













使用SQL Server分析服務定位目標用戶
如何定位目標用戶,在任何一個業務單元中都是一個很重要的話題,尤其在預算有限的情況下,如何獲得活動的最大收益,目標用戶的定位都是很重要的手段。
本文將介紹如何通過SQL Server分析服務(SSAS)中的數據挖掘功能根據歷史記錄信息來定位目標用戶。
微軟的SQL Server為數據平臺提供了一套完整的解決方案,他不只是一個數據引擎,也提供了很多數據工具和服務,借助其中的分析服務,結合業務系統中的海量歷史數據信息,SQL SERVER就可以幫助我們發現其中的模式和規律,從而對目標數據做預測分析。
在實際中,不同的挖掘模型適用于不同的問題場景,同一個問題模式下可能有多個模型都適合解決這個問題,這樣對于問題的解決來說就多了很多可對比性,從而我們可以根據每個模型預測的準確程度選擇一個最優的模型。
在本文的目標用戶定位的問題上,采用三種挖掘模型進行比較,分別是決策樹,貝葉斯和聚類算法。
本文使用的SQL SERVER版本是2012,示例數據庫是Adventure Works的數據倉庫,關于如何獲取以及部署這個示例數據倉庫,可以參考我的這篇隨筆:
http://www.cnblogs.com/aspnetx/archive/2013/01/30/2883831.html
首先,建立數據挖掘項目,打開SQL DATA TOOLS,也就是Visual Studio 2010的那個Shell。
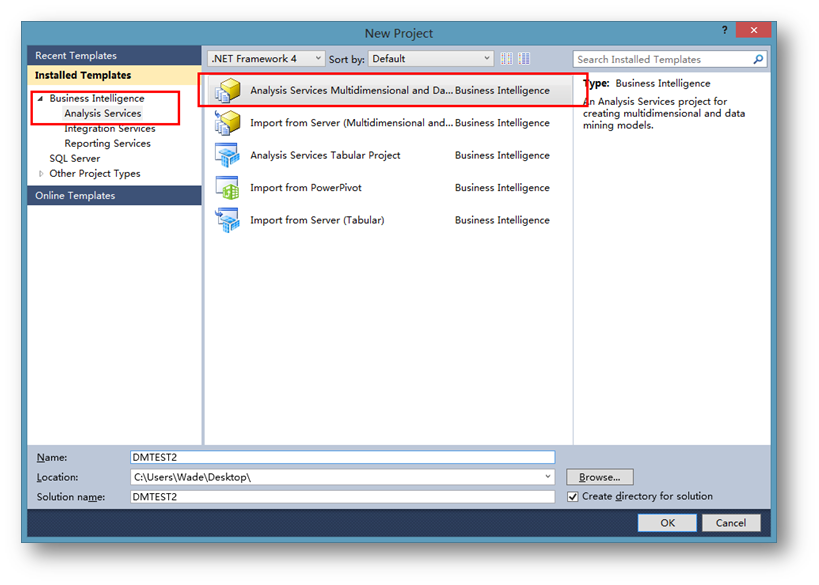
新建一個多維和數據挖掘的分析服務項目。
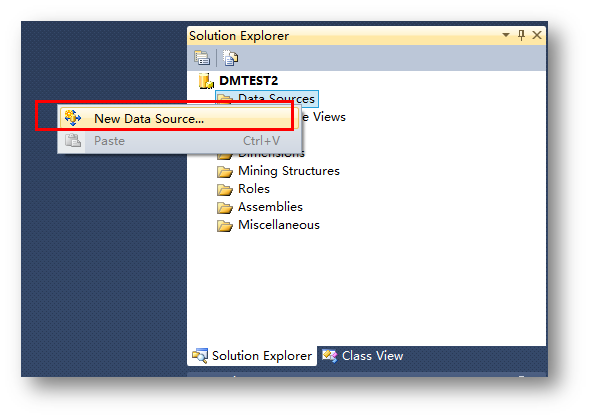
項目建立完畢后,新建數據源連接。
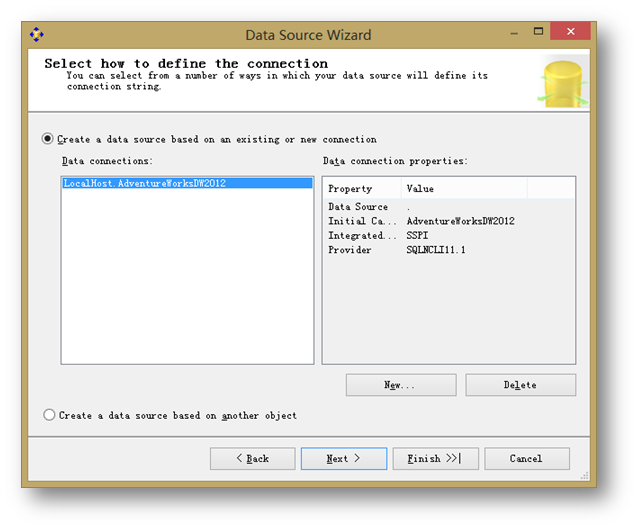
選擇部署好的Adventure Works DW連接。
