













用 Python 腳本實現(xiàn)對 Linux 服務器的監(jiān)控
目前 Linux 下有一些使用 Python 語言編寫的 Linux 系統(tǒng)監(jiān)控工具 比如 inotify-sync(文件系統(tǒng)安全監(jiān)控軟件)、glances(資源監(jiān)控工具)等,在實際工作中,Linux 系統(tǒng)管理員可以根據(jù)自己使用的服務器的具體情況編寫一下簡單實用的腳本實現(xiàn)對 Linux 服務器的監(jiān)控。 本文介紹一下使用 Python 腳本實現(xiàn)對 Linux 服務器 CPU 內(nèi)存 網(wǎng)絡的監(jiān)控腳本的編寫。
Python 版本說明
Python 是由 Guido van Rossum 開發(fā)的、可免費獲得的、非常高級的解釋型語言。其語法簡單易懂,而其面向?qū)ο蟮恼Z義功能強大(但又靈活)。Python 可以廣泛使用并具有高度的可移植性。本文 Linux 服務器是 Ubuntu 12.10, Python 版本 是 2.7 。如果是 Python 3.0 版本的語法上有一定的出入。另外這里筆者所說的 Python 是 CPython,CPython 是用 C 語言實現(xiàn)的 Python 解釋器,也是官方的并且是最廣泛使用的Python 解釋器。除了 CPython 以外,還有用 Java 實現(xiàn)的 Jython 和用.NET 實現(xiàn)的 IronPython,使 Python方便地和 Java 程序、.NET 程序集成。另外還有一些實驗性的 Python 解釋器比如 PyPy。CPython 是使用字節(jié)碼的解釋器,任何程序源代碼在執(zhí)行之前先要編譯成字節(jié)碼。它還有和幾種其它語言(包括 C 語言)交互的外部函數(shù)接口。
工作原理:基于/proc 文件系統(tǒng)
Linux 系統(tǒng)為管理員提供了非常好的方法,使其可以在系統(tǒng)運行時更改內(nèi)核,而不需要重新引導內(nèi)核系統(tǒng),這是通過/proc 虛擬文件系統(tǒng)實現(xiàn)的。/proc 文件虛擬系統(tǒng)是一種內(nèi)核和內(nèi)核模塊用來向進程(process)發(fā)送信息的機制(所以叫做“/proc”),這個偽文件系統(tǒng)允許與內(nèi)核內(nèi)部數(shù)據(jù)結(jié)構(gòu)交互,獲取有關進程的有用信息,在運行中(on the fly)改變設置(通過改變內(nèi)核參數(shù))。與其他文件系統(tǒng)不同,/proc 存在于內(nèi)存而不是硬盤中。proc 文件系統(tǒng)提供的信息如下:
- 進程信息:系統(tǒng)中的任何一個進程,在 proc 的子目錄中都有一個同名的進程 ID,可以找到 cmdline、mem、root、stat、statm,以及 status。某些信息只有超級用戶可見,例如進程根目錄。每一個單獨含有現(xiàn)有進程信息的進程有一些可用的專門鏈接,系統(tǒng)中的任何一個進程都有一個單獨的自鏈接指向進程信息,其用處就是從進程中獲取命令行信息。
- 系統(tǒng)信息:如果需要了解整個系統(tǒng)信息中也可以從/proc/stat 中獲得,其中包括 CPU 占用情況、磁盤空間、內(nèi)存對換、中斷等。
- CPU 信息:利用/proc/CPUinfo 文件可以獲得中央處理器的當前準確信息。
- 負載信息:/proc/loadavg 文件包含系統(tǒng)負載信息。
- 系統(tǒng)內(nèi)存信息:/proc/meminfo 文件包含系統(tǒng)內(nèi)存的詳細信息,其中顯示物理內(nèi)存的數(shù)量、可用交換空間的數(shù)量,以及空閑內(nèi)存的數(shù)量等。
表 1 是 /proc 目錄中的主要文件的說明:
表 1 /proc 目錄中的主要文件的說明
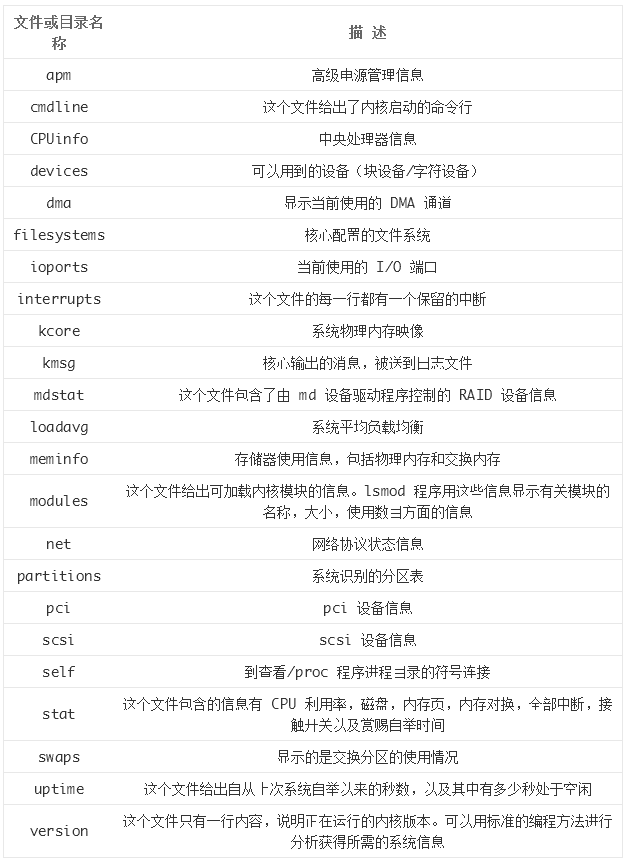
下面本文的幾個例子都是使用 Python 腳本讀取/proc 目錄中的主要文件來實現(xiàn)實現(xiàn)對 Linux 服務器的監(jiān)控的 。
#p#
使用 Python 腳本實現(xiàn)對 Linux 服務器的監(jiān)控
