Project Savanna:讓Hadoop運(yùn)行在OpenStack之上
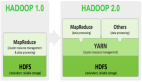
Apache Hadoop基本上已經(jīng)成為MapReduce實(shí)現(xiàn)的產(chǎn)業(yè)標(biāo)準(zhǔn),并且被各個(gè)機(jī)構(gòu)廣泛采用,而Savanna項(xiàng)目旨在讓用戶可以在OpenStack上運(yùn)行和管理Hadoop集群。值得一提的是,Amazon通過EMR(Elastic MapReduce)提供Hadoop服務(wù)已達(dá)數(shù)年之久。
用戶需要給Savanna提供一些信息來建立集群,比如Hadoop版本、集群拓?fù)洹⒐?jié)點(diǎn)硬件詳情以及一些其它的信息。在用戶提供這些參數(shù)之后,Savanna將幫助用戶在幾分鐘之內(nèi)建立起集群,同樣還可以幫助用戶根據(jù)需求對集群進(jìn)行擴(kuò)展(增加或者刪除工作節(jié)點(diǎn))。
方案針對以下幾種用例:
為Dev和QA快速配置Hadoop集群
利用通用OpenStack IaaS云中從未使用過的計(jì)算能力
為專用或突發(fā)性的分析負(fù)載提供“分析即服務(wù)”(類似AWS中的EMR)。
主要特性如下:
作為OpenStack組件出現(xiàn)
通過REST API進(jìn)行管理,用戶界面作為OpenStack Dashboard的一部分。
支持多種Hadoop分布:
作為Hadoop安裝引擎的可插拔系統(tǒng)。
集成了提供商特定的管理工具,比如Apache Ambari或者Cloudera Managent Console。
Hadoop配置的預(yù)定義模板來,具備配置參數(shù)功能。
細(xì)節(jié)說明
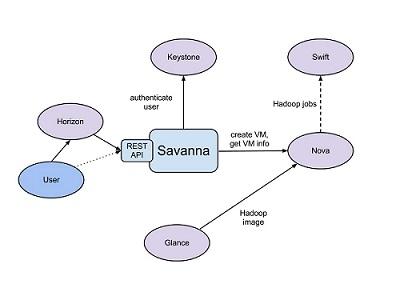
Savanna產(chǎn)品主要于以下幾個(gè)OpenStack組件進(jìn)行通信:
Horizon——提供GUI以使用所有Savanna的特性。
Keystone——認(rèn)證用戶并提供安全令牌,用以與OpenStack通信,用以給用戶分配特定的OpenStack權(quán)限。
Nova——為Hadoop集群配置虛擬機(jī)。
Glance——用于儲(chǔ)存Hadoop虛擬機(jī)鏡像,每個(gè)鏡像都包含了已安裝的OS和Hadoop;預(yù)安裝的Hadoop應(yīng)該給予我們在節(jié)點(diǎn)布置上的便利。
Swift——可以作為需要進(jìn)行Hadoop作業(yè)的預(yù)存儲(chǔ)。
常規(guī)工作流
Savanna會(huì)根據(jù)用例給用戶提供兩種不同抽象等級的API和UI:集群配置和分析作為服務(wù)。
集群快速配置的工作流程包括以下選項(xiàng):
選擇Hadoop版本
選擇包含或者不包含預(yù)安裝Hadoop的基礎(chǔ)鏡像
對于未預(yù)安裝Hadoop的基礎(chǔ)鏡像,Savanna將提供整合了供應(yīng)商工具的可插拔部署引擎。
定義集群配置,包括集群的大小和拓?fù)洌⑶以O(shè)置不同的Hadoop參數(shù)(比如heap大小)。
將提供可配置的模板用以簡易參數(shù)配置機(jī)制。
集群的配置:Savanna將提供虛擬機(jī),安裝和配置Hadoop。
集群上的操作:添加和移除節(jié)點(diǎn)。
在不需要時(shí)終止集群。
對于分析即服務(wù)的工作流程包括以下選項(xiàng):
選擇一個(gè)預(yù)定義版本
配置作業(yè):
選擇作業(yè)的類型:pig、hive、jar-file等等