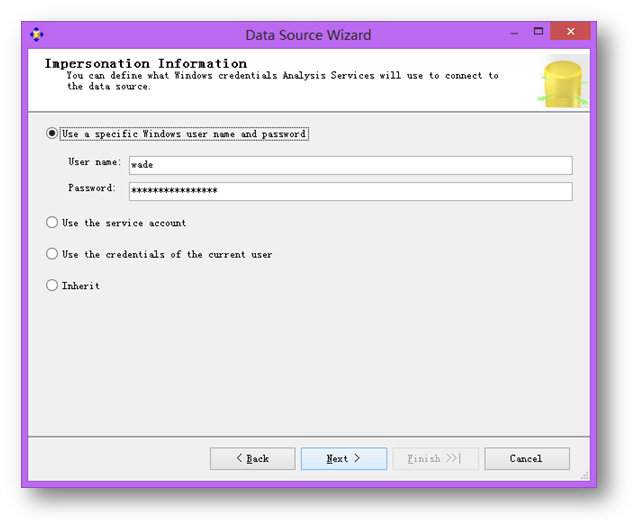
輸入模擬身份信息,本演示用為了簡便直接使用本地管理員賬戶(當然生產環境中是不建議這么做的)。

#p#
為數據源連接起名。
新建數據源視圖。
選擇剛才建立的數據源連接。
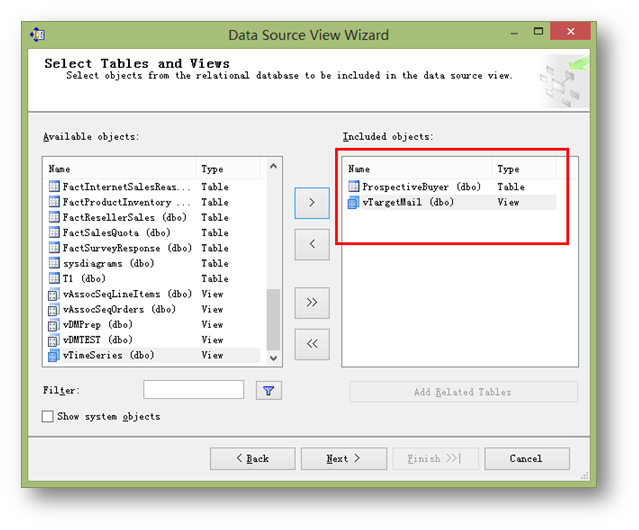
從左邊可選對象列表中選取兩個對象,一個是表ProspectiveBuyer,一個是視圖vTargetMail。

為數據源視圖取名。
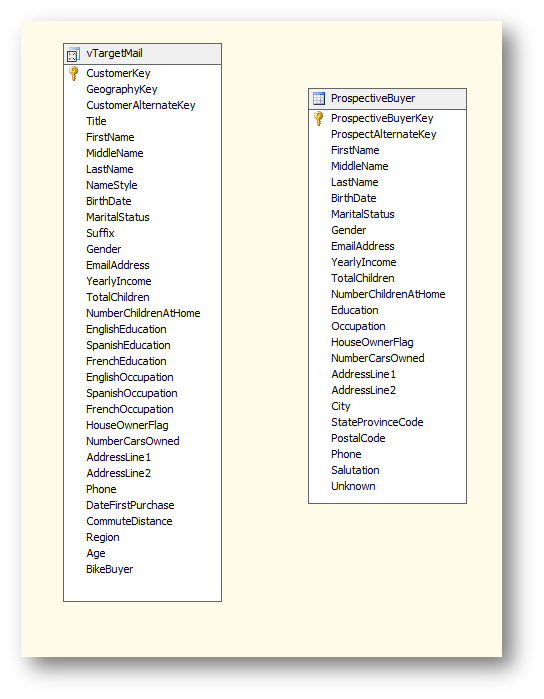
可以在數據源視圖中看到添加進來的兩個表。
#p#
其中左面的表是在數據倉庫經過整合的一批數據,用來訓練和驗證模型。右面的表是待預測的表,將在模型生成完畢后對這個表里的數據進行預測。
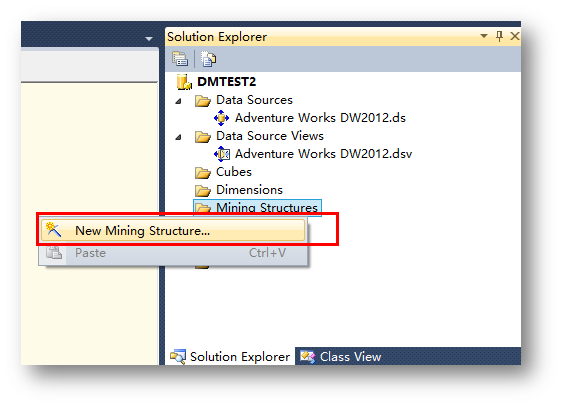
新建挖掘結構。
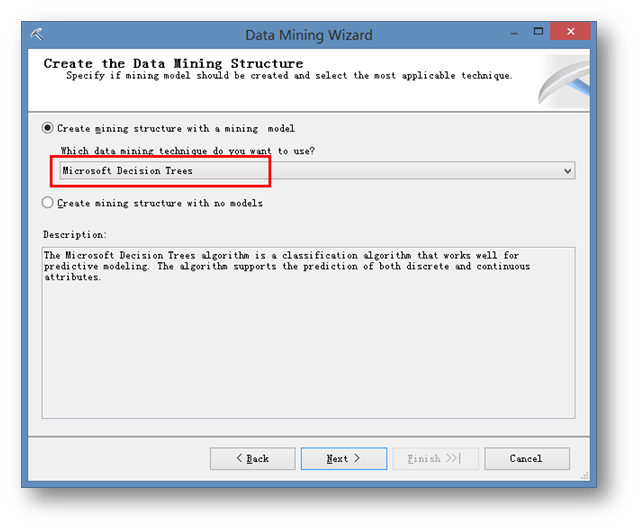
同時為挖掘結構指定一個挖掘模型,這里選擇決策樹模型。需要留意的是,一個挖掘結構可以有很多挖掘模型,不過在通過工具創建一個挖掘結構的時候需要指定一個挖掘模型。
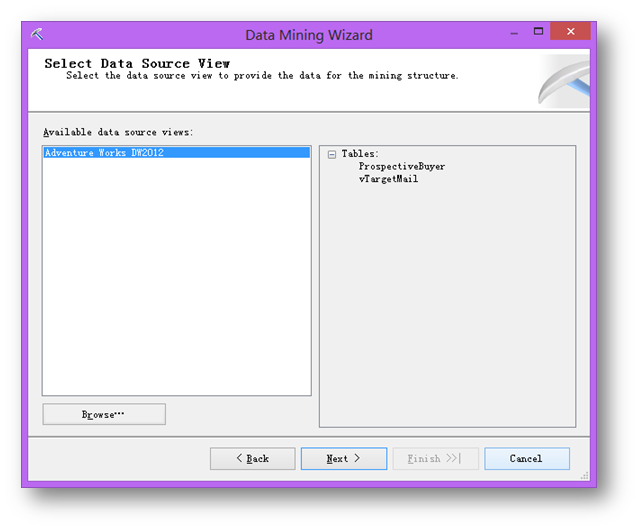
選擇剛才建立的數據源視圖。
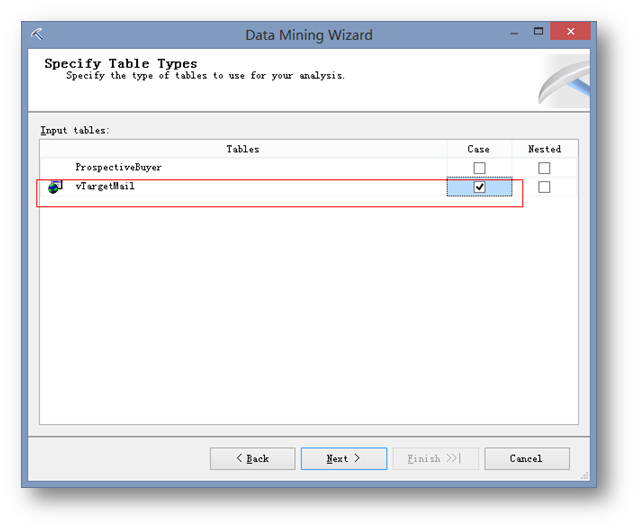
選取事例表vTargetMail。ProspectiveBuyer是后續要用來進行預測的,所以這里先忽略這個表。
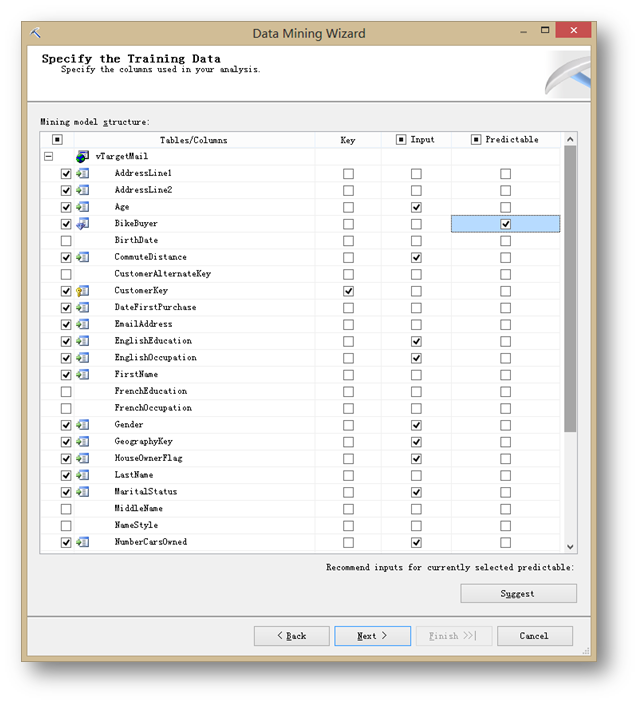
首先,在Key列一欄選擇CustomerKey,用來指定鍵列。
#p#
然后選擇輸入列:
Age
CommuteDistance