- 對于 CPU(中央處理器)監(jiān)測
腳本 1 名稱 CPU1.py,作用獲取 CPU 的信息。
清單 1.獲取 CPU 的信息:
- #!/usr/bin/env Python
- from __future__ import print_function
- from collections import OrderedDict
- import pprint
- def CPUinfo():
- ''' Return the information in /proc/CPUinfo
- as a dictionary in the following format:
- CPU_info['proc0']={...}
- CPU_info['proc1']={...}
- '''
- CPUinfo=OrderedDict()
- procinfo=OrderedDict()
- nprocs = 0
- with open('/proc/CPUinfo') as f:
- for line in f:
- if not line.strip():
- # end of one processor
- CPUinfo['proc%s' % nprocs] = procinfo
- nprocsnprocsnprocs=nprocs+1
- # Reset
- procinfo=OrderedDict()
- else:
- if len(line.split(':')) == 2:
- procinfo[line.split(':')[0].strip()] = line.split(':')[1].strip()
- else:
- procinfo[line.split(':')[0].strip()] = ''
- return CPUinfo
- if __name__=='__main__':
- CPUinfoCPUinfoCPUinfo = CPUinfo()
- for processor in CPUinfo.keys():
- print(CPUinfo[processor]['model name'])
簡單說明一下清單 1,讀取/proc/CPUinfo 中的信息,返回 list,每核心一個 dict。其中 list 是一個使用方括號括起來的有序元素集合。List 可以作為以 0 下標開始的數(shù)組。Dict 是 Python 的內(nèi)置數(shù)據(jù)類型之一, 它定義了鍵和值之間一對一的關系。OrderedDict 是一個字典子類,可以記住其內(nèi)容增加的順序。常規(guī) dict 并不跟蹤插入順序,迭代處理時會根據(jù)鍵在散列表中存儲的順序來生成值。在 OrderedDict 中則相反,它會記住元素插入的順序,并在創(chuàng)建迭代器時使用這個順序。
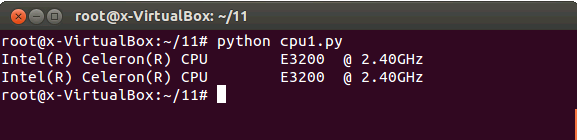
可以使用 Python 命令運行腳本 CPU1.py 結(jié)果見圖 1:
- # Python CPU1.py
- Intel(R) Celeron(R) CPU E3200 @ 2.40GHz
圖 1.運行清單 1
也可以使用 chmod 命令添加權(quán)限收直接運行 CPU1.py:
- #chmod +x CPU1.py
- # ./CPU1.py
- 對于系統(tǒng)負載監(jiān)測
腳本 2 名稱 CPU2.py,作用獲取系統(tǒng)的負載信息
清單 2 獲取系統(tǒng)的負載信息:
- #!/usr/bin/env Python
- import os
- def load_stat():
- loadavg = {}
- f = open("/proc/loadavg")
- con = f.read().split()
- f.close()
- loadavg['lavg_1']=con[0]
- loadavg['lavg_5']=con[1]
- loadavg['lavg_15']=con[2]
- loadavg['nr']=con[3]
- loadavg['last_pid']=con[4]
- return loadavg
- print "loadavg",load_stat()['lavg_15']
