Hadoop日志分析工具:White Elephant
代碼在GitHub上的鏈接https://github.com/linkedin/white-elephant。
快速入門
你可以在GitHub上的 White Elephant項目check out代碼,或者下載***的snapshot版本。
可以使用一些測試數據嘗試這個服務:
- cd server
- ant
- ./startup.sh
然后訪問 http://localhost:3000。它可能需要幾分鐘的時間加載測試數據。
服務端
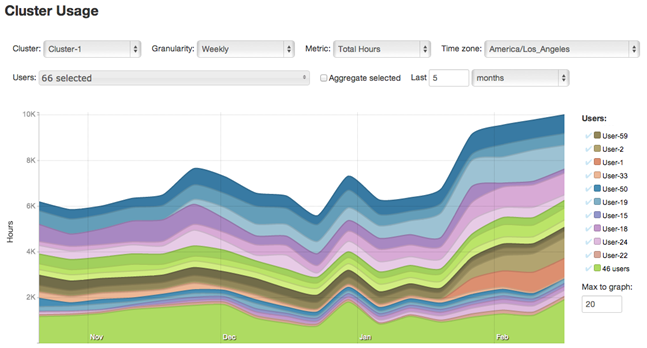
服務端是一個JRuby的web應用,在生產環境中它可以部署到tomcat中,然后可以直接從Hadoop中讀取收集到的數據。數據存儲在 HyperSQL提供的 in-memory 類型的數據庫中,圖表由 Rickshaw提供。
開始使用
開始使用這個服務之前,首先需要設置環境:
- cd server
- ant
默認會做以下的事情:
-
安裝JRuby 到 .rbenv下的本地目錄
-
安裝RubyRuby gems到上述目錄
-
下載JAR包
-
在 data/usage下創建測試數據
這時候你可以通過下面的命令啟動服務:
./startup.sh
你可以訪問 http://localhost:3000,它可能需要幾分鐘的時間加載測試數據。
這里使用trinidad在開發環境中運行JRuby 網頁應用。由于這是在開發模式,應用假設本地數據(在config.yml中指定的路徑)可以使用。
配置
服務端的配置在config.yml中指定,你可以在sample_config.yml中查看示例。
當通過./startup.sh 運行在開發模式中時,sample_config.yml會被使用,并且它和 local目錄下的配置一起生效。這里唯一的可配置參數是file_pattern,它指定了從本地加載數據的目錄。
當打包成WAR并運行在生產模式下,使用hadoop下指定的配置,假設收集到的數據可用,下述配置必須指定:
file_pattern: 從Hadoop加載使用文件的全局的文件模式。
libs: 包含Hadoop JAR文件的目錄 (加到classpath)。
conf_dir: 包含Hadoop配置的目錄(加到 classpath)。
principal: 用戶名用于訪問安全的Hadop。
keytab: keytab 文件的路徑,用于訪問安全的Hadoop 。
White Elephant并不基于某個特定版本的Hadoop,所以JARs并不會打包到WAR包中。因此配置中必須指定到Hadoop JARs的路徑。
部署
編譯一個可以部署到tomcat的WAR文件:
- ant war -Dconfig.path=<path-to-config>
你指定的配置文件config.yml將一起打包到WAR文件中。
Hadoop日志上傳
hadoop/scripts/statsupload.pl腳本可以用于上傳Hadoop日志文件到HDFS,主要就可以被處理了。
Hadoop 作業
一共兩個Hadoop作業,都被一個作業執行器管理,并追蹤需要的工作。
***個作業是Hadoop日志解析器,它從存儲在Hadoop中的文件讀日志,解析出相應的信息,并以Avro的格式寫出去。
第二個作業讀取Avro格式的日志數據,并以小時為單位聚合,數據以Avro格式寫出去,它本質上建立一共數據立方體,可以很容易的被wen應用加載到DB和查詢。
配置
示例配置存儲在 hadoop/config/jobs:
base.properties: 包括大多配置。
white-elephant-full-usage.job: 處理所有日志時被使用的作業文件。
white-elephant-incremental-usage.job: 處理增量日志時需要的作業文件。
base.properties文件包括White Elephant指定的配置,也包括Hadoop配置。所有Hadoop配置參數以hadoop-conf開頭。兩個job的配置項相同,當然其值需要根據作業配置。
Hadoop 日志
在base.properties中存在一個參數log.root。這是解析程序查找Hadoop日志的根目錄。解析作業假設日志存儲在Hadoop每天的目錄下,目錄格式如下:
- <logs.root>/<cluster-name>/daily/<yyyy>/<MMdd>
例如,2013年1月23日的目錄格式為:
- /data/hadoop/logs/prod/daily/2013/0123
打包
創建一個包含所有文件的zip包可以通過下述命令生成:
ant zip -Djob.config.dir=<path-to-job-config-dir>
job.config.dir應該包含.properties和.job文件。
如果你使用 Azkaban作為你的作業調度器,則zip文件可以工作到base.propreties中指定的配置的時間。
運行
解壓zip文件后可以運行run.sh腳本,這需要配置兩個環境變量:
-
HADOOP_CONF_DIR: Hadoop configuration directory
-
HADOOP_LIB_DIR: Hadoop JARs directory
運行全量job:
- ./run.sh white-elephant-full-usage.job
運行增量job:
- ./run.sh white-elephant-incremental-usage.job
增量作業只處理增量數據,全量作業處理所有數據。
原文鏈接:http://www.cnblogs.com/shenh062326/p/3544868.html