經驗分享:社會工程學數據庫搭建TIPS
最近一直在搞社工庫的搭建。網上這方面也有很多文章,但是很少涉及到細節,在此與大家分享一些個人心得。
測試環境
測試壞境:windows server 2012(x64,16G 內存) ,MySQL-5.0.90,php-5.2.14-Win32
準備工具:coreseek-4.1-win32,Phantom 牛的源碼
搭建過程
1,首先查看要索引表的字段,以便于在csft_mysql.conf 文件中配置
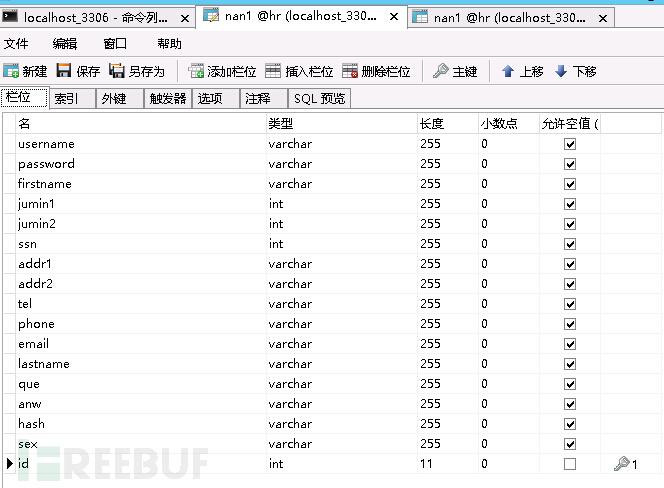
我們修改csft_myxql.conf 文件。(coreseek 3.2.14 不支持sql_query_string =)

注意Sql_query 中的字段必須和我們nan1 表中一致、
要支持cjk(中,日,韓簡寫)的查詢我們必須用它的專用charset_table
因此我們應當在index mysql 中加入charset_table(因數據量過長此處就省去,請查看我
的配置文件)
2,讓sphinx 支持實時索引,以便于我們后期解決某個問題。后來發現還是沒有解決成功
什么是實時索引就不再纂述了:)
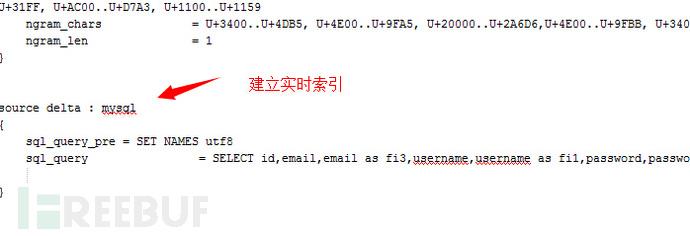
應當添加到index mysql 下方,具體請參照配置文件。修改好配置文件后請用UTF-8 without
BOM 格式保存以便程序讀取配置文件。
3,建立索引,并啟動
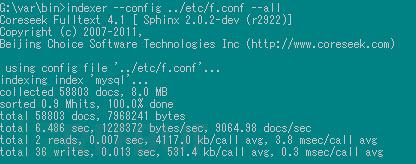
因為是測試數據量很小,因此程序啟動成功
若數據量超過1 億將顯示內存不足

將mem_limit = 1M 設置成1M 重新建立索引,若還是提示內存不足
將表數據分割,依賴實時索引動態插入數據(ps:如果大牛還有更好的辦法請與我聯系)
因測試我們用nan4 表做演示
此處我們有三種方法來分割表
Code:create table nan3 select distinct
firstname,lastname,email,username,password,hash,addr1,addr2,jumin1,jumin2,sex,s
sn from nan4;
create table nan3 Select
firstname,lastname,email,username,password,hash,addr1,addr2,jumin1,jumin2,sex,s
sn from nan4 group by
firstname,lastname,email,username,password,hash,addr1,addr2,jumin1,jumin2,sex,s
sn from nan4;
//兩句代碼效果都一樣去除username,password....sex 中內容相同的插入nan3 表,為有人
不理解我是意思,我截圖示之,本人表達能力有問題
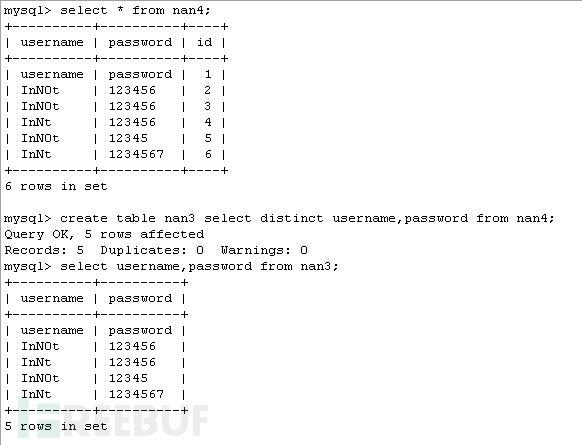
Group by 語句差不多;
昨晚喳喳同學告訴了我一個直接去除表中重復內容的語句我也貼上來,感謝他了(ps:和他研究了一晚上,沒辦法啊,人笨。)
Code:delete from temps where id in (select id from (select
id from temps as s where (select count(*) from temps as a
where a.username=s.username and a.password =s.password)>1
and id not in(select id from(select id,count(distinct username,
password) from temps as s where (select count(*) from test4
as a where a.username=s.username and a.password =s.password
)>1 group by username) as sss))as ttt)
注意:此處id:需為自增ID
分割表時不要用limit 參數與distinct 參數混用容易造成卡死,且得多次去重
create table tempss select * from nan3 limit 0,3;
create table temp select * from nan3 limit 3,5;
create table tempss select * from nan3 limit 0,3;create table temp select * from nan3 limit 3,5;
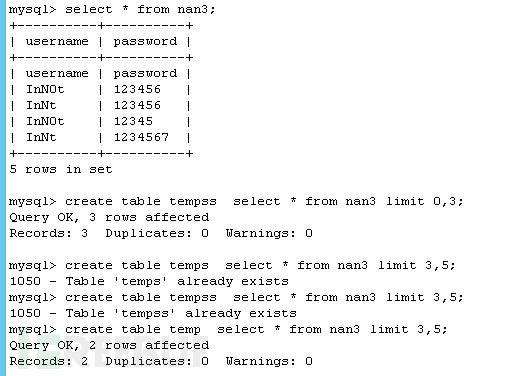
OK,現在我們已經分成兩個表,并手動給兩個表添加自增ID(temp id 最大值為4,temps id 最小值為5),我們將一個temp 表建立索引,并啟動
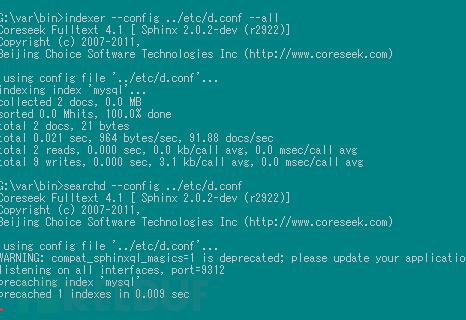
話說不知道是我人品的問題還是那啥,因此我們需要稍改一下search.php 的源碼

