













分布式系統事務原子性的非阻塞實現
本文作者Peter Bailis是美國Berkeley的研究生,主要研究方向是分布式系統與數據庫。作者目前主要的研究內容是分布式數據的一致性,尤其是如何調和ACID特性和分布式一致性模型,以及如何在理論和實際中更好的理解最終一致性。
作者將分布式系統中的事務定義為針對多個服務器的同時操作,本文主要討論了分布式系統事務的原子性的一種實現算法。通常情況下原子性都是通過鎖實現的,這個算法并沒有使用鎖,原理很簡單,采用了簡單的多版本控制和存儲一些額外的元數據,雖然作者只是在實驗環境中實現了這個算法,并沒有投入到實際生產中,但是作者思考問題的方式值得參考。
分布式系統事務原子性
在現實的分布式系統中,多對象更新的操作很常見,但是實現起來卻并不簡單。同時更新兩個或多個對象時,對于這些對象的其他讀取者,原子性很重要:你的更新要么全部可見,要么全部不可見。
這里所說的原子性和線性一致并不是一個概念,數據一致性在Gilbert和Lynch證明CAP原理時被提到過,后來通常被稱為原子一致性。而線性一致化關注實時的順序操作,是一個單對象的問題。這里的“原子性”源于數據庫環境(ACID中的“A”),涉及對多個對象的執行和查詢操作。為了避免混淆,我們稱這個原子性為“事務原子性”。
許多場景中都會遇到這種問題,從社交網絡圖(例如Facebook的TAO系統,雙向的朋友關系被保存在兩個單向的指針中)到類似計數器(例如Twitter的Rainbird分層聚合器)和二級索引的分布式數據結構。本文中,我將假設我們的工作都是高可用的事務,原子性的多對象更新,或事務的原子性,是其首要特性。
現有的技術
多對象更新的事務操作通常采用以下三種策略之一:
鎖
使用鎖來同時更新多個項目。執行更新操作時加寫鎖,執行讀操作時加讀鎖,就可以保證事務的原子性。但是在分布式環境中,局部故障和網絡延遲都意味著鎖操作可能會導致Bad Time。
具體來講,鎖操作有可能會導致一些怪異的結果。如果客戶端在持有鎖時宕機,服務器本應該最終撤銷這個鎖。這需要某種形式的故障檢測或超時(在異步網絡中會導致一些尷尬的情況)以及在撤銷鎖前同時撤銷以前的操作。但是在執行更新操作時阻塞讀操作顯然是不合理的,反之亦然。如果我們追求高可用性,鎖不是一個值得考慮的方案。
實體組
將想要同時更新的對象放在一起。這種策略通常稱為“實體組”,可以讓事務性原子更簡單:在一臺機器上加鎖很快,而且不會遇到分布式鎖的局部故障和網絡延遲的問題。不幸的是,這種解決方案會影響數據布局和分布,而且不適用于難于分割的數據。
Fuck-it模式
使用“fuck-it”模式,不進行任何并發控制的情況下更新所有的對象,并保持事務的原子性。這個策略是很常見的:擴展性良好,適用于任何系統,但是直到系統達到穩定狀態后,才會提供原子性保證(例如聚合,或者說最終一致性)。
NBTA
在這篇文章中,作者會介紹一種簡單的替代方案,作者稱其為事務原子性的非阻塞實現,簡稱為NBTA(Non-blocking transactional atomicity),使用多版本和一些額外的元數據在不使用鎖的情況下,保證事務的原子性。具體來說,這種方案不會由于過程錯誤而阻塞讀取和寫入操作。關鍵的想法是避免執行局部更新,并且利用額外的元數據代替副本間的同步。
NBTA示例
可以用這個簡單的場景來說明NBTA:有兩個服務器,server for x上存儲x,server for y上存儲y,初值都是0。假設有兩個客戶端,Client1要執行寫入操作,使x=1,y=1,Client2要同時讀取x和y,關于副本的問題稍后會討論。作者將Client1要執行的寫入操作稱為一個事務,而這個事務的操作對象server for x和server for y被稱為事務兄弟。
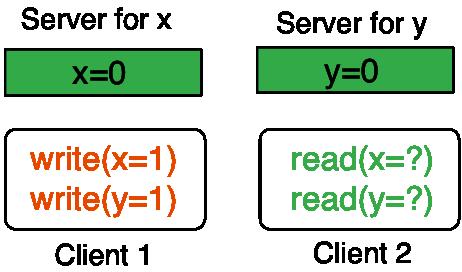
good和pending
將每臺服務器的存儲分為兩中狀態:good和pending。要保證同屬于一個事務的寫入操作,如果其中一個操作被存儲為good狀態,這個事務的其它寫入操作要么被存儲為good,要么被存儲為pending。比如在上面所說的場景中,如果x=1在server for x上被存儲為good,那么必須保證y=1在server for y被存儲為good或pending。

