













Tachyon:吞吐量超過HDFS 300多倍
Hadoop足夠快嗎?美國加州大學伯克利分校的AMPLab基于Hadoop的核心組件開發出一個更快的版本Tachyon。AMPLab從底層重建了Hadoop平臺,“沒有最快,只有更快”。
AMPLab在大數據領域最知名的產品是Spark,它是一個內存中并行處理的框架,Spark的創造者聲稱:使用Shark運行并行處理Job速度要比MapReduce快100倍。又因為Spark是在內存運行,所以Shark可與Druid或者SAP's HANA系統一較高下。Spark也為ClearStory下一代分析和可視化服務提供處理引擎。如果你喜歡用Hive作為Hadoop的數據倉庫,那么你一定會喜歡Shark,因為它代表了“Hive on Spark”。
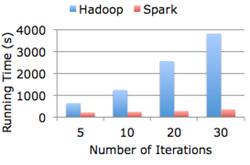
AMPLab的最新目標就是Hadoop分布式文件系統(HDFS),不過HDFS在可用性和速度方面一直受人詬病,所以AMPLab創建了Tachyon( 在High Scalability上非常奪目,引起了Derrick Harris的注意),“Tachyon是一個高容錯的分布式文件系統,允許文件以內存的速度在集群框架中進行可靠的共享,類似Spark和 MapReduce。通過利用lineage信息,積極地使用內存,Tachyon的吞吐量要比HDFS高300多倍。Tachyon都是在內存中處理緩存文件,并且讓不同的 Jobs/Queries以及框架都能內存的速度來訪問緩存文件”。
當然,AMPLab并不是第一個對HDFS提出質疑的組織,同時也有很多商業版本可供選擇,像Quantcast就自己開發了開源文件系統,聲稱其在運行大規模文件系統時速度更快、更高效。
誠然,AMPLab所做的工作就是打破現有商業軟件的瓶頸限制。如果碰巧破壞了現狀,那么就順其自然吧!不過,對于用戶來說,AMPLab只是為那些尋找合適工具的人員提供了一種新的選擇,AMPLab的合作伙伴和贊助商包括谷歌,Facebook,微軟和亞馬遜網絡服務,它們當然非常樂意看到這些新技術,如果很有必要的話。
AMPLab的其他項目包括PIQL,類似于一種基于鍵/值存儲的SQL查詢語言;MLBase,基于分布式系統的機器學習系統;Akaros,一個多核和大型SMP系統的操作系統;Sparrow,一個低延遲計算集群調度系統。























