Linux內(nèi)存管理--slab及其代碼解析
Linux內(nèi)核使用了源自于 Solaris 的一種方法,但是這種方法在嵌入式系統(tǒng)中已經(jīng)使用了很長時間了,它是將內(nèi)存作為對象按照大小進(jìn)行分配,被稱為slab高速緩存。
內(nèi)存管理的目標(biāo)是提供一種方法,為實現(xiàn)各種目的而在各個用戶之間實現(xiàn)內(nèi)存共享。內(nèi)存管理方法應(yīng)該實現(xiàn)以下兩個功能:
- 最小化管理內(nèi)存所需的時間
- ***化用于一般應(yīng)用的可用內(nèi)存(最小化管理開銷)
內(nèi)存管理實際上是一種關(guān)于權(quán)衡的零和游戲。您可以開發(fā)一種使用少量內(nèi)存進(jìn)行管理的算法,但是要花費(fèi)更多時間來管理可用內(nèi)存。也可以開發(fā)一個算法來有效地管理內(nèi)存,但卻要使用更多的內(nèi)存。最終,特定應(yīng)用程序的需求將促使對這種權(quán)衡作出選擇。
每個內(nèi)存管理器都使用了一種基于堆的分配策略。在這種方法中,大塊內(nèi)存(稱為 堆)用來為用戶定義的目的提供內(nèi)存。當(dāng)用戶需要一塊內(nèi)存時,就請求給自己分配一定大小的內(nèi)存。堆管理器會查看可用內(nèi)存的情況(使用特定算法)并返回一塊內(nèi)存。搜索過程中使用的一些算法有 first-fit(在堆中搜索到的***個滿足請求的內(nèi)存塊)和 best-fit(使用堆中滿足請求的最合適的內(nèi)存塊)。當(dāng)用戶使用完內(nèi)存后,就將內(nèi)存返回給堆。
這種基于堆的分配策略的根本問題是碎片(fragmentation)。當(dāng)內(nèi)存塊被分配后,它們會以不同的順序在不同的時間返回。這樣會在堆中留下一些洞,需要花一些時間才能有效地管理空閑內(nèi)存。這種算法通常具有較高的內(nèi)存使用效率(分配需要的內(nèi)存),但是卻需要花費(fèi)更多時間來對堆進(jìn)行管理。
另外一種方法稱為 buddy memory allocation,是一種更快的內(nèi)存分配技術(shù),它將內(nèi)存劃分為 2 的冪次方個分區(qū),并使用 best-fit 方法來分配內(nèi)存請求。當(dāng)用戶釋放內(nèi)存時,就會檢查 buddy 塊,查看其相鄰的內(nèi)存塊是否也已經(jīng)被釋放。如果是的話,將合并內(nèi)存塊以最小化內(nèi)存碎片。這個算法的時間效率更高,但是由于使用 best-fit 方法的緣故,會產(chǎn)生內(nèi)存浪費(fèi)。
slab 緩存
Linux 所使用的 slab 分配器的基礎(chǔ)是 Jeff Bonwick 為 SunOS 操作系統(tǒng)***引入的一種算法。Jeff 的分配器是圍繞對象緩存進(jìn)行的。在內(nèi)核中,會為有限的對象集(例如文件描述符和其他常見結(jié)構(gòu))分配大量內(nèi)存。Jeff 發(fā)現(xiàn)對內(nèi)核中普通對象進(jìn)行初始化所需的時間超過了對其進(jìn)行分配和釋放所需的時間。因此他的結(jié)論是不應(yīng)該將內(nèi)存釋放回一個全局的內(nèi)存池,而是將內(nèi)存保持為針對特定目而初始化的狀態(tài)。例如,如果內(nèi)存被分配給了一個互斥鎖,那么只需在為互斥鎖***分配內(nèi)存時執(zhí)行一次互斥鎖初始化函數(shù)(mutex_init)即可。后續(xù)的內(nèi)存分配不需要執(zhí)行這個初始化函數(shù),因為從上次釋放和調(diào)用析構(gòu)之后,它已經(jīng)處于所需的狀態(tài)中了。
Linux slab 分配器使用了這種思想和其他一些思想來構(gòu)建一個在空間和時間上都具有高效性的內(nèi)存分配器。
圖 1 給出了 slab 結(jié)構(gòu)的高層組織結(jié)構(gòu)。在***層是 cache_chain,這是一個 slab 緩存的鏈接列表。這對于 best-fit 算法非常有用,可以用來查找最適合所需要的分配大小的緩存(遍歷列表)。cache_chain 的每個元素都是一個 kmem_cache 結(jié)構(gòu)的引用(稱為一個 cache)。它定義了一個要管理的給定大小的對象池。
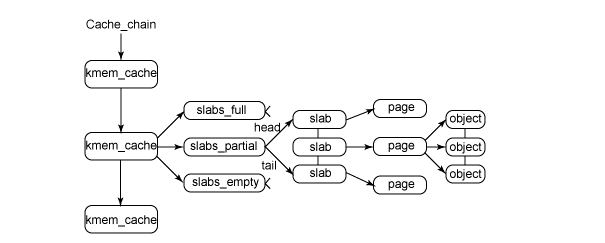
圖 1. slab 分配器的主要結(jié)構(gòu)