EnglishEducation
EnglishOccupation
Gender
GeographyKey
HouseOwnerFlag
MaritalStatus
NumberCarsOwned
NumberChildrenAtHome
Region
TotalChildren
YearlyIncome
最后,選中以下列表左側需要選擇的列。這些列不作為模型的考慮元素,但是會用在模型的鉆取結果上。
AddressLine1
AddressLine2
DateFirstPurchase
EmailAddress
FirstName
LastName
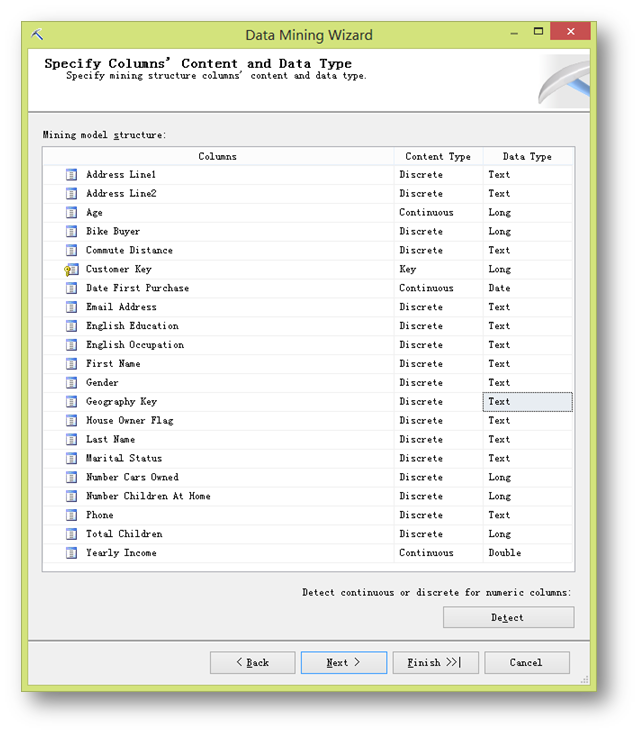
確認內容類型,這里有兩處需要更改,一處是Geography Key改為Discrete離散型的,以及BikeBuyer改為discrete離散型的。
關于內容類型的參考:
http://technet.microsoft.com/zh-cn/library/ms174572
關于數據類型的參考:
http://technet.microsoft.com/zh-cn/library/ms174796

設定測試數據的比例。也就是說,在所有的歷史數據中,這里將決定,有多少數據用來訓練模型,有多少數據用來對模型進行準確度測試。
這里可以指定百分比或者最大測試事例數,當兩個都有配置的時候,系統會取最小測試事例集合的配置。
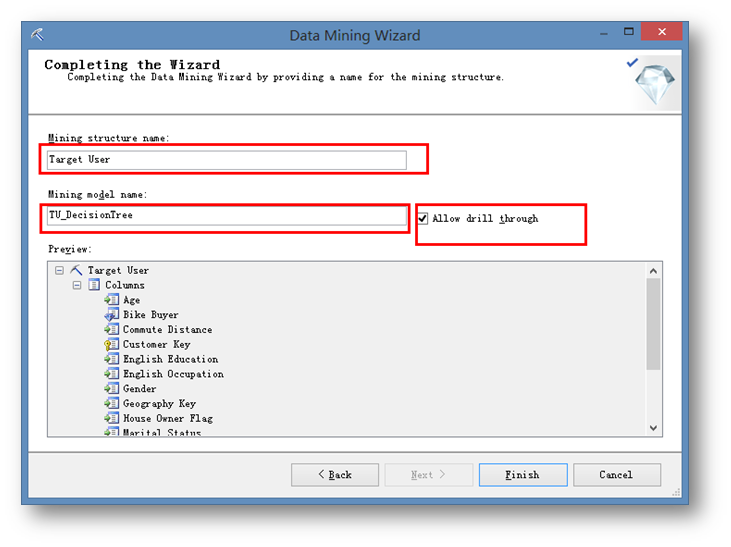
為挖掘結構和挖掘模型取名,并且選中允許鉆取的選項。
#p#

至此一個決策樹模型生成完畢。
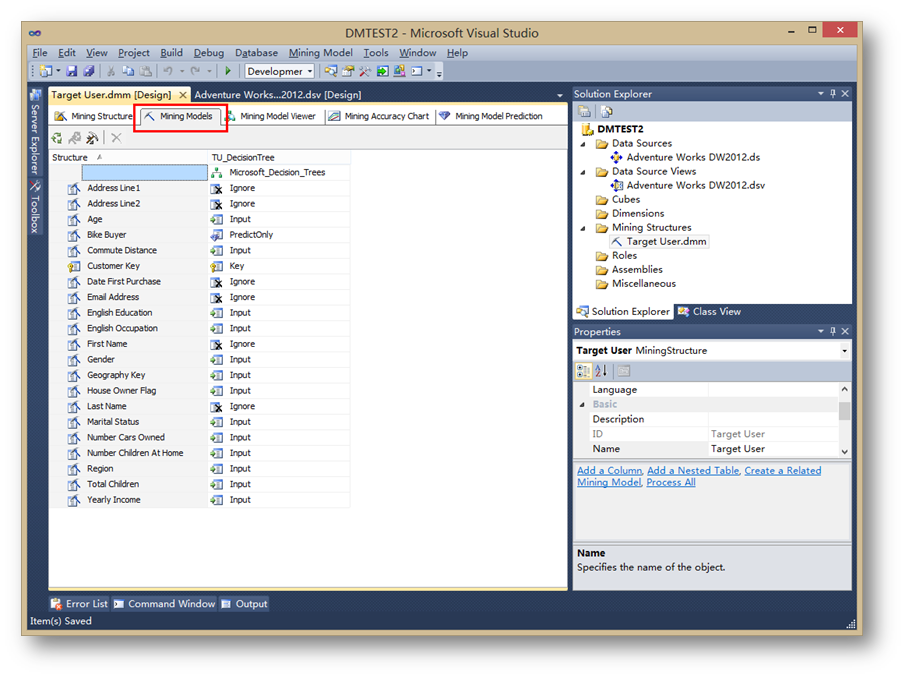
點擊挖掘模型標簽,可以更直觀的看到挖掘結構和挖掘模型的結構。
接下來根據已經創建好的挖掘結構,創建其它挖掘模型。
