分布式文件系統HDFS解讀
【前言】是蠻久木有寫過關于hadoop的博客了額,雖然最近也看了一些關于linux的基礎知識,但似乎把這個東西忘記了,其實時不時回顧一下以前的知識還是蠻有意思的,且行且憶!我們Hadoop主要由HDFS和MapReduce引擎兩部分組成。***部是HDFS,它存儲Hadoop集群中所有存儲節點上的文件。HDFS的上一層是MapReduce引擎,該引擎由JobTrackers和TaskTrackers組成。這篇博客就主要來講講HDFS吧~~~
HDFS是HadoopDistributedFileSystem的簡稱,既然是分布式文件系統,首先它必須是一個文件系統,那么在Hadoop上面的文件系統會不會也像一般的文件系統一樣由目錄結構和一組文件構成呢?分布式是不是就是將文件分成幾部分分別存儲在不同的機器上呢?HDFS到底有什么優點值得這么小題大作呢?
好吧,讓我們帶著疑問一個個去探索吧!
一、HDFS基本概念
1、數據塊
HDFS默認的最基本的存儲單位是64M的數據塊,這個數據塊可以理解和一般的文件里面的分塊是一樣的
2、元數據節點和數據節點
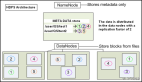
元數據節點(namenode)用來管理文件系統的命名空間,它將所有的文件和文件夾的元數據保存在一個文件系統樹中。
數據節點(datanode)就是用來存儲數據文件的。
從元數據節點(secondarynamenode)不是我們所想象的元數據節點的備用節點,其實它主要的功能是主要功能就是周期性將元數據節點的命名空間鏡像文件和修改日志合并,以防日志文件過大。
這里先來弄清楚這個三種節點的關系吧!其實元數據節點上存儲的東西就相當于一般文件系統中的目錄,也是有命名空間的映射文件以及修改的日志,只是分布式文件系統就將數據分布在各個機器上進行存儲罷了,下面你看看這幾張說明圖應該就能明白了!


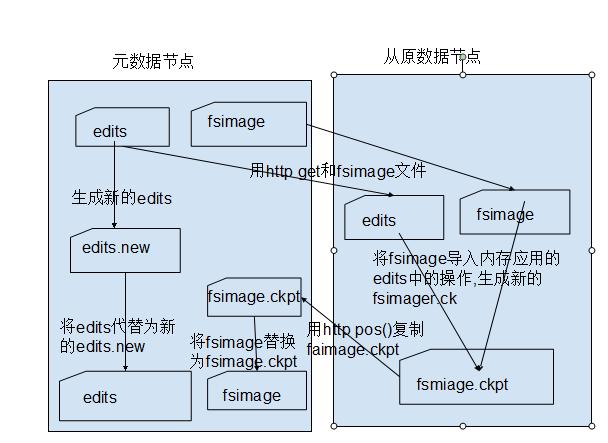
Namenode與secondarynamenode之間的進行checkpoint的過程。
3、HDFS中的數據流
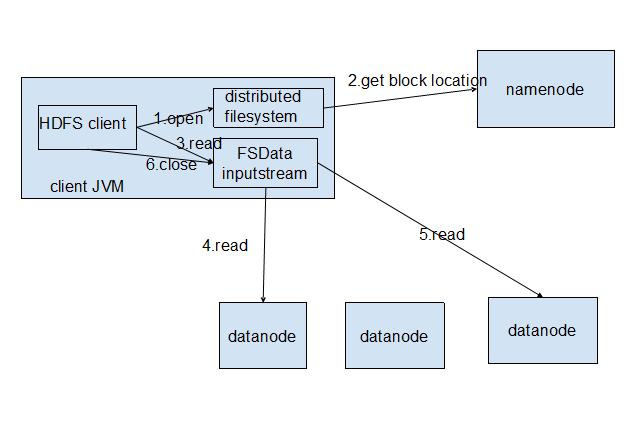
讀文件
客戶端(client)用FileSystem的open()函數打開文件,DistributedFileSystem用RPC調用元數據節點,得到文件的數據塊信息。對于每一個數據塊,元數據節點返回保存數據塊的數據節點的地址。DistributedFileSystem返回FSDataInputStream給客戶端,用來讀取數據。客戶端調用stream的read()函數開始讀取數據。DFSInputStream連接保存此文件***個數據塊的最近的數據節點。Data從數據節點讀到客戶端(client),當此數據塊讀取完畢時,DFSInputStream關閉和此數據節點的連接,然后連接此文件下一個數據塊的最近的數據節點。當客戶端讀取完畢數據的時候,調用FSDataInputStream的close函數。
整個過程就是如圖所示:
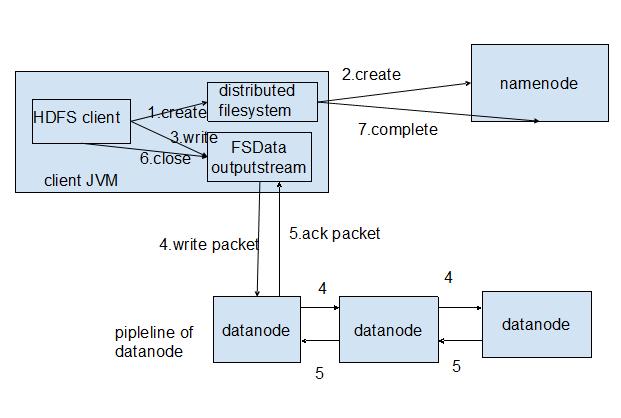
寫文件
客戶端調用create()來創建文件,DistributedFileSystem用RPC調用元數據節點,在文件系統的命名空間中創建一個新的文件。元數據節點首先確定文件原來不存在,并且客戶端有創建文件的權限,然后創建新文件。DistributedFileSystem返回DFSOutputStream,客戶端用于寫數據。客戶端開始寫入數據,DFSOutputStream將數據分成塊,寫入dataqueue。Dataqueue由DataStreamer讀取,并通知元數據節點分配數據節點,用來存儲數據塊(每塊默認復制3塊)。分配的數據節點放在一個pipeline里。DataStreamer將數據塊寫入pipeline中的***個數據節點。***個數據節點將數據塊發送給第二個數據節點。第二個數據節點將數據發送給第三個數據節點。DFSOutputStream為發出去的數據塊保存了ackqueue,等待pipeline中的數據節點告知數據已經寫入成功。如果數據節點在寫入的過程中失敗:關閉pipeline,將ackqueue中的數據塊放入dataqueue的開始。
