大數據挖掘云服務
在大數據領域存在諸多挑戰,比如成本和技術,另外服務模式也為企業應用大數據造成了很大的挑戰。企業內部數據集中以后,如何向用戶、企業的前端和后端提供服務呢?日前中國通信學會大數據專家委員會在京成立,該組織是由中國通信學會牽頭組建,我國首個專門研究大數據應用和發展的學術咨詢組織。此次會議上,TechTarget中國有幸聽到中國科學院計算技術研究所何清研究員、博士生導師的演講。何清表示大數據為企業帶來了創新機會,也帶來了挑戰,而關于數據挖掘云服務更是并不簡單。
大數據演化
根據Cisco的預測,2013年互聯網的數據就要達到667EB,而在2015年,在智利的巡天望遠鏡那里也會產品類似的數據,到2013年我們生成1.8ZB這樣規模的數據只需要10分鐘。何清表示:“大數據規模的增長實際上給我們的技術創新,給我們的市場競爭以及生產活動實際上帶來了一個全新的前沿的領域。現在經濟活動的增長根本就離不開數據,我們的創新活動,我們的經濟活動,一刻也離不開數據,離開了數據不可能產生創新。大數據是一個技術問題,但是實際上帶來了更多的商業機會。”
大數據規模從定義來看是一個不斷演化的指標,現在指單一數據集從數10TB到10幾個PB的數據規模。大數據有什么樣的特征呢?何清解釋道,現在有三維表述、四維表述,甚至有五維的表述,對于數據挖掘來說,實際上我們所關注的是大數據里面的這種特征,稠密與稀疏是共存的。表現在數據在局部可能分布極其稠密,但全局來看,我們所收集來的數據又是極其稀疏的。冗余和缺失是并存的,數據是存在大量的冗余的,但是局部的數據又是缺失的。再有一個特征就是靜態和動態互現,就是多元數據的事態持續動態演進。
在大數據上最重要的技術問題是如何理解這么多的數據?如何理解這些大數據?大數據所帶來的技術上的挑戰包括描述與存儲的挑戰,另外一個挑戰就是面臨著挖掘與預測的挑戰。大數據挖掘增加樣本十分容易。但是,數據挖掘算法要降低復雜度非常難。#p#
數據挖掘發展歷程
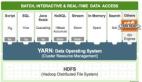
何清認為數據挖掘的發展是以數據存儲和管理技術的發展為基礎的,每當數據存儲與管理技術向前發展一步,相應的數據挖掘技術、系統和平臺也就會得到相應的升級。最初的傳統式、卡片式的數據存儲是不可能實現大數據挖掘的,也不可能用于大數據存儲。現在,HBASE和HDFS這兩種方式為大數據的存儲提供了基礎。在這個基礎上,為大數據的挖掘奠定了基礎。關于大數據管理方面有很多具體的要求,最主要的是大數據的容量問題、數據存儲與管理。大數據管理格式多樣,速度規模復雜性超出傳統的數據管理技術的要求。這時候,甚至也需要內存的數據管理。
在大數據管理基礎上進行數據挖掘,需要使用MapReduce技術。何清表示:“未來我們的數據挖掘不可能在單一的數據倉庫上來做,可能要按需整合多個原信息的邏輯數據倉庫,代替單一數據倉庫的模式。數據挖掘技術的發展從第一代的獨立算法,獨立的系統單個機器向量數據,現在實際上已經發展成了基于云計算的并行數據挖掘與服務。在這個時候,同一個算法分布在多個節點上并行運行,多個算法之間也可以并行來執行。計算資源按照虛擬化技術是按需分配的,其數據管理已經是NoSQL的這些方式,HDFS、HBASE等等。”
大數據挖掘算法需要什么樣的算法呢?根據何清所述,包含了傳統的關聯分析、矩陣分析、異常分析、演變分析等等。大數據管理主要取決于數據的容量,但是大數據挖掘受到算法的復雜度、并行度以及數據存儲速度的制約。大數據挖掘我們要求能夠處理高維、多模態、多類的大數據。
大數據挖掘云服務
目前大數據挖掘面臨諸多方面的挑戰。在算法上要結合不同的分布式計算環境;系統性能方面要考慮減少同步與分布的開銷;而從實現方式來看,并行數據挖掘各節點間是采用高速網絡來連接的,而分布式一般是廣域網。何清解釋道,大數據挖掘要尋求的是具有分布式和并行兩種特征兼具的計算環境,而云計算就提供了這種方式。云計算模式提供的首先是存儲,比如說以Hadoop為例,它實際上是在大型集群上,能夠可靠的存儲大數據的數億級的文件系統,容錯性比較好。由于采用了虛擬化技術,因此簡化了要把計算資源的分配交給編程者的方法
數據挖掘云服務也存在諸多要求。服務要保證可用性、可靠性還有高性能。在這是隱私是安全的,不允許未授權的訪問,也不允許其他人能夠對他所挖掘的數據能夠理解。“除了挖掘者本人以外,或者是本公司以外,其他的即使看到數據,也對他的數據不可理解,要做到這樣。我們實現的途徑按行業來做這個數據挖掘,云服務的平臺。專業的數據挖掘人士就是提供數據挖掘算法服務,大眾和各種組織就成為服務的受益方。我們在這個實現過程當中,肯定離不開虛擬化的技術,我們要做到可信和安全,”何清如是說道。
何清為我們介紹了PDMiner體系結構,這是一個集成各種并行算法的數據挖掘工具平臺,其中的并行計算模式不僅包括算法之間的并行,而且包括算法內部的并行、接口系統和工作流子系統。這個系統做到了并行,而且提供了一系列靈活的算法組件。相對來說,它的容錯性、開放性、可控、可移動都是很好的。在這個基礎之上開發了COMS,實際上是數據挖掘后臺,開發出前臺的云服務界面。用戶通過互聯網就可以去定制數據挖掘任務,可以上載和加密數據,來做到數據挖掘。
最后,何清說道:“我們大數據挖掘要注意兩點,首先是要選擇復雜度低的算法,就是說N方的是很難想像的處理大數據的。我們盡量要把全局最優的問題轉化為局部最優的問題,盡量的使用低階的多項式復雜度算法。我們要使用高效并行的策略,盡量避免使用全局信息。”
專家簡介:何清,中國科學院計算技術研究所研究員,博士生導師,2008年底開發完成了我國最早的基于云計算的并行數據挖掘平臺,用于TB級實際數據的挖掘,實現了高性能、低成本的數據挖掘,先后主持完成多個有關數據挖掘的國家自然科學基金項目和863項目,提出了一系列有效的數據挖掘算法,組織開發的多個數據挖掘軟件獲得了軟件著作權,并實際應用到電信、國家電網、信息安全、環保等多個行業,為企業帶來了可觀的經濟效益和社會效益。