Hadoop 2.0 Yarn代碼:心跳驅動服務分析
主要涉及的java文件
hadoop-yarn-server-resourcemanager下的包
org.apache.hadoop.yarn.server.resourcemanager
ResourceTrackerService.java
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo
FifoScheduler.java
org.apache.hadoop.yarn.server.resourcemanager.rmnode
RMNodeImpl.java
hadoop-yarn-server-nodemanager下的包
org.apache.hadoop.yarn.server.nodemanager
NodeStatusUpdaterImpl.java
2.代碼分析
各個服務代碼已經啟動,NodeStatusUpdate啟動后開始驅動整個Hadoop運行
1).NodeStatusUpdaterImpl(NodeManager端):
NodeStatusUpdaterImpl一經被啟動,start()函數被調用,進行Hadoop RPC服務端的初始化操作(調用getServer函數創建服務等等)。
start()函數主要依次調用registerWithRM()函數和startStatusUpdater()函數
registerWithRM()函數
設置必要配置信息,和安全認證操作
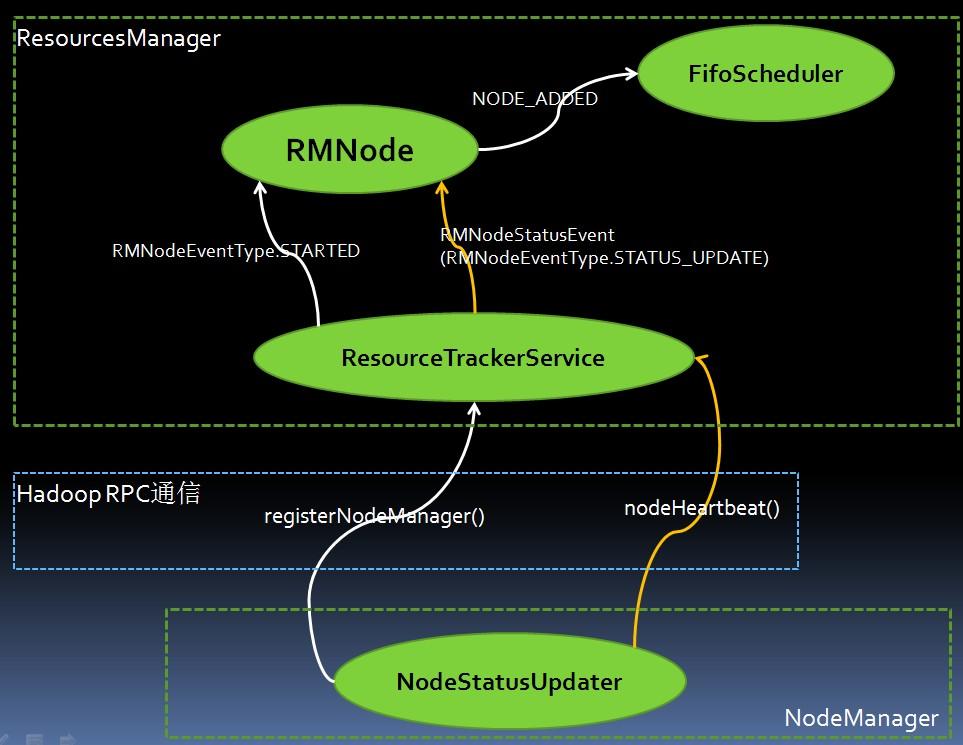
利用Hadoop RPC遠程調用RM端ResourcesTrackerService下的registerNodeManager()方法,詳細見后面ResourcesTrackerService下的registerNodeManager()代碼分析
startStatusUpdater()函數
創建一個線程,然后啟動,所有操作都在運行while的循環中
設置、獲取和輸出必要配置信息,其中比較重要的調用getNodeStatus()方法,獲取本地Container和本地Node的狀態,以供后面的nodeHeartbeat()方法使用
通過Hadoop RPC遠程調用RM端ResourcesTrackerService下的nodeHeartbeat()函數,用while循環以一定時間間隔向RM發送心跳信息,心跳操作見下面ResourcesTrackerService下nodeHeartbeat()函數
nodeHeartbeat()將返回給NM信息,根據返回的response,根據response返回的信息標記不需要的Container和Application發送相應的FINISH_CONTAINERS和FINISH_APPS給ContainerManager,進行清理操作----詳細見后面的代碼分析
2).ResourceTrackerService(ResourcesManager端):
ResourceTrackerService開頭與NodeStatusUpdaterImpl相似,start()函數被調用,初始化Hadoop RPC服務端,等待遠程來調用ResourceTrackerService中的函數
接上面的NodeStatusUpdaterImpl中對registerNodeManager()和nodeHeartbeat()的Hadoop RPC調用,詳細調用細節見下文
以下分成主要從兩個函數registerNodeManager()和nodeHeartbeat()開始分析,所以分成兩部分---
第一部分:
1).接前文ResourceTrackerService下的registerNodeManager()函數
首先獲取本地的NodeID,還有相應的主機名、端口、請求資源信息。
進行安全認證等輔助操作,檢查NodeID所標記的Node是否"有效".如果“無效”的話,立即返回
Node“有效”說明此Node可用,于是創建RMNode(new RMNodeImpl)來識別這個Node的狀態和監測在這個Node上運行的Container和Application
判斷其是否為新RMNode,如果是則向其發送RMNodeEventType.STARTED
如果不是新的RMNode,則發送RMNodeEventType.RECONNECTED到RMNode,重新連接Node,見附加代碼分析。
最后返回給調用方操作結果。
2).RMNodeImpl:當接收RMNodeEventType.STARTED后(接1)),發生狀態轉移NodeState(NEW→RUNNING),Transition函數被調用
向調度器(FifoScheduler)發送NODE_ADDED。
判斷這個Node是否Inactive,如果在Inactive中則,則先將這個Node移除出Inactive,否則增加ActiveNodes的數目。
3).FifoScheduler:接受NODE_ADDED事件,調用addNode()函數,向RM報告新添加的Node的狀態
addNode函數被調用,首先將接收到的RMNode的NodeID和其相應新創建的SchedulerNode(包含對資源的各種操作)放在ConcurrentHashMap類型的node對象中。
再調用Resources下的addTo()函數,累加Node的資源數量,來計算集群中擁有的資源數量
至此NM端的Node已經添加到RM的管轄范圍下,NM成功注冊到RM