每個緩存都包含了一個 slabs 列表,這是一段連續(xù)的內(nèi)存塊(通常都是頁面)。存在 3 種 slab:
slabs_full
完全分配的 slab
slabs_partial
部分分配的 slab
slabs_empty
空 slab,或者沒有對象被分配
注意:slabs_empty 列表中的 slab 是進(jìn)行回收(reaping)的主要備選對象。正是通過此過程,slab 所使用的內(nèi)存被返回給操作系統(tǒng)供其他用戶使用。
slab 列表中的每個 slab 都是一個連續(xù)的內(nèi)存塊(一個或多個連續(xù)頁),它們被劃分成一個個對象。這些對象是從特定緩存中進(jìn)行分配和釋放的基本元素。注意 slab 是 slab 分配器進(jìn)行操作的最小分配單位,因此如果需要對 slab 進(jìn)行擴(kuò)展,這也就是所擴(kuò)展的最小值。通常來說,每個 slab 被分配為多個對象。
由于對象是從 slab 中進(jìn)行分配和釋放的,因此單個 slab 可以在 slab 列表之間進(jìn)行移動。例如,當(dāng)一個 slab 中的所有對象都被使用完時,就從 slabs_partial 列表中移動到 slabs_full 列表中。當(dāng)一個 slab 完全被分配并且有對象被釋放后,就從 slabs_full 列表中移動到 slabs_partial 列表中。當(dāng)所有對象都被釋放之后,就從 slabs_partial 列表移動到 slabs_empty 列表中。
#p#
一、slab相關(guān)數(shù)據(jù)結(jié)構(gòu)
1)slab高速緩存描述符
- struct kmem_cache {
- struct array_cache *array[NR_CPUS];//為了提高效率,每個cpu都有一個slab空閑對象緩存
- /* 2) Cache tunables. Protected by cache_chain_mutex */
- unsigned int batchcount;//從本地高速緩存批量移入或移出對象的數(shù)目
- unsigned int limit;//本地高速緩存空閑對象的***數(shù)目
- unsigned int shared;
- unsigned int buffer_size;
- struct kmem_list3 *nodelists[MAX_NUMNODES];//slab高速緩存空閑,部分空閑,無空閑slab的三個鏈表
- unsigned int flags; /* constant flags */
- unsigned int num;//每個slab obj的個數(shù)
- unsigned int gfporder;//每個slab中連續(xù)頁框的數(shù)目
- gfp_t gfpflags;//分配頁框時,傳遞給伙伴系統(tǒng)的標(biāo)志
- size_t colour;//slab使用的顏色個數(shù)
- unsigned int colour_off; //slab的顏色偏移
- struct kmem_cache *slabp_cache; //指向存放slab描述符的chache,內(nèi)部slab此字段為null
- unsigned int slab_size;//單個slab的大小
- unsigned int dflags; /* dynamic flags */
- //對象創(chuàng)建的構(gòu)建函數(shù)
- void (*ctor) (void *, struct kmem_cache *, unsigned long);
- //對象的析構(gòu)函數(shù)
- void (*dtor) (void *, struct kmem_cache *, unsigned long);
- const char *name;//slab高速緩存的名稱
- struct list_head next;//通過該字段,將該cachep鏈接到cachep鏈表上
- }
2)slab描述符
- struct slab {
- struct list_head list; //將slab鏈接到各個slab鏈表上面,slabs_full, slabs_paril, slabs_free
- unsigned long colouroff;//slab中***個對象的偏移
- void *s_mem; //slab中***個對象的地址
- unsigned int inuse; //有多少對象正在被使用