首先,各服務器會收到到寫操作請求保存為pending狀態,然后一旦服務器知曉(可能是異步的)某個寫入操作相關的事務兄弟都已經將操作請求保存為pending狀態,這個服務器就會更新這個操作為good狀態。客戶端進行兩輪通信,就可以使服務器得到寫操作已經穩定的信息:第一輪通信中,server for x和server for y會將從Client1收到請求保存為pending狀態,并將確認回復給Client1,Client1收到確認后會進行第二輪通信,通知server for x和server for y寫操作已達到穩定狀態。
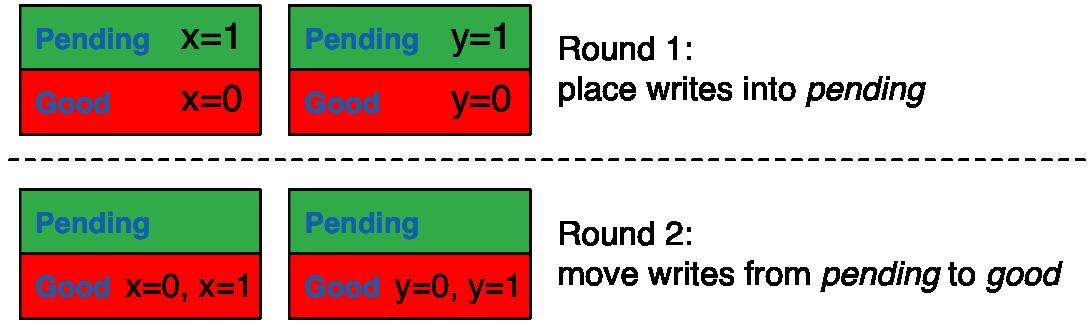
競爭危害和指針
理想的狀態是,只讀取good狀態的數據,就可以保證事務的原子性。但是存在一種競爭條件的情況:比如server for x已經更新x=1,并保存為good狀態,但在其事務兄弟server for y中相關操作y=1依舊是pending狀態,Client2如果只讀取good狀態的數據,得到的結果將是x=1,y=0,破壞了事務的原子性。我們希望這種情況下,第二個服務器能夠自動調用pending狀態的數據以供讀取。

為了解決這個問題,可以在每個寫入操作中加入一些額外的信息:事務兄弟的列表以及一個時間戳。這個時間戳是客戶端進行多值更新前,為每個寫操作唯一生成的,比如,可以是客戶端ID+本地時間或一個隨機數。這樣的話,當一個客戶端讀取good狀態的數據時,還會讀到時間戳和具有相同時間戳的事務兄弟的列表。客戶端也會在發送讀取請求附帶一個時間戳,服務器會根據時間戳從pending或good中取出數據交付給客戶端。如果客戶端的請求中沒有附帶時間戳,服務器會將good中時間戳最高的值交付給客戶端。

優化
以下是NBTA算法的一些優化:
pending和good的規模
如果用在good中只保存最近的寫入操作,那么一個寫入操作的兄弟事務可能會被覆蓋,為了避免這種情況的發生,服務器會在good中將歷史數據保留一定的時間。
更快的寫操作
有一種方案可以替代客戶端的第二輪通信操作。服務器一旦將寫操作存入pending中,就直接互相通信,可使用類似于PAXOS的算法實現。此外,客戶端也可以異步發起第二輪通信。然而,為了確保客戶端在這些情況下讀取寫操作,它們要保留元數據直到每個寫操作都被存為good狀態。
副本
目前為止的討論都基于每個數據項只存儲在一個服務器上。算法實現的前提條件是每個服務器的強一致性。服務器間的副本有兩種情況:如果所有的客戶端都只能訪問一部分服務器,那么客戶端只需要對這些對應的服務器集合進行更新,這組服務器都存有數據的副本。如果客戶端可以訪問任何服務器,那么需要花費較長的時間去同步數據。
讀/寫事務
以上討論的算法同樣適用于讀/寫操作。對于ANSI標準的可重復讀模型,主要的問題是保證從一個事務的原子組中讀取。可以在事務執行前,事先聲明所有的讀取操作或者通過類似向量時間的元數據實現。
元數據的規模
最謹慎的做法是將元數據一直保存,但是也可以在寫操作在所有服務器中都達到good狀態時,將元數據刪除。
算法的實現
作者采用LevelDB數據庫實現了NBTA算法及其改進。在Yahoo!的云平臺上,8個操作的NBTA事務可以達到最終一致性的33%(所有都是寫操作)至95.2%(所有都是讀操作)峰值吞吐量。并且這種實現是線性擴展的,運行50個EC2實例,對于長度為8的事務(50%的讀操作,50%的寫操作),可以達到每秒執行250000次操作。
實驗結果表明NBTA的性能大大優于基于鎖的操作,因為不會發生阻塞。主要的花銷來自于元數據以及將寫入操作從pending更新為good。基于這些結果,作者已經開始將NBTA應用于其它數據存儲和二級索引上。
結論
這篇文章展現了如何在不使用鎖的情況下,實現在任意數據分片的原子性多對象更新。數據庫中有很多類似于NBTA的算法。例如客戶端第二輪通信的優化是通過PAXOS的算法實現的,使用額外的元數據保持并發更新類似于B樹或其它非鎖的數據結構。當然,多版本并發控制和基于時間戳的并發控制在數據庫系統中也都有悠久的歷史。但是NBTA的關鍵是實現事務的原子性,同時避免中央集權的時間戳或并發控制機制。具體來說要在數據讀取操作前達到一個穩定狀態,主要的挑戰是解決競爭條件。在實際中,相比其它基于鎖的技術,這個算法表現得很好。



















