內存內計算技術幫助運營系統將運營智能化變為現實
譯文運營系統負責管理我們的財務、采購、設備以及其它各類日常事務。如果能在這些系統當中引入實時分析機制,那么用戶將能夠根據狀態變化獲取到實時響應結果,從而擁有立即可用且***針對性的反饋結論。這種分析技術使用方式被稱為運營智能化,而且市場對于這類方案的需求正快速增長且變得愈發迫切。
舉例來說,金融交易類應用程序必須能夠快速針對當前市場狀況的波動作出響應,這是因為市場數據流會貫穿并影響到整套交易體系。電子商務系統則必須以秒為單位檢查庫存變化情況,并據此對訂單可用性做出調整; 除此之外,這類系統還需要快速響應購物活動,從而帶來更具個性化特色的貨品推薦清單。智能化電網監控系統則需要對來自多個來源的數據進行遙測與持續分析,從而在預測結果之余針對電網體系中可能出現的意外變化做出響應。
在前面提到的各類實例當中,實時且快速變更的數據集必須能夠與活躍且瞬息萬變的即時操作結合在一起。以實時方式對當前數據做出響應的優勢——例如根據當前購物車中的已有內容為買家推薦更多可能需要的貨品——已經得到了廣泛認可,既令人信服又觸手可及。而將內存內計算與數據并行分析加以整合并運行在同一套商用服務器集群當中,則能夠支撐各業務系統以持續方式追蹤并分析實時數據、提取重要模式并生成足以指導系統行為的即時反饋信息。這項技術已經能夠在多種被統稱為內存內數據網格(簡稱IMDG)的軟件方案當中找到,其在過去十年當中的不斷演變切實幫助企業以更為高效且科學的方式管理著自己的運營系統。
內存內數據網格究竟是什么?
作為內存內數據網格,其***特征在于將數據保存在內存當中并將其分發至整個由商用服務器所構成的集群體系(也可以是運行在云環境下的多套虛擬服務器系統)。利用面向對象的數據存儲模式,內存內數據網格能夠提供專門用于讀取并更新數據對象的API,而且其延遲表現相當出色——通常低于1毫秒,具體情況取決于對象的實際大小。這樣一來,運營系統就能夠利用內存內數據網格對由系統狀態追蹤所生成的“實時”數據進行存儲、訪問以及快速更新,甚至能夠在存儲工作負載量不斷擴展的情況下始終維持良好而快速的訪問時間水平。
內存內數據網格采用的是“彈性”存儲機制,也就是說大家可以單純通過添加或者移除服務器設備來對存儲容量以及數據吞吐能力進行上調或者縮減。除此之外,這類技術方案所采用的內存內數據存儲方式還能帶來出色的可用性表現,從而為企業帶來可靠的持續可用水平。服務器單元即使出現故障并需要進行恢復——或者是企業需要向集群當中添加或者從中移隊部分服務器——整體運營都不至于遭受中斷。
也許最重要的是,內存內數據網格機制能夠充分發揮集群的計算性能優勢,從而以數據并行計算方式對所存儲的數據進行處理。由于數據與計算性能同處于一套整體環境之下,因此避免了數據移動這一老大難問題,這也是內存內數據網格能夠在***資源消耗前提下實現高速處理效果的秘訣(通常能夠在一秒鐘之內完成)。有鑒于此,內存內數據網格非常適合面向運營系統狀態的快速分析并立即提供反饋信息。
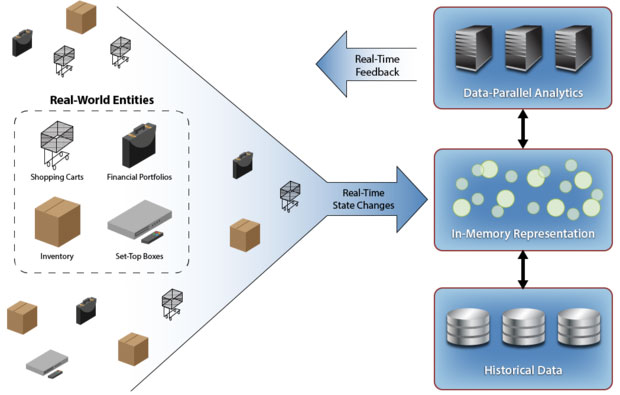
一套內存內數據網格能夠被用于構建多種真實世界中的系統模式——其中包括在線購物、股票交易、庫存管理以及電視節目觀看等等——同時能為運營系統提供實時反饋信息。
對運營系統進行建模以實現運營智能化
運營系統通常包含一整套規模龐大的動態實體群組,例如金融交易系統當中的股票組合、電子商務網站中的在線購物者瀏覽操作以及有線電視網絡當中來自觀眾的機頂盒控制行為等等。這些實體會創造出事件流,這些流信息必須與豐富的離線數據進行關聯(例如客戶的偏好內容或者歷史瀏覽內容),進而從中發現使用模式及消費趨勢。
如果這類分析工作能夠以實時方式完成,那么反饋結果將可以被交付至運營系統、進而實現功能強化以及執行效率提升。舉例來說,根據市場波動情況觸發對應的股票交易操作,為購物者提供各類相關貨品推薦,整合出***個性化的建議內容并根據觀看喜好與當前可選節目提醒有線電視觀眾選擇適合自己的促銷套餐。
為了實現實時分析機制,目前最常見的做法在于專注分析輸入數據流并在流內對數據作出響應。這類實例相當普遍,包括利用Apache Storm在金融服務以及信息流當中實現復雜事件處理——Apache Storm是一套并行平臺,最初的設計目的在于對Twitter數據流加以分析。