- kmem_bufctl_t free; //表明接下來使用哪個空閑對象
- unsigned short nodeid;//該slab屬于哪個內(nèi)存節(jié)點
- }
slab描述符可能會被存放在兩個地方:
外部slab描述符:存放在slab外部,位于cache_size指向的一個普通高速緩存中。
內(nèi)部slab描述符:存放在slab的內(nèi)部,位于分配給slab的內(nèi)存的***個頁框的起始位置。
3)slab隊列描述符
- struct kmem_list3 {
- struct list_head slabs_partial; //對象被使用了一部分的slab描述符的鏈表
- struct list_head slabs_full;//對象都被占用了的slab描述符的鏈表
- struct list_head slabs_free;//只包含空閑對象的slab描述符的鏈表
- unsigned long free_objects;//高速緩存中空閑對象的個數(shù)
- unsigned int free_limit;
- unsigned int colour_next; /* Per-node cache coloring */
- spinlock_t list_lock;
- struct array_cache *shared; //指向所有cpu所共享的一個本地高速緩存
- struct array_cache **alien; /* on other nodes */
- unsigned long next_reap; //由slab的頁回收算法使用
- int free_touched; //由slab的頁回收算法使用
- }
4)slab對象描述符
- typedef unsigned int kmem_bufctl_t;
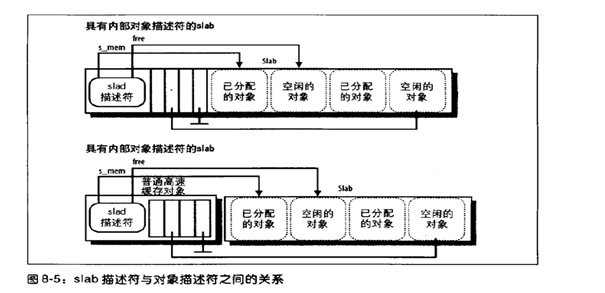
每個對象都有一個類型為kmem_bufctl_t的對象描述符,每個slab描述符都有一個kmem_bufctl_t類型的數(shù)組來描述slab中的各個對象。其實該描述符記錄的是下一個可用的空閑對象,使用了數(shù)組的索引來形成一個對象鏈表而已。對象描述符也分為內(nèi)部對象描述符和外部對象描述符兩種:
- 內(nèi)部對象描述符:存放在slab的內(nèi)部,位于描述符所描述的對象的前面。
- 外部對象描述符:存放在slab的外部,位于高速緩存描述符slabp_cache字段指向的一個普通高速緩存中,
slab描述符和slab對象之間的組織圖如下圖所示:
二、slab的本地對象緩存
Linux2.6為了更好的支持多處理器,減少自旋鎖的競爭并更好的利用硬件高速緩存,slab分配器的每個高速緩存都包含一個被稱為slab本地高速緩存的每cpu數(shù)據(jù)結(jié)構(gòu),該結(jié)構(gòu)由一個指向被釋放對象的指針數(shù)組組成。這樣的話,slab對象的釋放和分配就只影響到本地的指針數(shù)組,減少了并發(fā)性。只有本地數(shù)組上溢或者下溢時才會去涉及slab結(jié)構(gòu)。相關(guān)數(shù)據(jù)結(jié)構(gòu)如下:
- struct array_cache {
- unsigned int avail;//本地高速緩存中可用對象的個數(shù),也是空閑數(shù)組位置的索引
- unsigned int limit;//本地高速緩存的大小
- unsigned int batchcount;//本地高速緩存填充或者清空時使用到的對象個數(shù)
- unsigned int touched;//如果本地高速緩存最近被使用過,置成1
- spinlock_t lock;
- void *entry[0];
- }
同時在多cpu的環(huán)境下,還存在著一個共享高速緩存,它的地址被存放在高速緩存描述符的lists.shared字段中,本地共享高速緩存被所有cpu所共享,使得對象從一個本地高速緩存移至另一個高速緩存變的簡單。
三、slab內(nèi)存著色
比如cache line 32 字節(jié),字節(jié)0-31一次從內(nèi)存寫入/讀取,字節(jié)32-63一次從內(nèi)存寫入/讀取…..
另外cache對應(yīng)到內(nèi)存位置不是任意的
Cache 地址0 對應(yīng)到 內(nèi)存地址0 , 32 ,64 ….
Cache 地址1 對應(yīng)到 內(nèi)存地址1 , 33 ,65 ….
