













淘寶主搜索離線集群完成Hadoop 2.0升級
搜索離線dump集群(hadoop&hbase)2013進行了幾次重大升級:
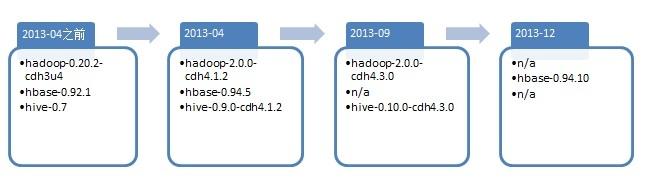
2013-04
第一階段,主要是升級hdfs為2.0版本,mapreduce仍舊是1.0;同時hbase也進行了一次重大升級(0.94.5版本),hive升級到0.9.0;
2013-09,2013-12
第二階段,主要升級mapreduce到2.0版本即(YARN),hive升級到0.10.0,在13年年底的時候對hbase進行了一次小版本升級;
至此,dump離線集群完全進入2.0時代:
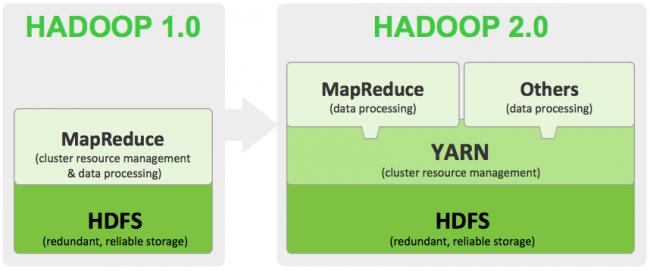
通過升級hdfs 2.0優化shortcircuit read,使用domain socket通信等等提升了效率,加快了任務運行速度,同時支持成熟的NAMENODE HA,Federation,解決了讓大家擔心的集群NN單點問題,集群容量和擴展性得到大大提升。
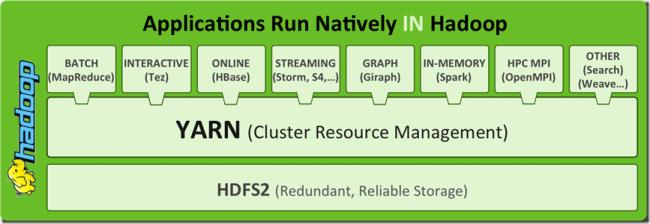
通過升級yarn對集群資源進行更有效的管理,摒棄了slots的物理劃分,采用內存資源控制使集群資源被更有效的利用,從而提高整個集群的吞吐,同時支持豐富的計算框架,為后續DUMP應用架構優化調整提供了廣闊的舞臺。
當然集群的升級過程也遇到了很多問題和困難
第一階段升級過程中遇到的主要問題:
1、hdfs升級為2.0后,需要同時升級下hive版本(hive-0.9.0-cdh4.1),之前使用老版本hive jar編譯的任務需要使用新版本jar包重新編譯
2、mr1任務要運行在hdfs 2.0上部分任務會運行失敗,主要是2.0中將原來的class換成了interface,需要重新編譯即可,少量代碼需要添加下throws IOException,依賴的hadoop-core jar包也被拆分成了幾個(common,hdfs,mr1等)
3、hdfs shell命令差異,主要是針對mkdir或者touchz等中間如果有不存在的路徑不會自動創建
4、從云梯distcp數據由于hdfs版本不兼容,必須使用hftp的方式,且因hftp不支持密碼訪問,后來patch解決
5、升級hdfs 2.0后集群整體讀I/O升高明顯,從而導致特別是I/O需求高的build任務延時
原因是2.0對dfs.client.read.shortcircuit的調整,在檢查是否有權限(dfs.block.local-path-access.user中配置的用戶名)進行shortcircuit讀取時如果沒有權限會將本地的datanode作為deadnode處理,然后數據通過遠程讀取。又因為hbase中dfs.client.read.shortcircuit.buffer.size設置的值不合適導致多讀了很多無謂的數據,導致整個集群I/O升高。
解決方案:
設置dfs.client.read.shortcircuit.buffer.size=16K與hbase的block的大小相匹配。
詳細的分析過程見:
http://www.atatech.org/article/detail/2733/193
http://www.atatech.org/article/detail/7207/193
第二階段升級遇到的主要問題:
1、升級到yarn后,Capacity Schedule進行了更新,job提交只需要指定葉子queue名字即可,指定全路徑會報錯;
2、沒有了map/reduce slots的概念,集群只需配置可用的內存大小,主要的參數:
集群:
yarn.nodemanager.resource.memory-mb: 一個nodemanager上可分配給container使用的物理內存大小 yarn.scheduler.minimum-allocation-mb: resource manage分配內存的最小粒度,暫設成1024,job提交需要內存必須為此參數的整數倍 yarn.scheduler.capacity.<queue>.maximum-am-resource-percent: am所占資源比例,可按queue設,暫設成0.3 yarn.scheduler.capacity.<queue>.user-limit-factor: 單個用戶提交job限制,可按queue設,單用戶如要搶占最大資源,需要設大
應用:
