細說HTTP之上篇
每天,都有數以億萬計的JPEG圖片、HTML頁面、文本文件、MPEG電影、WAV音頻文件、Java小程序和其他資源在因特網上游弋。HTTP可以從遍布全世界的Web服務器上將這些信息快速、便捷、可靠的搬移到人們桌面上的Web瀏覽器上去。
HTTP,全稱Hyper Text Transport Protocal,即超文本傳輸協議,定義了瀏覽器如何向服務器請求文檔以及服務器怎樣把文檔傳送給瀏覽器,它是萬維網能夠可靠的交換文件(包括文本,聲音,圖像等多種多媒體文件)的基礎。
起源
超文本傳輸協議的前身是Xanadu項目,超文本的概念是Ted Nelson在1960年代提出的。1989年,Tim Berners Lee在CERN擔任軟件咨詢師的時候,開發了一套程序,奠定了萬維網的基礎。1990年12月,超文本在CERN首次上線。1991年夏天,繼Telnet等協議之后,超文本轉移協議成為了互聯網諸多協議的一份子。
特點
1、支持客戶/服務器模式。支持基本認證 和安全認證。
2、 簡單快速:客戶向服務器請求服務時,只需傳送請求方法和路徑。請求方法常用的有GET、HEAD、POST。每種方法規定了客戶與服務器聯系的類型不同。由于HTTP協議簡單,使得HTTP服務器的程序規模小,因而通信速度很快。
3、靈活:HTTP允許傳輸任意類型的數據對象。正在傳輸的類型由Content-Type加以標記。
4、HTTP 0.9和1.0使用非持續連接:限制每次連接只處理一個請求,服務器處理完客戶的請求,并收到客戶的應答后,即斷開連接。采用這種方式可以節省傳輸時間。
HTTP 1.1使用持續連接:不必為每個web對象創建一個新的連接,一個連接可以傳送多個對象。
5、無狀態:HTTP協議是 無狀態協議 。無狀態是指協議對于事務處理沒有記憶能力。缺少狀態意味著如果后續處理需要前面的信息,則它必須重傳,這樣可能導致每次連接傳送的數據量增大。
Web客戶端和服務器交互過程和模型
客戶端/服務器(client/server)這個術語可追溯到上個千年(20世紀80年代),表示通過網絡連接起來的個人計算機。客戶端/服務器也可用于描述兩個計算機程序的關系--客戶程序和服務器程序。客戶向服務器請求某種服務(比如請求一個文件或數據庫訪問),服務器滿足請求并通過網絡將結果傳送給客戶端。雖然客戶端和服務器程序可存在于同一臺計算機中,但它們通常都運行在不同計算機上。一臺服務器處理多個客戶端請求也是很常見的。
最常見的Web客戶端就是瀏覽器了,一次請求/響應的模型如下圖所示:
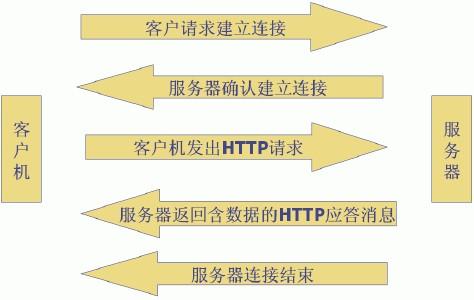
這里需要說明的一點是,每次訪問一個靜態資源,比如一個html文件,一個png圖片或者一個文本文檔都會向服務器發出一個HTTP請求,每個HTTP請求都會經歷上圖的請求/響應模型。比如我們點開http://www.taobao.com/(淘寶網),我們會往服務器發送成百上千個HTTP請求,收到來自客戶端的請求后,服務器會去尋找相應的資源,如果成功,就將對象,對象類型,對象長度以及其他信息放在HTTP響應中發回客戶端。那么問題來了,服務器怎么去尋找相應的資源,憑據是什么?