…
一個slab大小肯定是整數(shù)頁,所以起始地址末12位為零, 即都于cache0 對應(yīng)。然后2個slab的每一個obj大小一樣, 所以2個slab每個obj都對應(yīng)相同的cache line.這樣2個位置相同的obj都要頻繁訪問,比較容易使cache來回刷新,效率降低。
著色就是在第二個slab的起始位置空一個cache line出來,這樣2個slab每個obj對應(yīng)的cache錯開一個,這樣2個位置相同的obj即使頻繁訪問,也不會用一個相同cache line。
但是這種方法也是有限的,2個slab里面的obj對象的訪問比較隨即,不能保證哪兩個在一個cache line 里。
#p#
四、slab內(nèi)存的申請
內(nèi)核代碼中通過slab分配對象的函數(shù)時kmem_cachep_alloc(),實質(zhì)上***調(diào)用的函數(shù)是____cache_alloc(),其相應(yīng)源碼解析如下:
- static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
- {
- void *objp;
- struct array_cache *ac;
- check_irq_off();
- //通過進(jìn)程所在的cpu的id獲取slab的本地高速緩存
- ac = cpu_cache_get(cachep);
- //本地高速緩存中是否有空閑的slab對象
- if (likely(ac->avail)) {
- //有空閑對象的話,從本地高速緩存數(shù)組上取一個空閑的對象來使用
- STATS_INC_ALLOCHIT(cachep);
- //標(biāo)記一下該本地高速緩存最近被使用過
- ac->touched = 1;
- //從數(shù)組的***面先取一個未使用的對象,HOHO
- objp = ac->entry[--ac->avail];
- } else {
- STATS_INC_ALLOCMISS(cachep);
- //本地高速緩存中已經(jīng)沒有空閑對象,需要填充本地高速緩存
- objp = cache_alloc_refill(cachep, flags);
- }
- return objp;
- }
- cache_alloc_refill()用來填充本地高速緩存,也是slab分配精華的地方,代碼解析如下:
- static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
- {
- int batchcount;
- struct kmem_list3 *l3;
- struct array_cache *ac;
- check_irq_off();
- //根據(jù)cpu id得到slab本地高速緩存的數(shù)據(jù)結(jié)構(gòu)
- ac = cpu_cache_get(cachep);
- retry:
- //batchcount記錄了此次需要填充多少個空閑對象
- batchcount = ac->batchcount;
- if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
- batchcount = BATCHREFILL_LIMIT;
- }
- //獲取到相對應(yīng)的內(nèi)存節(jié)點上的slab鏈表kmem_list3,每個內(nèi)存節(jié)點都有自己的一套空閑,部分空閑,非空閑slab鏈表
- //因為相應(yīng)cpu訪問自己所屬的內(nèi)存節(jié)點的速度是最快的
- l3 = cachep->nodelists[numa_node_id()];
- BUG_ON(ac->avail > 0 || !l3);
- spin_lock(&l3->list_lock);
- //從本地共享高速緩存中往本地高速緩存中填充空閑對象,要注意對于numa
- //系統(tǒng)來說,往本地高速緩存上填充的空閑對象也都是該內(nèi)存節(jié)點上的空閑對象
- if (l3->shared && transfer_objects(ac, l3->shared, batchcount))
- goto alloc_done;
- while (batchcount > 0) {
- struct list_head *entry;
- struct slab *slabp;
- //先從部分空閑的slab里面分配空閑對象,保留完全空閑的slab,因為空閑的
- //slab在內(nèi)存不足時是可以回收的
- entry = l3->slabs_partial.next;
- //如果沒有了部分空閑的slab,就只能去完全空閑的slab中分配了
- if (entry == &l3->slabs_partial) {
- l3->free_touched = 1;
- entry = l3->slabs_free.next;
- //如果完全空閑的slab也沒有了,就必須要為slab高速緩存分配新的slab了
- if (entry == &l3->slabs_free)
- goto must_grow;
- }
- slabp = list_entry(entry, struct slab, list);
- check_slabp(cachep, slabp);
- check_spinlock_acquired(cachep);
- //從slab中分配空閑對象,直到slab中空閑對象不存在了,或者已經(jīng)分配
- //了足夠的空閑對象了
- while (slabp->inuse < cachep->num && batchcount--) {
- STATS_INC_ALLOCED(cachep);
- STATS_INC_ACTIVE(cachep);
- STATS_SET_HIGH(cachep);
- //此處獲取空閑對象
- ac->entry[ac->avail++] = slab_get_obj(cachep, slabp,
- numa_node_id());
- }
- check_slabp(cachep, slabp);
- /* move slabp to correct slabp list: */
- list_del(&slabp->list);
- //若相應(yīng)slab的空閑內(nèi)存分配完畢,將其掛入slabs_full的slab鏈表中
- if (slabp->free == BUFCTL_END)
- list_add(&slabp->list, &l3->slabs_full);
- else
- list_add(&slabp->list, &l3->slabs_partial);
- }
- must_grow:
- l3->free_objects -= ac->avail;
- alloc_done:
- spin_unlock(&l3->list_lock);
- //沒有分配到任何的對象
- if (unlikely(!ac->avail)) {
- int x;
- //為高速緩存申請新的slab