mapreduce.map.memory.mb,mapreduce.reduce.memory.mb: map,reduce的內存數,默認是1024,2048,如需設大,必須是1024的整數倍,可以簡單理解為之前的slots數配置 mapreduce.map.java.opts,mapreduce.reduce.java.opts: java child進程的jvm heap大小,比上面的值小些 mapreduce.job.reduce.slowstart.completedmaps: 對于map數較多需要跑多輪,可以設大此值,延遲reduce啟動避免占用資源
3、yarn中不在兼容commons-cli-2.0-SNAPSHOT.jar,之前通過將該jar文件copy到hadoop classpath中使用的應用需要部署到各自應用的相關目錄下,并在提交任務的時候引用
4、一些使用0.19等老版本的hadoop-streaming.jar需要更換為新版本
5、container內存超配被kill掉,考慮到job內存的自然增長及一些使用共享內存的任務,所以設置yarn.nodemanager.vmem-pmem-ratio=false關閉物理內存檢查
6、客戶端向AM獲取job status報錯:IOException
原因是AM內存設置太小,頻繁GC導致,通過調大yarn.app.mapreduce.am.resource.mb解決
7、c2c_merge任務在yarn上運行緩慢
經過排查分析是因使用的mmap文件在pagecache中頻繁換進換出導致,根本原因還是18與32內核的差異,因為集群升級過程中也對內核進行了升級,通過修改應用代碼。
去除madvise設置的MADV_SEQUENTIA后問題解決,參考:
http://baike.corp.taobao.com/index.php/Kbuild在32內核上性能退化問題
8、IPV4和IPV6差異引起的長短機器名問題及job data local比例低的問題
在yarn resource manager下顯示部分機器是長機器名,部分機器是短機器名。
hbase集群下顯示全是長機器名,原因是yarn與hbase獲取機器名調用的方法不一樣,得到的結果也不一樣,導致resourcemanager在分配container時進行優先的host匹配是匹配不上,最后變成任意匹配導致。
獲取機器名差異的根本原因經過分析是java處理ipv6有bug和yarn腳本bug共同導致。
http://bugs.sun.com/view_bug.do?bug_id=7166687
http://www.atatech.org/article/detail/10731/193
解決方案1:修改yarn腳本,并提交issue到社區:https://issues.apache.org/jira/browse/YARN-1226
解決方案2:給集群配置上機架感知,且讓一個機器一個rack的虛擬機架配置,通過rack匹配繞開任意匹配,在http://www.atatech.org/article/detail/10731/193 中有詳細分析
9、由于我們當時在方案1還未得出結論前臨時采用方案2快速解決線上data local低的問題后發現有部分任務提交失敗報錯: Max block location exceeded for split
原因是:配置了一個節點一個機架后CombineFileInputFormat獲取split的block localtion時會根據block分布在哪些rack上獲取locations信息,由于機架數等同于機器數,獲取到的localtions數會超過集群的默認配置:
mapreduce.job.max.split.locations = 10,而yarn上修改了代碼會在超出這個配置值時拋出異常,所以任務提交失敗。
解決方案1:增大mapreduce.job.max.split.locations和集群節點數一致;
解決方案2:patch修改JobSplitWriter中超過配置值拋異常為打印警告日志,與升級前一致。
詳情見:http://www.atatech.org/article/detail/11707/193
10、gcih不能正常工作
GCIH:http://baike.corp.taobao.com/index.php/GCIH
不能正常工作的原因有兩個:
- 集群升級到yarn后,nm管理job臨時目錄和distribute file的方式與tt不同,導致GCIH會生成多個mmap文件gcih.dat
