虛擬化實戰(zhàn):Cluster設(shè)計之三HA
一 為什么使用HA
高可用性是虛擬化平臺最突出的特性之一,設(shè)置和維護非常簡單,技術(shù)非常成熟。對于一些非常關(guān)鍵的應(yīng)用,可能對容災(zāi)的要求特別高,可以考慮采用基于應(yīng)用層的HA,或者操作系統(tǒng)層的HA,比如MSCS。虛擬層的HA是在底層架構(gòu)上實現(xiàn)的高可用性,在恢復(fù)時間可接受的情況下是非常好的選擇。
相對應(yīng)用層和操作系統(tǒng)層HA而言,vSphere HA以較低的成本實現(xiàn)了整個集群的高可用性,同時實施和維護都十分的簡單。無需在應(yīng)用或者VM上作任何設(shè)置或改動。
二 HA是如何工作的?
HA Agent
vSphere5.0之后的版本對架構(gòu)作了很多的改動。摒棄了原來Cluster中的Primary Node和Secondary Nodes的概念。并且引入了Master HAagent 和 Slave HA Agent的概念。通常情況下一個Cluster中僅有一個Master HA Agent。HA Agent有以下的功能:
-與vCenter互相交換信息
-Master HA Agent監(jiān)控VM的狀態(tài),在其出現(xiàn)問題時重啟
-Slave HA Agent把VM的狀態(tài)信息傳遞給Master HA Agent, 并且在MasterAgent 的指令下重啟VM
-檢測VM上運行的應(yīng)用的狀態(tài)
當(dāng)Master HA所在的主機出現(xiàn)問題時,其他主機上的Agent開始參與競選成為MasterHA, 連接DataStore數(shù)目最多的主機會成為Master。如果兩臺主機DataStore數(shù)目相同,Managed Object Id較高的主機會成為Master。
HeartBeating
用來判斷主機是否仍然正常運行。
Network Heartbeating
每臺Slave都和Master主機互相發(fā)送Heartbeat信息。
Datastore Heartbeating
有的情況下Management網(wǎng)絡(luò)中斷之后,如果VM還能夠繼續(xù)訪問其他網(wǎng)絡(luò)和存儲,那么就無需對被隔離主機上的VM采取響應(yīng)措施。這是就需要檢測Datastore Heartbeating來進一步驗證。
對于Converged Infrastructure,比如Cisco UCS等系統(tǒng),Datastore Heartbeating能起的作用不大,因為管理網(wǎng)絡(luò)和存儲共用物理鏈路,在管理網(wǎng)絡(luò)中斷的情況下,存儲很可能也無法訪問了。
主機隔離
檢測: 在某個主機無法與Management Network通訊時,也就是ping isolation Address失敗后,該主機會被認為處于隔離狀態(tài)。 Management Network的網(wǎng)關(guān)缺省作為isolationAddress。 為了增加可靠性和避免誤判,可以設(shè)置多個isolationAddress
響應(yīng):
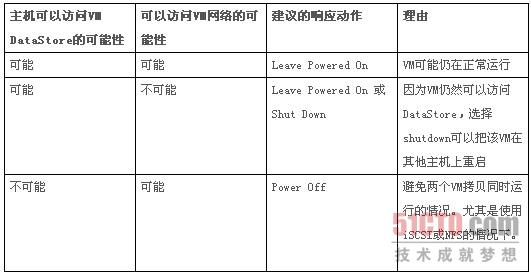
下面的分析幫助你在確認主機處于隔離狀態(tài)后,選擇合適的響應(yīng)動作
 #p#
#p#
以上僅僅是建議參考,Leave Powered On適用于大多數(shù)的情況。因為虛擬化設(shè)計大多考慮了網(wǎng)絡(luò)的冗余,出現(xiàn)HostIsolation本來就是很少見的情況。
在使用iSCSI或NFS的情況下,如果你估計管理網(wǎng)絡(luò)中斷的同時,可能存儲網(wǎng)絡(luò)也會中斷。考慮使用PowerOff. 在主機無法訪問存儲時,HAAgent會在其他主機上啟動VM的第二個Instance.而此時第一個Instance仍然在被隔離的主機上運行,當(dāng)所有網(wǎng)絡(luò)正常恢復(fù)時,這可能會造成很麻煩的情況。因為同一個VM有兩個Instance同時運行。
Admission Control
用來保證在主機出問題時,Cluster有充足的資源供問題主機上的VM使用。
有以下策略可供選擇:
1 Define failover capacity bystatic number of hosts
2 Use dedicated failover hosts
3 Define failover capacity byreserving a percentage of the cluster
resources
第三種方式,也就是用百分比方式定義Failover Capacity,適用于大多數(shù)情況。最大可能的高效使用資源,從而可以運行較多的VM。
三基本設(shè)計原則
HA策略中優(yōu)先啟動vCenter以及較重要的VM。比如DNS,AD,MS SQL等。同時需要注意HA并不能完全保證VM重啟的順序。如果VM之間有復(fù)雜的依賴關(guān)系以及嚴格的啟動順利,可以考慮VMware SRM。
如果維護可能造成Management Network的中斷,考慮暫時屏蔽HA,避免觸發(fā)HA的隔離響應(yīng)措施
最好每臺主機有一致的CPU和RAM配置。如果一個Cluster中某個主機有較高的配置,HA的策略需要保證有充足的資源來保證運行該主機的VM
雖然多個Cluster可以共享同一個DataStore,但最好還是為每個Cluster分配專屬的Datastore。這樣可以簡化管理,同時在某主機被隔離后,HA可以較容易的重啟VM。
一定注意Management Network的冗余。 因為HA的Network Heartbeating依賴于ManagementNetwork
在Stretched Cluster情況下,也就是Cluster中的主機和存儲分布在兩個間隔較遠的數(shù)據(jù)中心,建議最少設(shè)置4個HeartbeatDatastore. 每個數(shù)據(jù)中心設(shè)置2個。
參考:
VMware vSphere 5.1 ClusteringDeepdive by Duncan Epping
HAArchitecture Decision by Josh Odgers
vSphereAvailability Guide
VMware vSphere High Availability5.0 Deployment Best Practices
原創(chuàng)作品,允許轉(zhuǎn)載,轉(zhuǎn)載時請務(wù)必以超鏈接形式標明文章 原始出處 、作者信息和本聲明。否則將追究法律責(zé)任。http://frankfan.blog.51cto.com/6402282/1329945