- x = cache_grow(cachep, flags, numa_node_id());
- /* cache_grow can reenable interrupts, then ac could change. */
- ac = cpu_cache_get(cachep);
- if (!x && ac->avail == 0) /* no objects in sight? abort */
- return NULL;
- //重新從頭填充本地高速緩存
- if (!ac->avail) /* objects refilled by interrupt? */
- goto retry;
- }
- ac->touched = 1;
- //返回本地高速緩存***一個空閑對象的地址
- return ac->entry[--ac->avail];
- }
#p#
五、slab內(nèi)存的釋放
slab內(nèi)存的釋放在函數(shù)kmem_cache_free()中,主要處理部分在__cache_free()函數(shù)中,其代碼解析如下:
- static inline void __cache_free(struct kmem_cache *cachep, void *objp)
- {
- struct array_cache *ac = cpu_cache_get(cachep);
- check_irq_off();
- objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
- if (cache_free_alien(cachep, objp))
- return;
- //本地高速緩存可用的空閑對象尚未達(dá)到限制,將空閑對象放入本地高速緩存
- if (likely(ac->avail < ac->limit)) {
- STATS_INC_FREEHIT(cachep);
- ac->entry[ac->avail++] = objp;
- return;
- } else {
- //cache_flusharray()會將本地高速緩存的一些空閑對象放入到slab中
- cache_flusharray(cachep, ac);
- ac->entry[ac->avail++] = objp;
- }
- }
- static void cache_flusharray(struct kmem_cache *cachep, struct array_cache *ac)
- {
- int batchcount;
- struct kmem_list3 *l3;
- int node = numa_node_id();
- //一次應(yīng)該將batchcount個空閑對象歸還到slab中
- batchcount = ac->batchcount;
- check_irq_off();
- //得到對應(yīng)內(nèi)存節(jié)點的slab list3,上面記錄著該節(jié)點的slab鏈表
- l3 = cachep->nodelists[node];
- spin_lock(&l3->list_lock);
- //優(yōu)先先歸還到本地共享高速緩存中,注意本地共享高速緩存中的
- //空閑對象是僅供該內(nèi)存節(jié)點上的各個cpu分配使用的,這樣可以使內(nèi)存訪問的效率***。
- if (l3->shared) {
- struct array_cache *shared_array = l3->shared;
- int max = shared_array->limit - shared_array->avail;
- if (max) {
- if (batchcount > max)
- batchcount = max;
- //將batchcount個數(shù)組元素copy到本地高速緩存中
- memcpy(&(shared_array->entry[shared_array->avail]),
- ac->entry, sizeof(void *) * batchcount);
- shared_array->avail += batchcount;
- goto free_done;
- }
- }
- //在沒有本地高速緩存的情況下,釋放回slab中
- free_block(cachep, ac->entry, batchcount, node);
- free_done:
- spin_unlock(&l3->list_lock);
- ac->avail -= batchcount;
- //將刪除后剩下的空閑對象往前移動一下,hoho,可能還剩下些空閑對象
- memmove(ac->entry, &(ac->entry[batchcount]), sizeof(void *)*ac->avail);
- }
- static void free_block(struct kmem_cache *cachep, void **objpp, int nr_objects,
- int node)
- {
- int i;
- struct kmem_list3 *l3;
- for (i = 0; i < nr_objects; i++) {
- void *objp = objpp[i];
- struct slab *slabp;
- //先從對象獲取到其所在的page,再從page得到其所屬的slab
- //page->lru.prev中記錄了page所屬的slab
- slabp = virt_to_slab(objp);
- l3 = cachep->nodelists[node];
- list_del(&slabp->list);
- check_spinlock_acquired_node(cachep, node);
- check_slabp(cachep, slabp);
- //放入對應(yīng)的slab
- slab_put_obj(cachep, slabp, objp, node);
- STATS_DEC_ACTIVE(cachep);
- l3->free_objects++;
- check_slabp(cachep, slabp);
- /* fixup slab chains */
- //slab所有的對象都已經(jīng)被歸還
- if (slabp->inuse == 0) {
- //slab高速緩存的空閑對象數(shù)超過了限制,可以釋放掉該slab,以
- //釋放其所占有的內(nèi)存
- if (l3->free_objects > l3->free_limit) {
- l3->free_objects -= cachep->num;
- slab_destroy(cachep, slabp);
- } else {
- //加入到完全空閑slab鏈表中
- list_add(&slabp->list, &l3->slabs_free);
- }
- } else {
- //加入到部分空閑的slab鏈表中
- list_add_tail(&slabp->list, &l3->slabs_partial);
- }
- }
- }