整個過程如圖所示:
二、HDFS構架與設計
Hadoop也是一個能夠分布式處理大規模海量數據的軟件框架,這一切都是在可靠、高效、可擴展的基礎上。Hadoop的可靠性——因為Hadoop假設計算元素和存儲會出現故障,因為它維護多個工作數據副本,在出現故障時可以對失敗的節點重新分布處理。Hadoop的高效性——在MapReduce的思想下,Hadoop是并行工作的,以加快任務處理速度。Hadoop的可擴展——依賴于部署Hadoop軟件框架計算集群的規模,Hadoop的運算是可擴展的,具有處理PB級數據的能力。
Hadoop主要由HDFS(HadoopDistributedFileSystem)和MapReduce引擎兩部分組成。***部是HDFS,它存儲Hadoop集群中所有存儲節點上的文件。HDFS的上一層是MapReduce引擎,該引擎由JobTrackers和TaskTrackers組成。
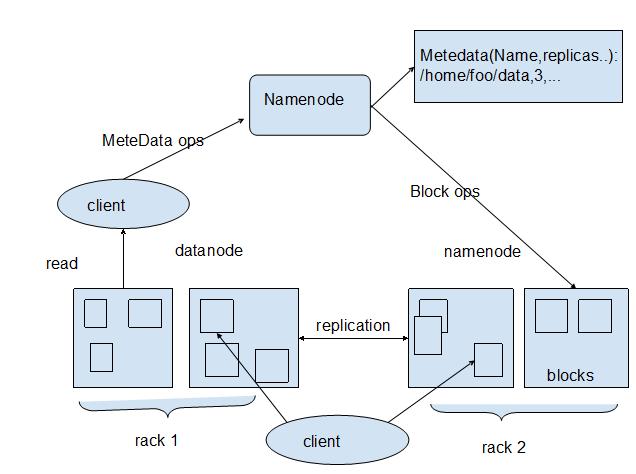
HDFS可以執行的操作有創建、刪除、移動或重命名文件等,架構類似于傳統的分級文件系統。需要注意的是,HDFS的架構基于一組特定的節點而構建(參見圖2),這是它自身的特點。HDFS包括唯一的NameNode,它在HDFS內部提供元數據服務;DataNode為HDFS提供存儲塊。由于NameNode是唯一的,這也是HDFS的一個弱點(單點失敗)。一旦NameNode故障,后果可想而知。
1、HDFS構架(如圖所示)
2、HDFS的設計
1)錯誤檢測和快速、自動的恢復是HDFS的核心架構目標。
2)比之關注數據訪問的低延遲問題,更關鍵的在于數據訪問的高吞吐量。
3)HDFS應用對文件要求的是write-one-read-many訪問模型。
4)移動計算的代價比之移動數據的代價低。
3、文件系統的namespace
Namenode維護文件系統的namespace,一切對namespace和文件屬性進行修改的都會被namenode記錄下來,連文件副本的數目稱為replication因子,這個也是由namenode記錄的。
4、數據復制
Namenode全權管理block的復制,它周期性地從集群中的每個Datanode接收心跳包和一個Blockreport。心跳包的接收表示該Datanode節點正常工作,而Blockreport包括了該Datanode上所有的block組成的列表。HDFS采用一種稱為rack-aware的策略來改進數據的可靠性、有效性和網絡帶寬的利用。完成對副本的存放。
5、文件系統元數據的持久化
Namenode在內存中保存著整個文件系統namespace和文件Blockmap的映像。這個關鍵的元數據設計得很緊湊,因而一個帶有4G內存的Namenode足夠支撐海量的文件和目錄。當Namenode啟動時,它從硬盤中讀取Editlog和FsImage,將所有Editlog中的事務作用(apply)在內存中的FsImage,并將這個新版本的FsImage從內存中flush到硬盤上,然后再truncate這個舊的Editlog,因為這個舊的Editlog的事務都已經作用在FsImage上了。這個過程稱為checkpoint。在當前實現中,checkpoint只發生在Namenode啟動時,在不久的將來我們將實現支持周期性的checkpoint。
6、通信協議
所有的HDFS通訊協議都是構建在TCP/IP協議上。客戶端通過一個可配置的端口連接到Namenode,通過ClientProtocol與Namenode交互。而Datanode是使用DatanodeProtocol與Namenode交互。從ClientProtocol和Datanodeprotocol抽象出一個遠程調用(RPC),在設計上,Namenode不會主動發起RPC,而是是響應來自客戶端和Datanode的RPC請求。
HDFS不是這么簡單就能說清楚的,在以后的博客中我還會繼續研究hadoop的分布式文件系統,包括HDFS的源碼分析等,現由于時間有限,暫時只做了以上一些簡單的介紹吧,希望對大家由此對HDFS有一定的了解!