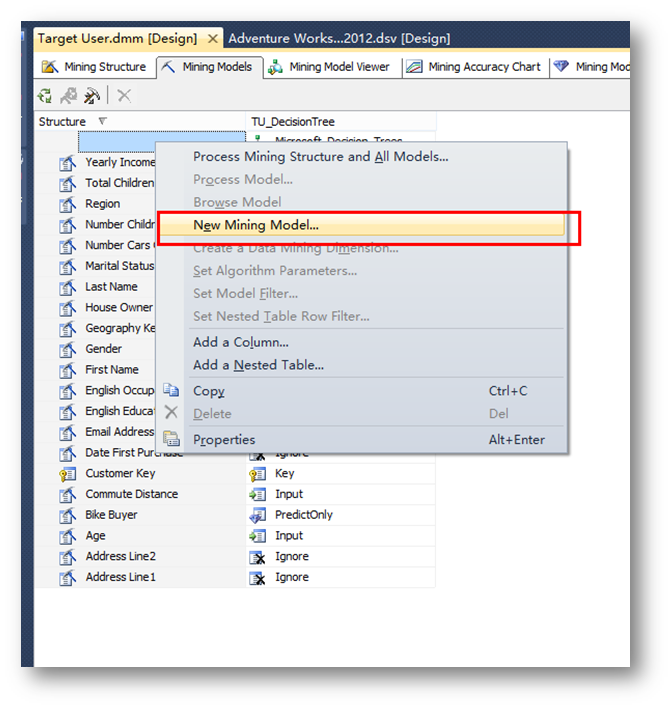
右鍵點擊挖掘結構,選擇新建挖掘模型,為挖掘結構添加另外幾個模型用于對預測結果進行比對。
#p#
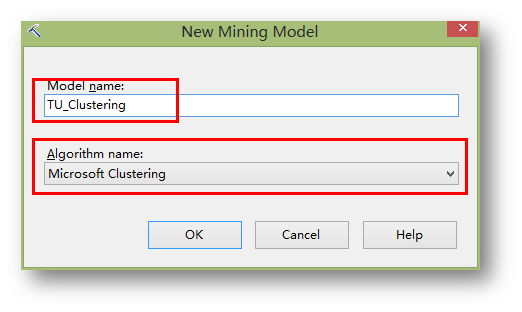
為挖掘模型取名,并在算法中選擇聚類算法。
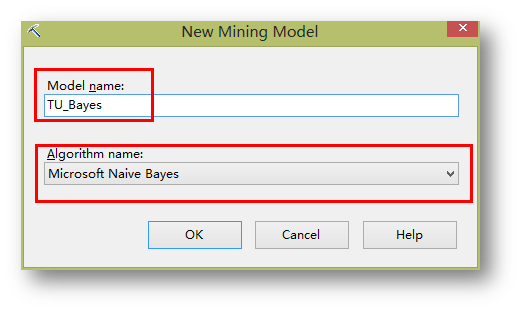
按照同樣的方法,再創建一個貝葉斯模型。
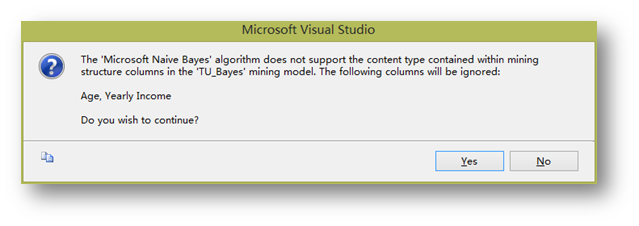
由于貝葉斯模型不支持連續變量,所以這里會出現提示。繼續即可。

可以看到創建好的三個模型,并且每個模型中各個字段的用法。
點擊工具欄上的處理按鈕,對模型進行部署和處理。
第一次部署或者項目有過修改都會出現這樣一個提示,點Yes。
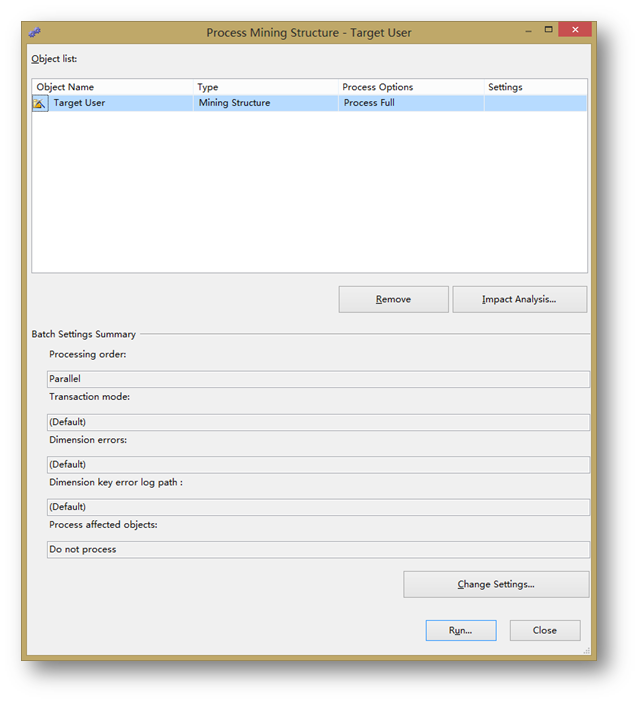
處理界面,直接點擊Run開始處理。
#p#
處理過程中,處理的時間取決于訓練數據的大小以及機器的硬件性能。當然對于Adventure Works的這個示例來說,通常就是10多秒的事。
挖掘結構處理完畢后,下面來簡單瀏覽一下各個挖掘模型。點擊挖掘模型瀏覽器標簽。然后在Mining Mode中選定TU_DecisonTree決策樹模型。
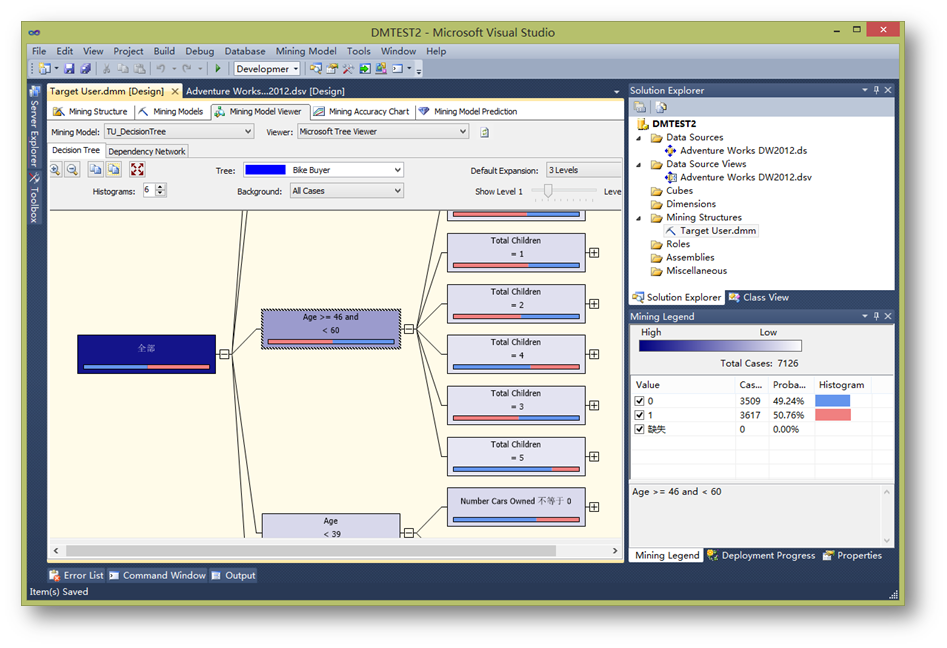
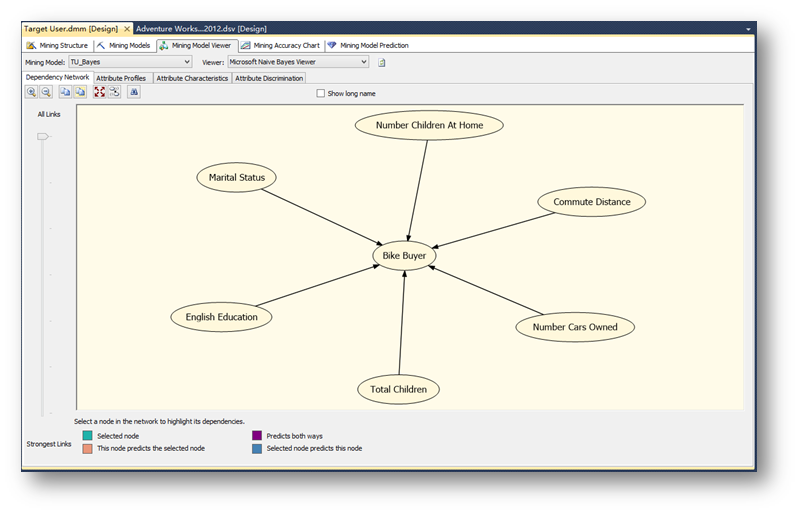
可以看到,Microsoft 決策樹算法通過在樹中創建一系列拆分來生成數據挖掘模型。 這些拆分以"節點"來表示。 每當發現輸入列與可預測列密切相關時,該算法便會向該模型中添加一個節點。 離根節點距離越近的屬性,說明這個屬性的變化對預測列的影響變化更大。
右鍵每一個節點,可以鉆取到詳細信息。