簡單說明一下清單 2:清單 2 讀取/proc/loadavg 中的信息,import os :Python 中 import 用于導入不同的模塊,包括系統(tǒng)提供和自定義的模塊。其基本形式為:import 模塊名 [as 別名],如果只需要導入模塊中的部分或全部內(nèi)容可以用形式:from 模塊名 import *來導入相應的模塊。OS 模塊 os 模塊提供了一個統(tǒng)一的操作系統(tǒng)接口函數(shù),os 模塊能在不同操作系統(tǒng)平臺如 nt,posix 中的特定函數(shù)間自動切換,從而實現(xiàn)跨平臺操作。
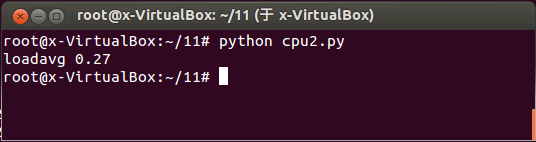
可以使用 Python 命令運行腳本 CPU1.py 結(jié)果見圖 2:
- # Python CPU2.py
圖 2.運行清單 2
- 對于內(nèi)存信息的獲取
腳本 3 名稱 mem.py,作用是獲取內(nèi)存使用情況信息。
清單 3 獲取內(nèi)存使用情況:
- #!/usr/bin/env Python
- from __future__ import print_function
- from collections import OrderedDict
- def meminfo():
- ''' Return the information in /proc/meminfo
- as a dictionary '''
- meminfo=OrderedDict()
- with open('/proc/meminfo') as f:
- for line in f:
- meminfo[line.split(':')[0]] = line.split(':')[1].strip()
- return meminfo
- if __name__=='__main__':
- #print(meminfo())
- meminfomeminfo = meminfo()
- print('Total memory: {0}'.format(meminfo['MemTotal']))
- print('Free memory: {0}'.format(meminfo['MemFree']))
簡單說明一下清單 3:清單 3 讀取 proc/meminfo 中的信息,Python 字符串的 split 方法是用的頻率還是比較多的。比如我們需要存儲一個很長的數(shù)據(jù),并且按照有結(jié)構(gòu)的方法存儲,方便以后取數(shù)據(jù)進行處理。當然可以用 json 的形式。但是也可以把數(shù)據(jù)存儲到一個字段里面,然后有某種標示符來分割。 Python 中的 strip 用于去除字符串的首位字符,最后清單 3 打印出內(nèi)存總數(shù)和空閑數(shù)。
#p#
可以使用 Python 命令運行腳本 mem.py 結(jié)果見圖 3。
- # Python mem.py
圖 3.運行清單 3

- 對于網(wǎng)絡接口的監(jiān)測
腳本 4 名稱是 net.py,作用獲取網(wǎng)絡接口的使用情況。
清單 4 net.py 獲取網(wǎng)絡接口的輸入和輸出:
- #!/usr/bin/env Python
- import time
- import sys
- if len(sys.argv) > 1:
- INTERFACE = sys.argv[1]
- else:
- INTERFACE = 'eth0'
- STATS = []
- print 'Interface:',INTERFACE
- def rx():
- ifstat = open('/proc/net/dev').readlines()
- for interface in ifstat:
- if INTERFACE in interface:
- stat = float(interface.split()[1])
- STATS[0:] = [stat]
- def tx():
- ifstat = open('/proc/net/dev').readlines()
- for interface in ifstat:
- if INTERFACE in interface:
- stat = float(interface.split()[9])
- STATS[1:] = [stat]
- print 'In Out'
- rx()
- tx()
- while True:
- time.sleep(1)
- rxstat_o = list(STATS)
- rx()
- tx()
- RX = float(STATS[0])
- RX_O = rxstat_o[0]
- TX = float(STATS[1])
- TX_O = rxstat_o[1]
- RX_RATE = round((RX - RX_O)/1024/1024,3)
- TX_RATE = round((TX - TX_O)/1024/1024,3)
- print RX_RATE ,'MB ',TX_RATE ,'MB'
簡單說明一下清單 4:清單 4 讀取/proc/net/dev 中的信息,Python 中文件操作可以通過 open 函數(shù),這的確很像 C 語言中的 fopen。通過 open 函數(shù)獲取一個 file object,然后調(diào)用 read(),write()等方法對文件進行讀寫操作。另外 Python 將文本文件的內(nèi)容讀入可以操作的字符串變量非常容易。文件對象提供了三個“讀”方法: read()、readline() 和 readlines()。每種方法可以接受一個變量以限制每次讀取的數(shù)據(jù)量,但它們通常不使用變量。 .read() 每次讀取整個文件,它通常用于將文件內(nèi)容放到一個字符串變量中。然而 .read() 生成文件內(nèi)容最直接的字符串表示,但對于連續(xù)的面向行的處理,它卻是不必要的,并且如果文件大于可用內(nèi)存,則不可能實現(xiàn)這種處理。.readline() 和 .readlines() 之間的差異是后者一次讀取整個文件,象 .read() 一樣。.readlines() 自動將文件內(nèi)容分析成一個行的列表,該列表可以由 Python 的 for … in … 結(jié)構(gòu)進行處理。另一方面,.readline() 每次只讀取一行,通常比 .readlines() 慢得多。僅當沒有足夠內(nèi)存可以一次讀取整個文件時,才應該使用 .readline()。最后清單 4 打印出網(wǎng)絡接口的輸入和輸出情況。
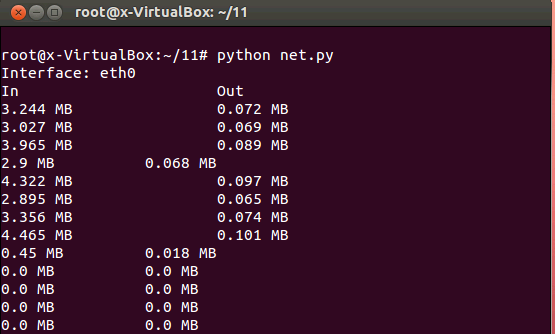
可以使用 Python 命令運行腳本 net.py 結(jié)果見圖 4
- #Python net.py
圖 4.運行清單 4
監(jiān)控 Apache 服務器進程的 Python 腳本
Apache 服務器進程可能會因為系統(tǒng)各種原因而出現(xiàn)異常退出,導致 Web 服務暫停。所以筆者寫一個 Python 腳本文件:
清單 5 crtrl.py 監(jiān)控 Apache 服務器進程的 Python 腳本:
- #!/usr/bin/env Python
- import os, sys, time
- while True:
- time.sleep(4)
- try:
- ret = os.popen('ps -C apache -o pid,cmd').readlines()
- if len(ret) < 2:
- print "apache 進程異常退出, 4 秒后重新啟動"
- time.sleep(3)
- os.system("service apache2 restart")
- except:
- print "Error", sys.exc_info()[1]
設置文件權(quán)限為執(zhí)行屬性(使用命令 chmod +x crtrl.py),然后加入到/etc/rc.local 即可,一旦 Apache 服務器進程異常退出,該腳本自動檢查并且重啟。 簡單說明一下清單 5 這個腳本不是基于/proc 偽文件系統(tǒng)的,是基于 Python 自己提供的一些模塊來實現(xiàn)的 。這里使用的是 Python 的內(nèi)嵌 time 模板,time 模塊提供各種操作時間的函數(shù)。
總結(jié)
在實際工作中,Linux 系統(tǒng)管理員可以根據(jù)自己使用的服務器的具體情況編寫一下簡單實用的腳本實現(xiàn)對 Linux 服務器的監(jiān)控。本文介紹一下使用 Python 腳本實現(xiàn)對 Linux 服務器 CPU 、系統(tǒng)負載、內(nèi)存和 網(wǎng)絡使用情況的監(jiān)控腳本的編寫方法。