URL與資源
URL是瀏覽器尋找信息時所需要的資源位置。通過URL,人類和應用程序才能找到使用并共享因特網上大量的數據資源。URL是人們對HTTP和其他協議的常用訪問點:在瀏覽器中輸入一串URL,瀏覽器就會在幕后發送適當的協議報文來獲取人們所期望的資源。
URL的語法
大多數的URL方案的URL語法都建立在這個由9部分的通用格式上:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
幾乎沒有哪個URL中包含了所有這些組件。URL最重要的3個部分是方案(scheme)、主機(host)和路徑(path)。

目前常見的協議類型有很多種,常用的有http,https(更安全的http),mailto(郵件),ftp(文件傳輸),rtsp(音頻視頻),file,news,telnet等等。#p#
HTTP報文
HTTP報文是在HTTP應用程序之間發送的數據塊。這些數據塊以一些文本形式的元信息開頭,這些信息描述了報文的內容和含義,后面跟著可選的數據部分。
報文的組成
HTTP報文是簡單的格式化數據塊。每一條報文都包含一條來自客戶端的請求,或者來自服務器的響應。它們有三個部分組成:對報文進行描述的起始行(start line)、包含屬性的首部塊(header),以及可選的、包含數據的主體部分(body)。
- HTTP/1.0 200 OK //起始行
- Content-type:text/plain //首部
- Content-length:19 //首部
- Hi I'm a message! //主體
報文的語法
所有的HTTP報文可以分為兩類:請求報文(request message)和響應報文(response message)。請求報文會向服務器發送一個請求,響應報文會將結果返回個客戶端。
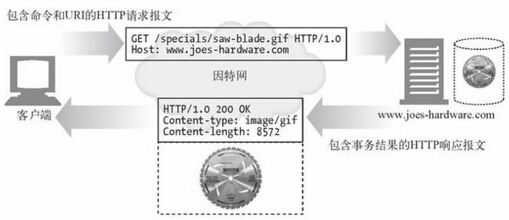
請求報文的格式:
- <method> <request-UTL> <version>
- <headers>
- <entity-body>
響應報文格式:
- <version> <status><reason-phrase>
- <header>
- <entity-body>
下面是對格式中各部分的簡要描述
1、方法(method) GET
客戶端希望服務器對資源執行的動作。是一個單獨的詞,比如GET、HEAD或POST。
2、請求的URL(request-URL)
命名了所有請求資源,或者URL路徑組件的完整URL。如果直接與服務器進行對話,只要URL的路徑組件是資源的絕對路徑,通常就不會有什么問題--服務器可以假定 義自己是URL的主機/端口。
3、版本(version) HTTP/1.1
報文所使用的HTTP版本,其格式如下:
HTTP/<major>.<minor>
其中主要版本號(major)和次要版本號(minor)都是整數。
4、狀態碼(status)
這三個數字描述了請求過程中所發生的情況。每個狀態碼的第一位數字都用于描述狀態的一般類別("成功"、"出錯"等)。
5、原因短語(reason-phrase)
數字狀態碼的可讀版本,包含行終止序列之前的所有文本。原因短語只是給人類看的,它不能說明什么。客戶端依然采用狀態碼來判斷請求/響應是否成功!
例如:HTTP/1.0 200 NOT OK 客戶端依然會當請求已成功處理。因為狀態碼是200。而原因短語只是說明而已,這對于自定義擴展狀態碼還是比較有用的。
6、首部(header)
可以有0個或多個首部,每個首部都包含一個名字,后面跟著一個冒號(:),然后是一個可選的空格,接著是一個值,最后是一個CRLF。首部是由一個 空行 (CRLF)結束 的,表示了首部列表的結束和實體主體的開始。
7、實體的主體部分(entity-body)
實體的主體部分包含一個由任意數據組成的數據塊。并不是所有的報文都包含實體的主體部分。如GET請求就不包含實體。