然而,專注于事件處理并不足以為真實世界中各類實體行為的建模工作提供一套完整的框架,因為除了事件流之外、歷史記錄與背景信息也必須被歸入考量范圍當中。利用內存內模式囊括各類由運營系統負責托管的實時世界實體,內存內數據網格就能將不同輸入事件關聯起來并利用離線信息對其進行補充,從而真正匯總出一套能夠用于指導實時分析工作的綜合性背景資料。這類分析機制所生成的輸出結果隨后可以被直接交付回系統本身,從而為企業運營帶來理想的增值效果。當然,此類結果也能夠幫助相關工作人員更好地對整套系統加以監控。
#p#
利用內存內數據網格實現運營智能化
內存內數據網格正是最值得大家采納的內存內處理模式,適用于各類運營系統中的活動實體以及對這些實體所帶來的輸入事件加以持續追蹤,同時利用相關歷史信息對其作出補充并整合出一套行為匯聚型并行分析方案。這種內存內實施機制能夠充分發揮內存內數據網格所固有的面向對象存儲模式優勢,從而將由各功能實體所產生的內存內數據進行高效匯總。
由于內存內數據網格既具備彈性又擁有高可用性,因此足以處理高可變性工作負載并運行在負責承載關鍵性任務的運營系統當中。內存內數據網格的并行數據計算引擎保證其能夠對模型當中的各類狀態變化作出快速分析,并將反饋結果立即提交給系統自身,同時又能持續對全部實體中所表現出的新興趨勢進行捕捉與整理。
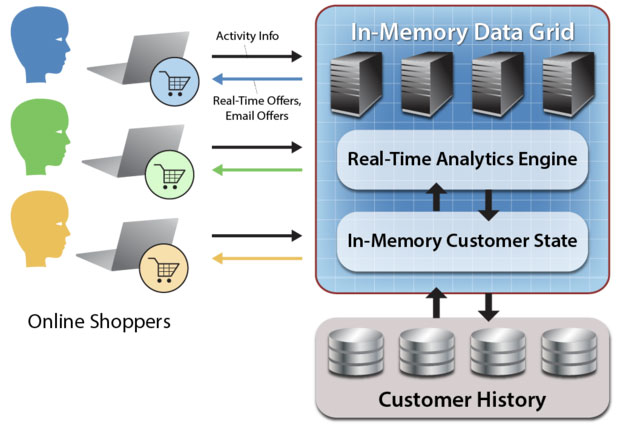
內存內數據網格技術的一類典型用例在于對在線購物者進行建模,從而根據其個人喜好提供個性化貨品推薦。
內存內數據網格的實際應用
現在我們不妨設想某高人氣在線購物網站希望對購物者的點擊流數據進行分析,從而為用戶提供更具個性化特色的貨品推薦。在這種情況下,內存內數據網格能夠為每一位購物者構建一套內存內模型,并根據該用戶的點擊流數據對模型進行持續更新。利用面向對象方案,內存內數據網格會根據基于內存的對象對每一位購物者加以體現,其中包含有按時間排序的點擊流事件動態收集信息以及個人喜好乃至歷史購物模式(這部分內容由次級存儲體系負責保存)。
這種面向對象的審視方式能夠更為輕松地將輸入事件關聯起來,并提供根據購物活動所總結得出的持續性并發數據分析結論,這兩類信息都能以實時方式生成、被匯總為個性化貨品推薦交付給各位獨立購物者且以全體購物者為基礎整理出新興消費趨勢(例如修改***的貨品或者預估客戶對所購買產品的滿意程度)。
內存內數據網格機制還具備一整套天然軟件架構,足以在有線電視機頂盒用戶打開電視機時追蹤所發生的事件——包括何時關機以及何時切換頻道。這套內存內模式能夠將每一臺機頂盒作為獨立單元進行輸入事件關聯,并根據既定規則將其中不具備指導意義的事件排除出去(例如觀眾隨機切換頻道的行為),而后利用節目信息對結果加以補充、從而了解與觀眾相關的各類信息(例如觀看歷史、個人特點以及節目喜好等)。
這種面向每一位觀眾的整合型數據集可以根據節目或者喜好情況匯總出更科學且貼合用戶喜好的推薦內容,而且分析流程也能夠以并發執行的方式涵蓋全部活躍觀眾。為了讓大家進一步理解內存內數據網格的強大能力,我們不妨共同了解這樣一個實例:最近進行的一次1000萬個有線電視機頂盒模擬分析研究中,我們發現內在內處理模式(所需處理的數據問題約為80GB,其中包括信息副本)每秒能夠對約25000個事件進行關聯與補充,而且這套由Amazon EC2負責托管、由12臺商用服務器共同構成的集群每十秒鐘就可以對全部1000萬個機頂盒進行一次并發分析。
總結陳詞
將實時智能化機制引入運營系統無疑給計算引擎提出了新的挑戰。這類引擎必須有能力獲取規模龐大的輸入事件,對數據進行關聯與補充,而后快速對其加以分析。由此產生的反饋結論則必須在時效性周期之內進行提交,從而保證分析結果能夠切實帶來業務優勢——具體時間通常在數毫秒乃至數秒之間。
作為一套專門面向運營系統設計并實施的彈性、基于內存的存儲及數據并發計算方案,內存內數據網格帶來的高效平臺能夠有效實現運營智能化這一發展目標。其能力足以管理面向一整套真實世界系統的內存內模型,追蹤其中所發生的變更,同時為模型實時分析提供必要的任務簡化效果以及所需的處理性能資源。運營智能化的實際效益目前可謂初露端倪,相信其中所蘊藏的將是規模龐大至難以想象的可觀商業機遇。