提供作業(yè)腳本源或者是jar路徑
選擇輸入和輸出數(shù)據(jù)路徑(最初只支持Swift)
為日志選擇路徑
設(shè)置集群大小限制
執(zhí)行作業(yè):
所有集群配置和作業(yè)執(zhí)行都會(huì)清楚的呈現(xiàn)給用戶
作業(yè)結(jié)束后會(huì)自動(dòng)移除集群
取回計(jì)算結(jié)果(比如從Swift)
用戶方面
在使用Savanna配置集群時(shí),用戶在兩種類型實(shí)體上進(jìn)行操作:Node Template和Cluster。
Node Template用于描述集群中的節(jié)點(diǎn),包含了幾個(gè)參數(shù)。節(jié)點(diǎn)類型就屬于Node Template的屬性之一,這將決定Hadoop將在節(jié)點(diǎn)上運(yùn)行什么樣的處理,確定節(jié)點(diǎn)在集群中的扮演的角色,它可以是Job Tracker、NameNode、TaskTracker、DataNode或者這些節(jié)點(diǎn)的邏輯組合。Node Template同樣還保存了硬件參數(shù),這些參數(shù)用于節(jié)點(diǎn)虛擬機(jī)以及Hadoop在節(jié)點(diǎn)上的工作內(nèi)容。
Cluster實(shí)體用于描述Hadoop Cluster,描述了預(yù)裝Hadoop虛擬機(jī)特征,用于集群的部署和集群拓?fù)洹M負(fù)涫枪?jié)點(diǎn)模板和每個(gè)模板該部署節(jié)點(diǎn)數(shù)量的列表。關(guān)于拓?fù)洌琒avanna會(huì)驗(yàn)證集群中的NameNode和JobTracker是否唯一。
每個(gè)節(jié)點(diǎn)模板和集群都?xì)w屬于用戶給其分配的tenant,用戶只能訪問已接入tenant里面的對象。用戶只能編輯或刪除他們建立的對象,當(dāng)然管理員用戶可以訪問所有的對象,Savanna需要遵守同樣的OpenStack訪問策略。
Savanna提供了多種Hadoop集群拓?fù)洌琂ob Tracker和NameNode進(jìn)程可以選擇在一或兩個(gè)獨(dú)立的虛擬機(jī)上運(yùn)行。同樣集群可以包含多種類型的工作節(jié)點(diǎn),工作節(jié)點(diǎn)可以同時(shí)充當(dāng)TaskTracker和DataNode,同樣也可以扮演一個(gè)角色。Savanna允許用戶任意選項(xiàng)的組合去建立集群。
與Swift整合
在OpenStack中,Swift作為標(biāo)準(zhǔn)對象存儲(chǔ),類似Amazon S3。通常部署在實(shí)體主機(jī)上,Swift被作為“OpenStack上的HDFS”,具備很多使用的增強(qiáng)功能。
首先為Swift實(shí)現(xiàn)的文件系統(tǒng): HADOOP-8545,這樣的話Hadoop作業(yè)就可以運(yùn)行在Swift上。在Swift方面,我們必須將請求更改為 Change I6b1ba25b。它將端點(diǎn)映射為Object、Account或者是Container列表,這樣就可以將Swift與依賴數(shù)據(jù)位置信息的軟件整合,從而達(dá)到避免網(wǎng)絡(luò)開銷。
可插拔部署和監(jiān)控
監(jiān)視功能來自供應(yīng)商定制的Hadoop管理工具,Savanna整合了類似Nagios及Zabbix可插拔外部監(jiān)視系統(tǒng)。
部署和監(jiān)控工具都將被安裝在獨(dú)立的虛擬機(jī)上,從而允許單一的實(shí)例同時(shí)管理或監(jiān)控不同的集群。