- 在修復上述問題的過程中,發現散列到不同磁盤上task,jvm classpath加載順序不一致,導致GCIH不能正常工作
解決方案:升級GCIH
將gcih.dat生成到gcih.jar軟連對應的源目錄下,這樣一個job只會有一個,調整gcih.jar的加載順序,放到preload里。
11、集群資源使用100%,job一直hang住
當集群root跑滿100%而下面的子queue未滿時(因為希望集群的資源共享競爭,queue的最大可用資源會進行適當的超配),不會觸發搶占reduce資源的過程。
解決方案:
- 不同queue的大任務盡量避開運行
- 后續patch修改在root滿時觸發搶占
詳細分析過程見:http://www.atatech.org/article/detail/10924/193
12、load任務寫hbase偶爾會卡住
原因是當集群中有節點掛掉或者網絡等出現異常可能會導致hbaseclient在select時無線等待,而鎖無法釋放
解決方案:在hbase client的代碼里設置超時時間。
具體原因分析見:http://www.atatech.org/article/detail/9061/193
13、集群有節點出現問題,上面的任務一直失敗,后續別的任務起來后還會將container分配到這個節點。原因是yarn和之前mr1黑名單機制發生了改變,mr1是全局的黑名單,一旦被加入黑名單后續任務不會再分配,yarn的黑名單是在AM上的,也就是任務級別的,被AM加入黑名單后可以保證當前任務不會被分配上去,但是其他任務的AM中是沒有這個信息的,所以還是會分配任務上去。
解決方案:等待NM將節點健康信息匯報給RM,RM將節點從集群摘除
如果一直無法匯報,可以通過yarn支持的外圍用戶腳本來做健康檢查和匯報(需要在yarn配置中配置該腳本)
詳細分析見:http://www.atatech.org/article/detail/11266/193
hive相關:
1、out join被拆成多個job
問題發現:loader在做多表join的過程時原來的一個job被hive拆成了8個job,耗時由原來的3分鐘變成30分鐘。
通過patch解決,參考:
http://mail-archives.apache.org/mod_mbox/hive-user/201305.mbox/+r2mdv_tsofa@mail.gmail.com>
https://issues.apache.org/jira/browse/HIVE-4611
2、設置mapreduce.map.tasks不生效
分析是Hive的InputFormat的問題。
如InputFormat設置為org.apache.hadoop.hive.ql.io.CombineHiveInputFormat,需要設置mapreduce.input.fileinputformat.split.maxsize來控制map的個數;
如InputFormat設置為org.apache.hadoop.hive.ql.io.HiveInputFormat,則此參數生效;
解決方案:將hive配置中默認的InputFormat配置成org.apache.hadoop.hive.ql.io.HiveInputFormat
3、寫redis的hive job拆成了兩個job
hive默認設置中,當map輸出文件太小,會新起一個job合并小文件
解決方案:set hive.merge.mapfiles=false;
仍然存在待解決的問題:
1)有部分job會導致單disk io到100%,拖慢這個任務;
2)機器出現異常問題,task全部都在localizing,job一直pending,只能kill掉重新提交;
3)job或者task被kill掉后,日志也被刪除,history中看不到該job的信息,排查問題困難;
集群HADOOP 2.0的升級,在更好的支持現有業務:主搜,商城,店鋪內,PORA個性化,尼米茲平臺,中文站(offer,company,minisearch),國際站(ae,sc,p4p,aep4p,scp4p)的基礎上為后續離線dump平臺:ADUMP的建設夯實了基礎。
一個統一存儲,模塊插件化設計,減少各業務線之間數據冗余,避免重復開發,同時支持快速響應各條業務線新需求的全新平臺ADUMP將在3月底左右上線,緊跟集群升級的節奏,離線DUMP也將馬上進入2.0時代,敬請期待!












