













Cloudera將Spark劃入Hadoop
作者:佚名
Spark作為一個通用的并行計算框架,已經成為繼Hadoop之后又一大熱門開元項目,逐漸獲得很多企業的支持。近日,Cloudera正式宣布開始商業支持Apache Spark 機器學習和數據流處理環境。
Spark內存計算框架適合各種迭代算法和交互式數據分析,能夠提升大數據處理的實時性和準確性。而MapReduce處理框架則擅長復雜的批處理操作、登陸過濾、ETL(數據抽取、轉換、加載)、網頁索引等應用,MapReduce在低延遲業務上一直被人所詬病。
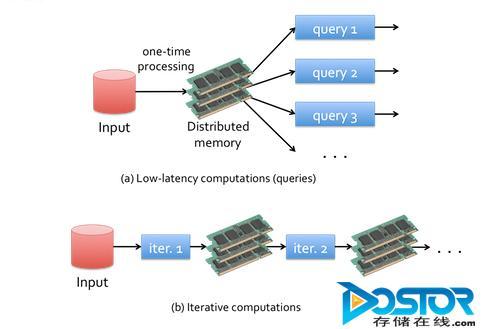
圖一:Spark內存計算框架
“Spark記錄著數據產生的每一個操作,能夠可靠地將這些數據存儲在內存之中,這使得它非常適用于第掩飾的計算和有效的迭代算法。”Cloudera表示。
據悉,Cloudera Enterprise Data Hub版本提供多種先進的組件的無限支持,如交互式SQL分析的Impala、交互式搜索、導航數據管理以及Hbase NoSQL。Enterprise Flex版本則提供可選擇組件版本,Enterprise Basic版本則是僅僅提供Hadoop基礎核心組件。
根據Cloudera介紹,Cloudera將會在兩個版本中安裝支持Spark組件。用戶可以利用它作為Enterprise Flex版本中一個可選組件,或者作為Enterprise Data Hub版本中包含的組件。
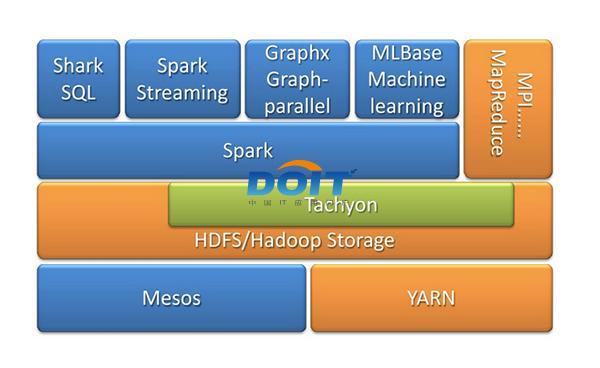
圖二:Spark On YARN
據悉,該產品采用了Spark 0.9.0,Spark獨立模式已經在Cloudera Enterprise Data Hub4.4.0中測試過。在不久的將來,Cloudera表示Enterprise 5.0和YARN中也將支持Spark。
【編輯推薦】
責任編輯:彭凡
來源:
存儲在線