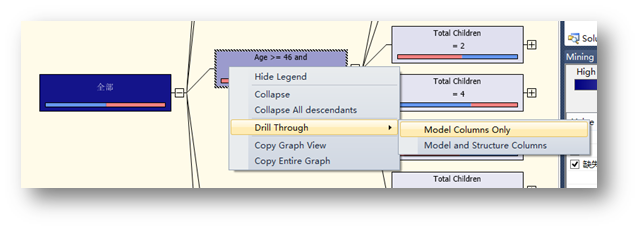
選擇第一項,查看模型包含的列:
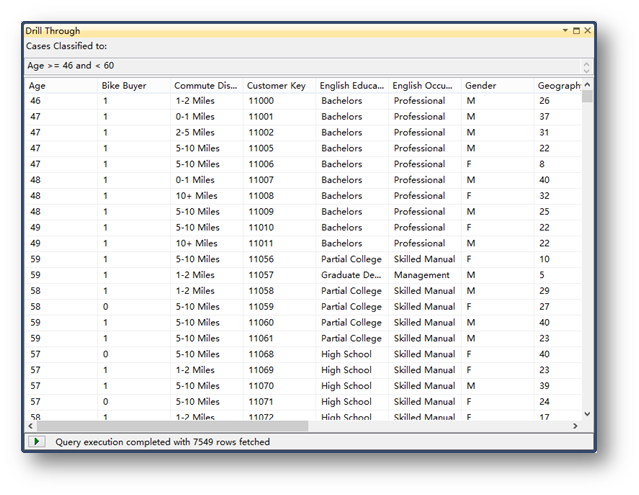
也可以選擇鉆取模型和挖掘結構模型的信息,這樣前面在左側定義的列就會顯示出來,方便定位詳細信息。
#p#
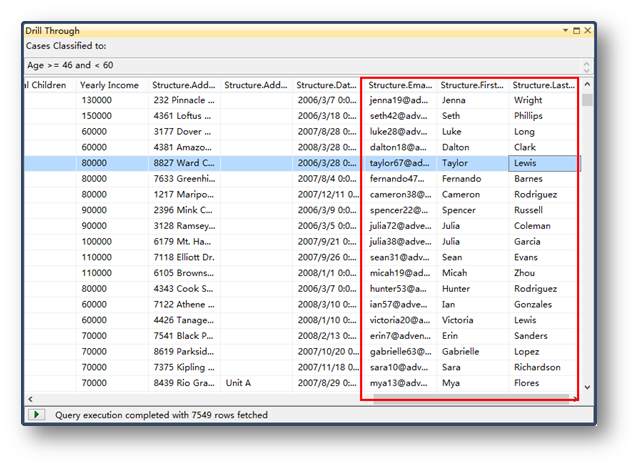
瀏覽聚類分析模型,這里可以看到各個分類之間的關系,通過拖動左面的滑塊可以看到相互之間關系的強弱。

瀏覽貝葉斯模型,在途中可以看到是否是目標客戶,模型分析出的幾個關鍵因素,也可以通過左邊的話快查看這些因素有強到弱的關系。
接下來,將對各個模型進行測試。雖然對于一個問題可以應用很多模型來解決,但往往只有一個才是最優的,效率最高的。對模型的測試主要是用到提升圖。
首先,點擊Mining Accuracy Chart選項卡,確定用于提升圖的數據是Use mining model test cases。
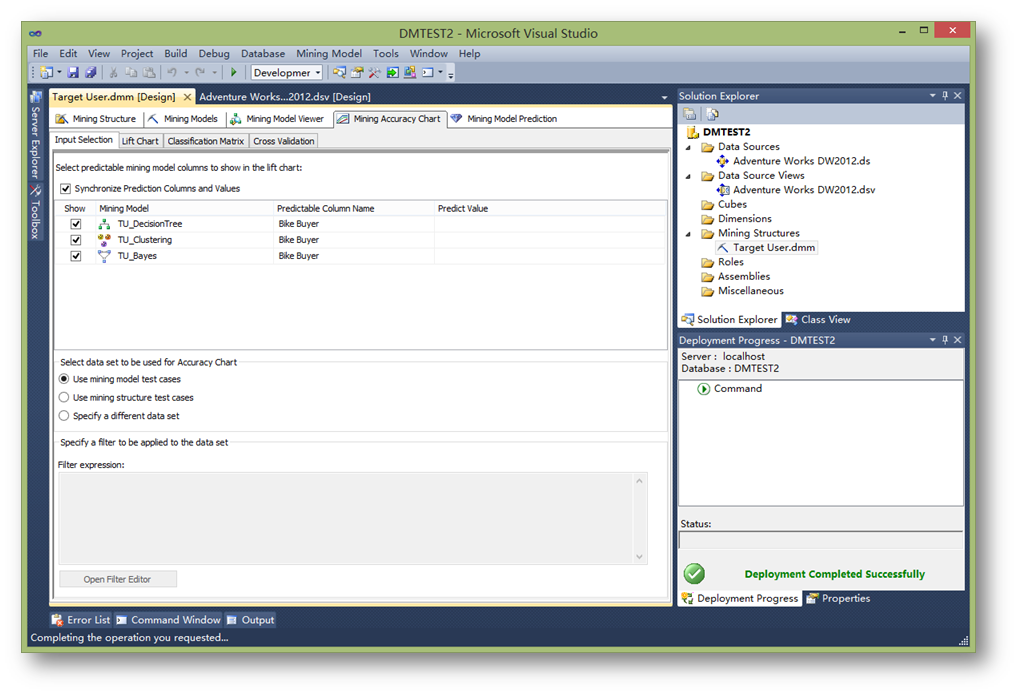
然后點擊Lift Chart標簽,系統會顯示根據測試數據生成的提升圖。
#p#
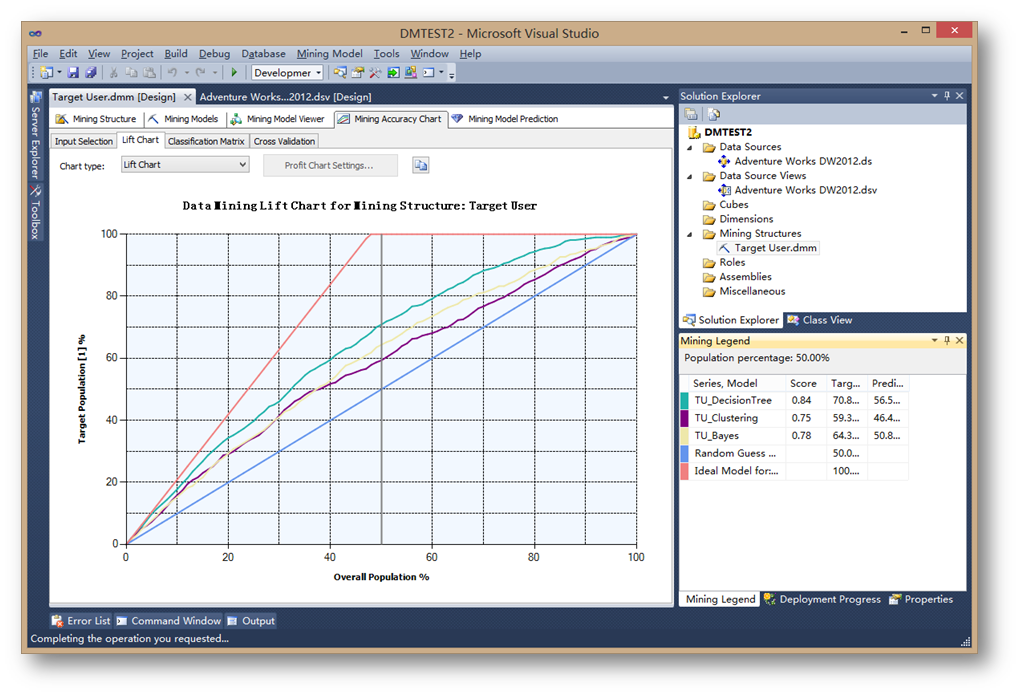
從提升圖的結果來看,決策樹的預測性能明顯高于其它模型。
關于提升圖,首先,對角線是隨機概率的結果,最上面的線是最佳理想的預測結果,所以實際的模型預測效率都是介于這兩條線之間。
關于提升圖的更多信息可以參考微軟的這篇文檔:
http://technet.microsoft.com/zh-cn/library/ms175428
在已經確定決策樹模型是最優模型之后,如果還希望根據性別的不同分析購買風格的差異,可以創建篩選模型。
首先,回到Mining Models選項卡,右鍵單擊創建好的決策樹模型,選擇新建模型。
