 6. /etc/nova/nova.conf 中的網絡配置示例
- ##### nova-network #####
- network_manager=nova.network.manager.VlanManager
- public_interface=eth1
- vlan_interface=eth0
- network_host=node1
- fixed_range=10.0.0.0/8
- network_size=1024
- dhcpbridge_flagfile=/etc/nova/nova.conf
- dhcpbridge=/usr/bin/nova-dhcpbridge
- force_dhcp_release=True
- fixed_ip_disassociate_timeout=30
- my_ip=172.16.99.108
- routing_source_ip=192.168.99.108
相關參數說明如下:
network_manager,目前支持 VlanManager、FlatManager、FlatDHCPManager 三種拓撲
public_interface, 接外網的物理網卡 , floating ip 功能需要用到它
valn_interface, 用于劃分 VLAN 的物理網卡
fixed_range, 服務網絡,即虛機內部所用的網絡地址
my_ip,管理網絡,用于安裝 Openstack 組件的物理機之間的通信。例如:本實驗中的控制節點同時具有外網網絡地址 192.168.99.108 與管理網絡地址 172.16.99.108,另一計算節點的管理網絡地址為 172.16.99.109,所以 my_ip 應該設置為 172.16.99.108
routing_source_ip, NAT 映射后的公共網絡 IP,設置了此參數,會自動執行 NAT 命令:
- iptables -t nat -A POSTROUTING -s 172.16.99.0/24 -o eth1 -j SNAT --to 192.168.99.108
結論
云中網絡一般被劃分為公共網絡、管理網絡 & 存儲網絡與服務網絡三大類。虛擬網絡拓撲一般有 NAT、Bridge、VLAN 三種情形。我們手工一步一步地通過 NAT、Bridge、VLAN 三個試驗簡單實現了一個上述典型的云中網絡。原理都是相通的,您再看 OpenStack 云中網絡或才其他云的網絡時都會倍感親切。