搜索結果
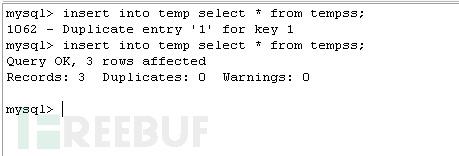
insert into temp select * from tempss;//將tempss 的數據插入到temp
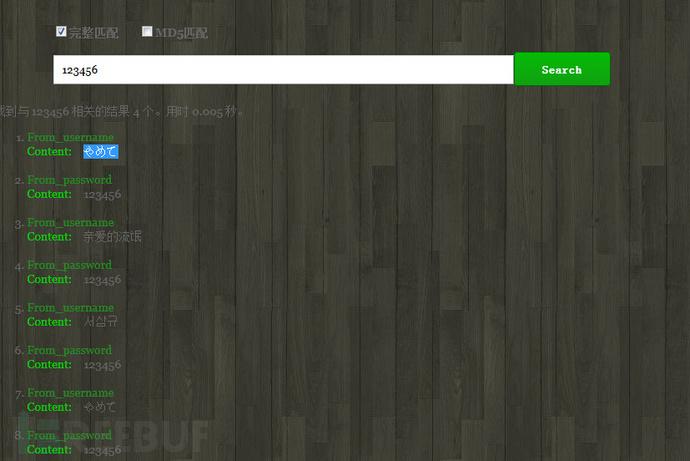
插入后搜索結果
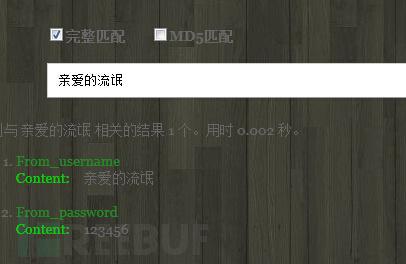
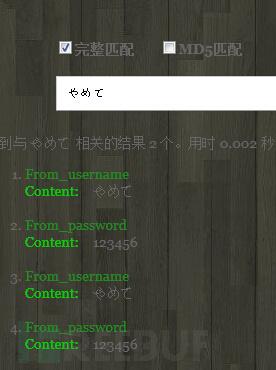
我對不起大家經過我的測試實時索引重啟后還是出現內存不足的情況,且只能修改我們索引
后的id 對應字段參數值。(留待大牛解答了)
補充TIPS
如果你恰好有韓國的或者小日本的數據庫,又恰好的先導入進去了(入庫沒啥好說的,數據庫編碼最好統一為utf8),編碼也設置成949
或者euckr
可能下面的語句能幫到您:
create table test4 select username ,password from test1 union
select username,password from test2;
//將test2 表與test1 表比較清除重復后插入test4 中;(ps:字段數據類型可
以不同)
ALTER TABLE test4 DEFAULT CHARACTER SET utf8 COLLATE utf8_gen
eral_ci;
//不解釋
alter table nan1 modify column username varchar(50); //修改username 的數據類型
alter table $table add $username varchar(50) null; //添加新字段
程序下載地址,提取碼4su4
參考文章
http://blog.csdn.net/rulev5/article/details/7572482
http://tesfans.org/using-sphinx-search-engine-with-chinese-japanese-and-korean-language-documents/
http://zone.wooyun.org/content/9377
歡迎志同道合的朋友與我交流:InN0t@outlook.com,作者:InN0t