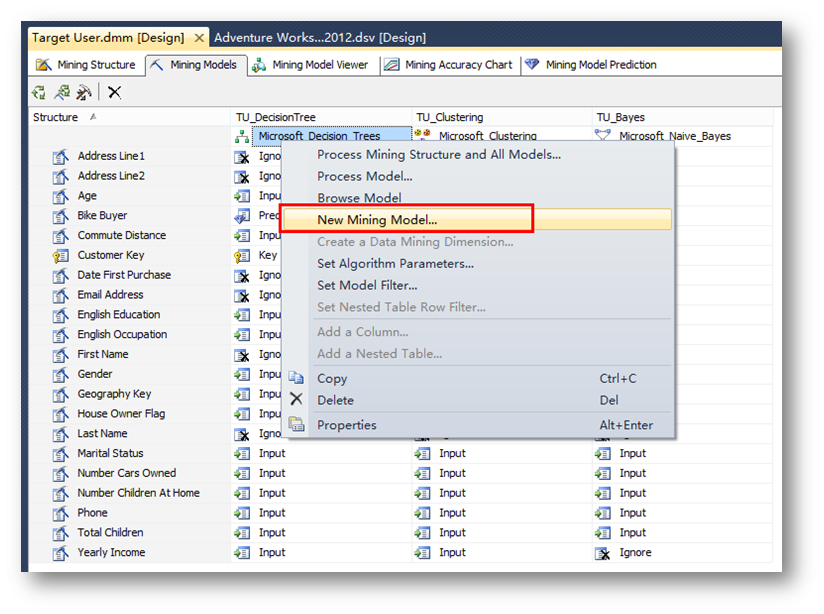
在彈出的界面中,給新模型取一個名:TU_DecisionTree_Male,算法選擇Microsoft 決策樹。
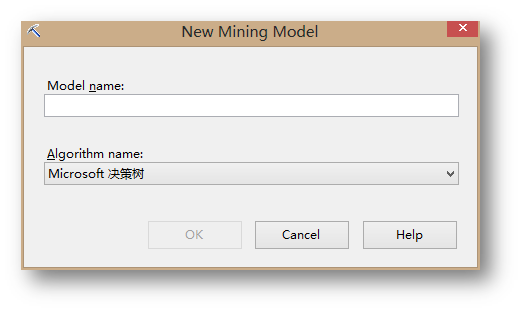
點擊OK完成后,右鍵點擊新建的模型,選擇Set Model Filter…
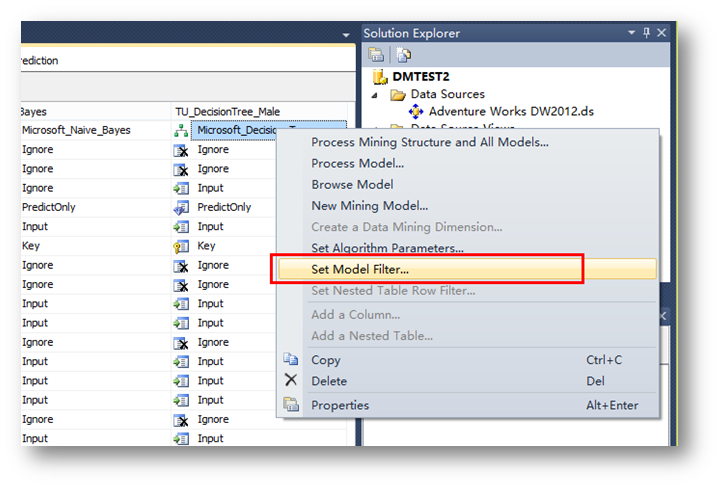
在Conditions中選擇Gender = M。
#p#
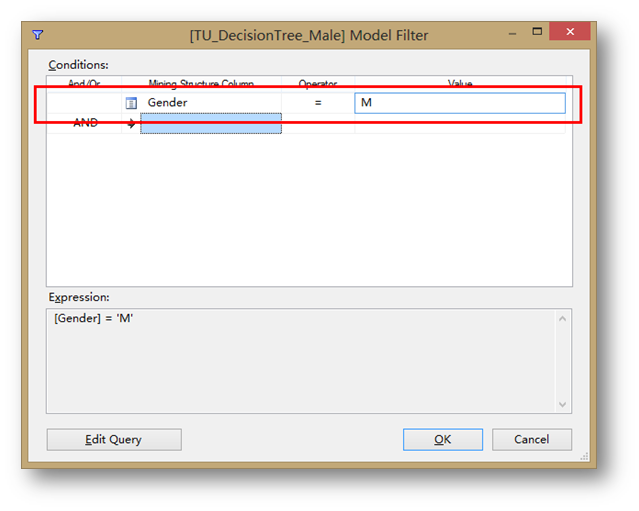
按照同樣的方法,建立另外一個TU_DecisionTree_Female,Model Filter中 Conditions選擇Gender = F。
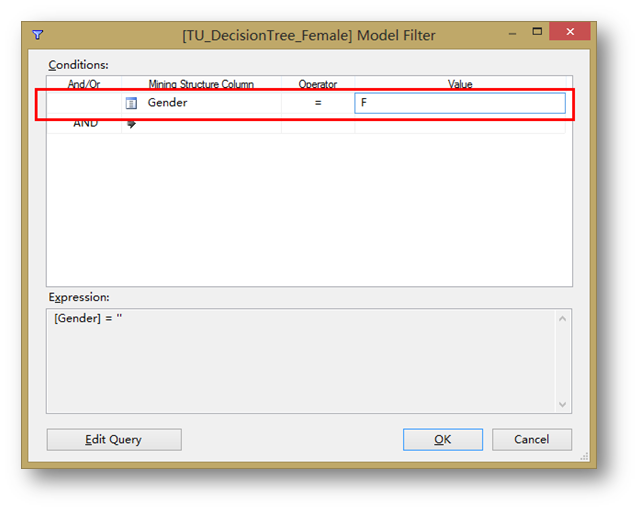
創建完兩個新篩選模型后,點擊提升圖。將Predict Value設置成1,以驗證目標客戶預測的性能。
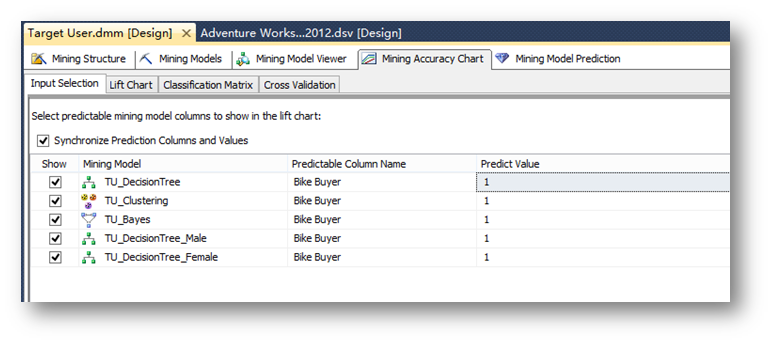
點擊Lift Chart查看提升圖。
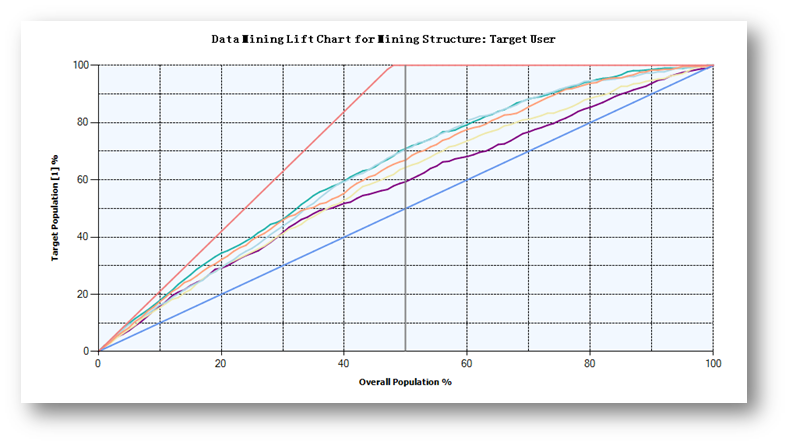
可以看到,三個決策樹模型的預測性能都是高于其它模型的。
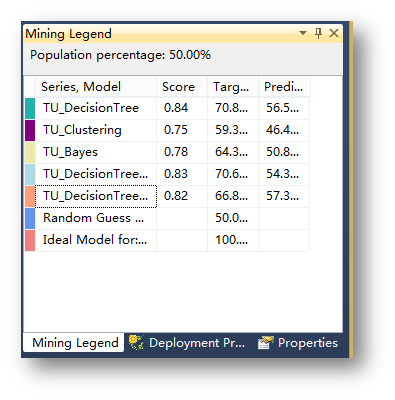
模型測試完畢,可以判斷決策樹是基于定位目標用戶最佳的預測模型。接下來是用決策樹模型對一個表中的數據進行預測。
#p#
首先,選擇Mining Model Prediction選項卡。
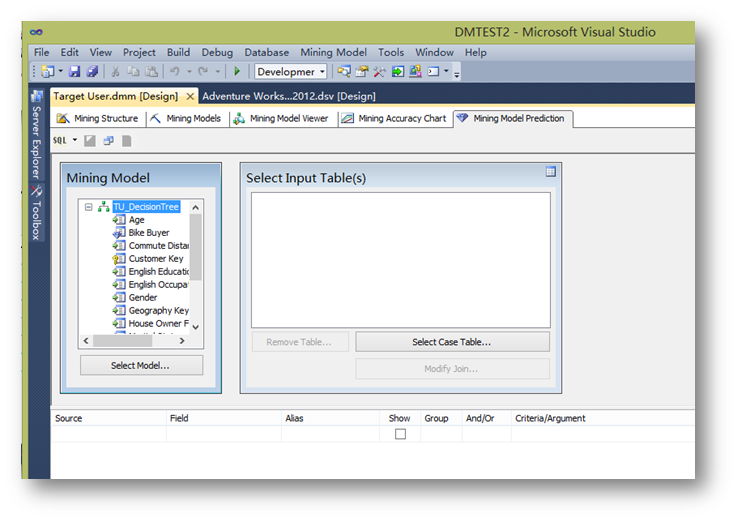
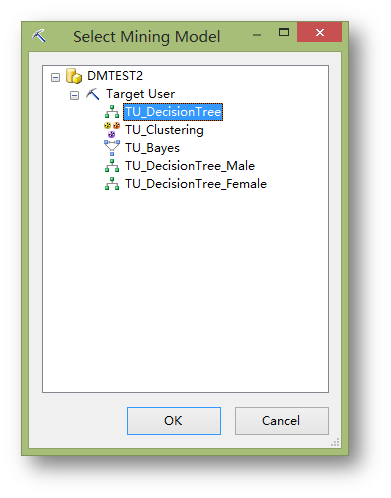