附加代碼分析
附加2).RMNodeImpl:當RMNode接收RMNodeEventType.RECONNECTED(接1)),則保持當前狀態不變(RUNNING或者UNHEALTHY),Transition函數被調用
首先向調度器(FifoScheduler)發送NODE_REMOVED事件,刪除當前Node
然后重新連接操作,如果新連接的Node與上一次斷開的Node為同一個,則直接向調度器發送NODE_ADDED事件,如果兩個Node不是同一個,則更新關于Node的參數,再將新的Node加入ConcurrentHashMap類型的node對象中(與前面FifoScheduler中的是同一個)
最后向新的RMNode發送RMNodeEventType.STARTED
附加3).FifoScheduler:接到NODE_REMOVED事件,調用removeNode()函數
removeNode()函數中,先將此Node上的Container全部Kill掉,通過發送RMContainerEventType.KILL實現,因為現在討論沒有Job運行,所以沒有Container可以Kill
從nodes中移出此Node,最后計算集群資源,將相應Node的資源數量從集群資源總量扣除,完畢
第二部分
1).接前文ResourceTrackerService下的nodeHeartbeat()函數,各個NM已經注冊到RM上,則各個NM開始調用這個函數向RM發送“心跳”保持聯系,另外這里討論的是未提交Job的情況下
獲取所需操作的參數變量,例如NodeStatus、NodeId等
驗證發送這次“心跳的”NM是否已經注冊到RM,若未注冊則返回給NM讓其進行重新(reboot)注冊到RM中(實際上就是讓NodeStatusUpdater跳過此次循環)。
驗證這個NM是否“有效”(有效:主機隊列包含這個NM或者黑名單沒有這個NM),如“無效”,則發送RMNodeEventType.DECOMMISSION到NM相應的RMNode中,并關閉(shutdown)這個NM---下接附加2)
驗證這次“心跳”是否與上一個“心跳”重復或者是不是新的“心跳”,這個通過心跳ID實現,如果重復則輸出心跳重復信息,并且直接返回,如果不是新的心跳,則向RMNode發送RMNodeEventType.REBOOTING,然后返回reboot,讓NM“重啟”(和上面一樣NodeStatusUpdater跳過當此次循環)---下接附加2)
設置新的“心跳”ID,獲取Container和Application的信息
向RMNode發送包含STATUS_UPDATE和Container、Application等信息的RMNodeStatusEvent,然后返回相應設置好的response給調用者。
2).RMNodeImpl:RMNode接收到包含STATUS_UPDATE和Container、Application等信息的RMNodeStatusEvent,RMNodeImpl狀態遷移NodeState(RUNNING→UNHEALTHY或RUNNING→RUNNING),Transition函數被調用
首先從RMNodeStatusEvent獲得必要的變量,然后判斷相應的Node的“健康”情況,如果出現問題,則向調度器NODE_REMOVED,則調度器將此NM從集群管理刪除(詳見第一部分 附加3)),然后發送NODE_UNUSABLE到NodeListManager,將其RMNode放到“unusable”的set集合當中,此時RMNodeImpl的NodeState(RUNNING→UNHEALTHY)
如果“健康” 則順利運行,獲取NM遠程傳過來的關于Container的信息(是在NM端用Hadoop RPC調用nodeHeartbeat()時傳送過來的),
說明:
由于這個地方討論的時候,無Job提交過來,NM端無Container啟動,NM發送到RM的事件里面的裝有Container狀態的List為空,所以只傳送“心跳” 表明NM的活動信息,并沒有實際處理,RM端也無Application處理,接受“心跳”只會向RMNode發送RMNodeCleanContainerEvent事件,清理可能互動的Container(對應的代碼見FifoScheduler下的containerLaunchedOnNode函數)。若詳見處理情況的運行狀態,參見后面的文章:RM與NM代碼_心跳驅動服務分析_2 Container的配置和分配(Job提交)一篇。此時RMNodeImpl的NodeState(RUNNING→RUNNING)
到這為止,RM-NM端的代碼已經啟動完成,RM和NM之間以一定的時間間隔用心跳交互信息,等待Job的提交
附加代碼分析
附加2)RMNodeImpl:當RMNode接收RMNodeEventType.DECOMMISSION),發生狀態轉移NodeState(RUNNING→DECOMMISSIONED),Transition函數被調用,
將DECOMMISSIONED設置為finalState
當接到RMNodeEventType.REBOOTING情況類似,最后將REBOOTING設置為finalState。
分析如下圖,其中白色線為第一部分,初始NM注冊到RM階段,黃色線為第二部分,NM發送“心跳”信息到RM階段
原文鏈接:http://www.cnblogs.com/biyeymyhjob/archive/2012/08/21/2648026.html
【編輯推薦】