點擊Select Model…選擇前面建立的TU_DecisionTree模型。
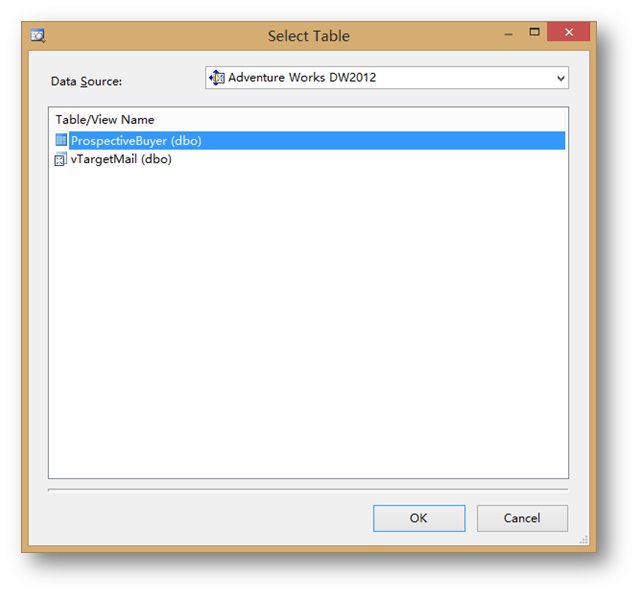
然后點擊Select Case Table…選擇實例表ProspectiveBuyer。
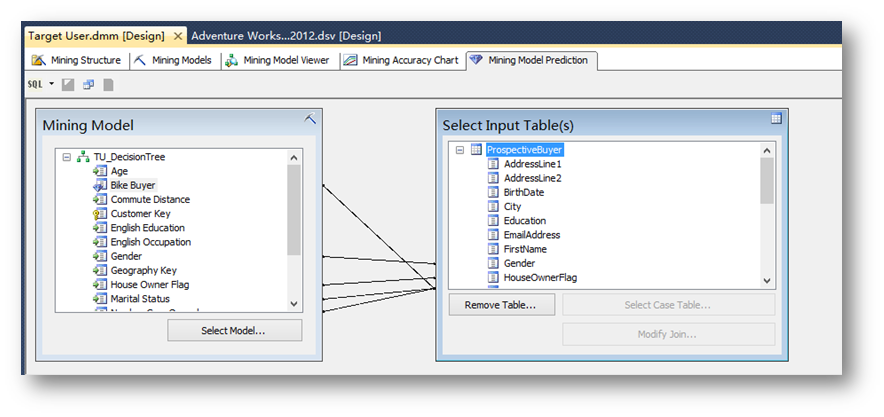
點擊OK后,可以看到在表ProspectiveBuyer中并沒有對應的Age列,而這一列是在預測過程中需要參考的一個重要列,所以回到數據源視圖,在ProspectiveBuyer表里加入一個計算列。
右鍵單擊表ProspectiveBuyer點擊New Named Calculation…
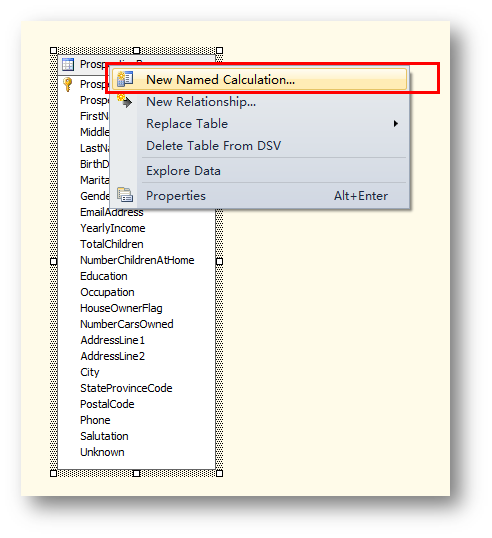
#p#
在彈出的界面中為計算成員取名并填寫計算公式:
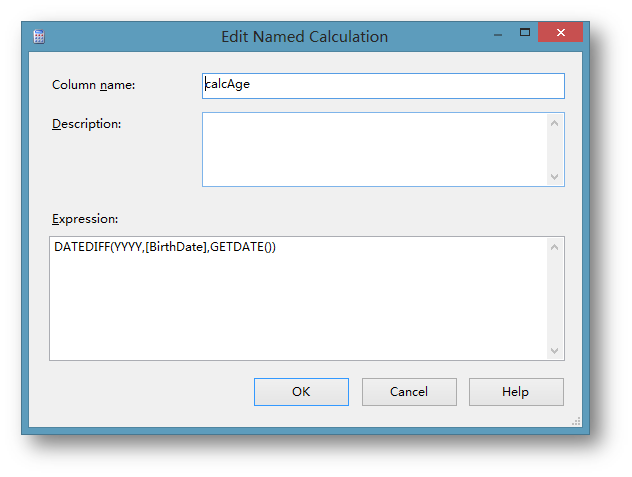
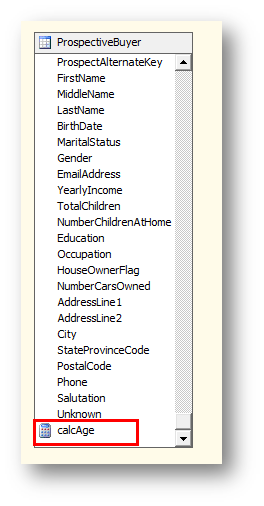
可以看到新建的列已經添加到字段列表的末尾。在數據源視圖中添加的列可以理解為在物理視圖和表上,在項目里建立的視圖,所以實際上并沒有對實際的表或者視圖的結構進行更改。
然后回到預測界面,將Mining Model中的Age列拖拽到Select Input Table(s)中剛建立好的CalAge列。
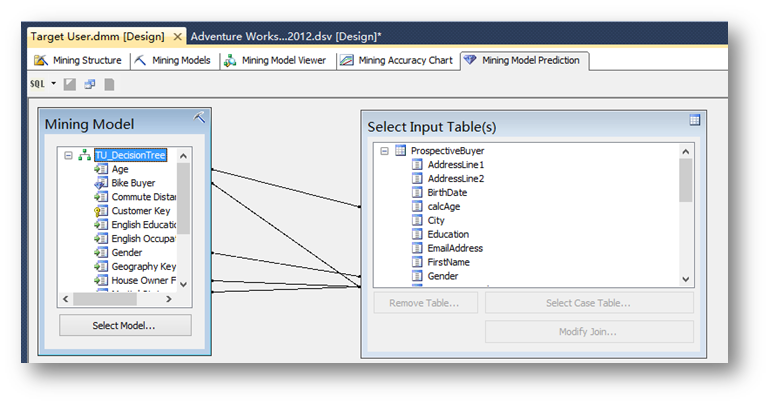
點擊界面左上角的小圖標,切換到Design設計模式。
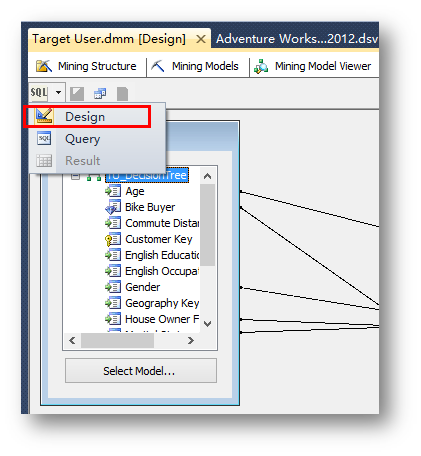
在下方的網格列表中,Source選擇Prediction Function。
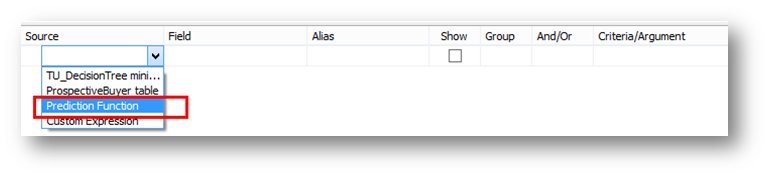
指定一個別名Result,然后在Criteria/Argument中,把Bike Buyer字段從上方的Mining Model中拖拽過來。

然后在下方的網格列表中,Source選擇TM_DecisionTree,Filed選擇Bike Buyer。最后在下面幾行中Source指定ProsepectiveBuyer然后Filed中依次指定calAge, FirstName, LastName和AddressLine1以及AddressLine2。
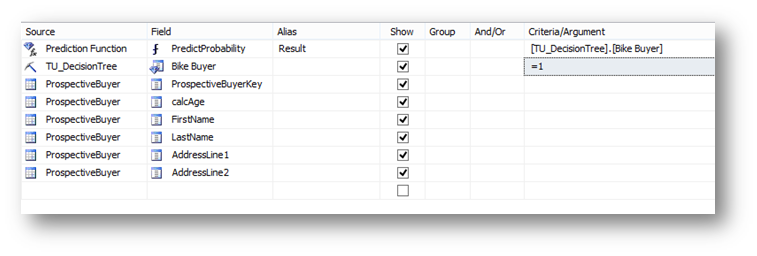
#p#
點擊工具圖標切換到Result結果視圖。
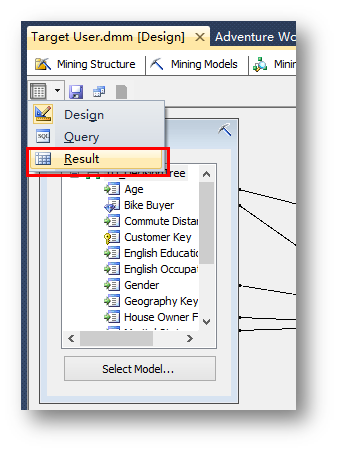
可以看到目標數據的預測結果。
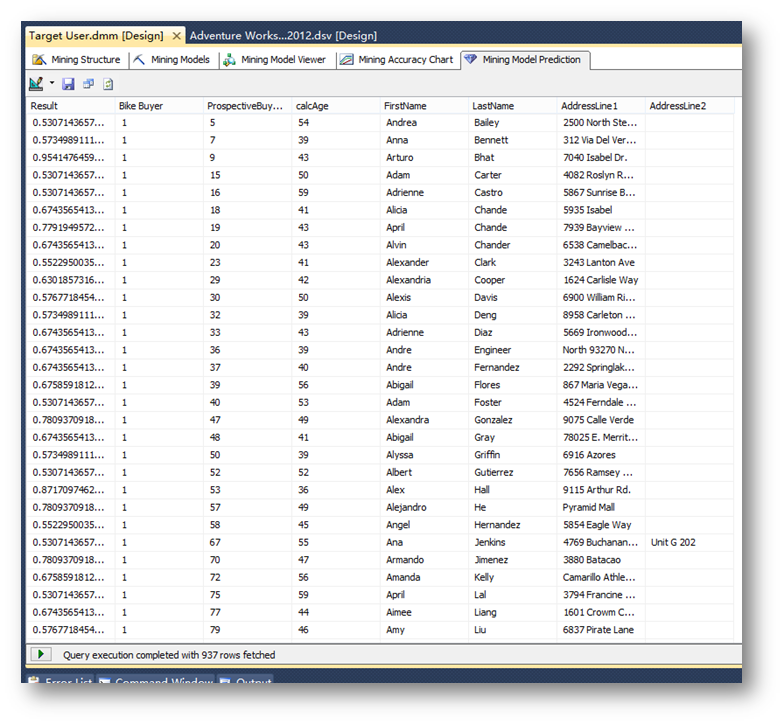
另外,也可以切換到Query模式查看系統生成的DMX語句。
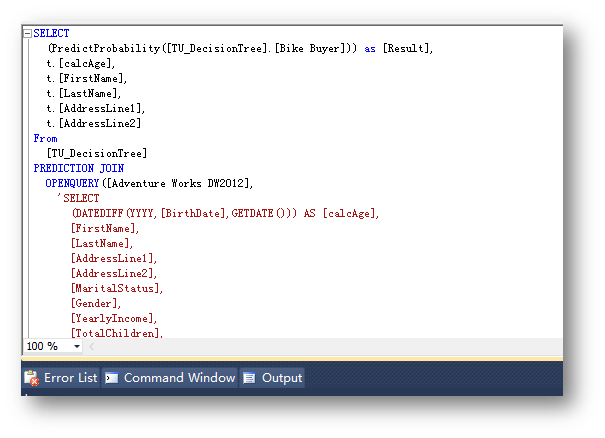
至此,通過建立數據挖掘模型,并且選擇最優模型之后,對目標用戶列表里的數據進行了預測,從而幫助用戶更有效率的確定了目標潛在用戶。這樣的預測在某些場景下是非常有用的,比如企業最近要做一個活動推廣,但是費用成本不足以給所有的客戶進行推廣,所以這個時候決定給哪些客戶來推送推廣服務就可以有效的降低推廣活動的成本并且獲取最高的推廣收益。
以上,如何使用SQL Server分析服務來定位目標用戶介紹完畢。關于如何將這個數據挖掘的功能加入到現有的項目中,可以參考我寫的另外一篇關于購物籃推薦的系列隨筆,里面會有介紹如何構建Web服務以及編寫簡單的應用訪問這個服務從而使用數據挖掘的功能。
原文鏈接:http://www.cnblogs.com/aspnetx/archive/2013/04/05/3000448.html










