Spark成為大數據分析領域新核心的五個理由
譯文在過去幾年當中,隨著Hadoop逐步成為大數據處理領域的主導性解決思路,原本存在的諸多爭議也開始塵埃落定。首先,Hadoop分布式文件系統是處理大數據的正確存儲平臺。其次,YARN是大數據環境下理想的資源分配與管理框架選項。第三也是最重要的一點,沒有哪套單一處理框架能夠解決所有問題。雖然MapReduce確實是一項了不起的技術成果,但仍然不足以成為百試百靈的特效藥。
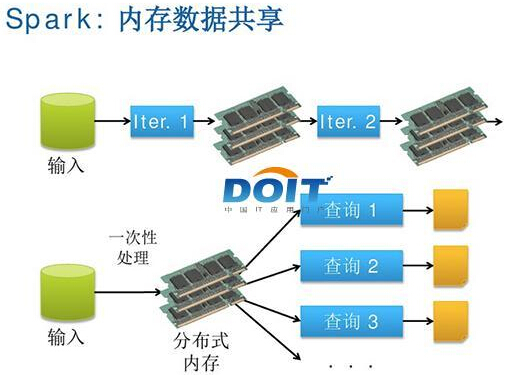
依賴于Hadoop的企業需要借助一系列分析型基礎設施與流程以找到與各類關鍵性問題相關的結論與解答。企業客戶需要數據準備、描述性分析、搜索、預測性分析以及機器學習與圖形處理等更為先進的功能。與此同時,企業還需要一套能夠滿足其實際需求的工具集,允許他們充分運用目前已經具備的各類技能及其它資源。就目前而言,并沒有哪種標準化單一處理框架足以提供這樣的效果。從這個角度出發,Spark的優勢恰好得到了完美體現。
盡管Spark還僅僅是個相對年輕的數據項目,但其能夠滿足前面提到的全部需求,甚至可以做得更多。在今天的文章中,我們將列舉五大理由,證明為什么由Spark領銜的時代已經來臨。
1. Spark讓高級分析由理想變為現實
盡管多數大型創新型企業正在努力拓展其高級分析能力,但在最近于紐約召開的一次大數據分析會議上,只有20%的與會者表示目前正在企業內部部署高級分析解決方案。另外80%與會者反映其仍然只具備簡單的數據準備與基本分析能力。在這些企業中,只有極少數數據科學家開始將大量時間用于實現并管理描述性分析機制。
Spark項目提供的框架能夠讓高級分析的開箱即用目標成為現實。這套框架當中包含眾多工具,例如查詢加速、機器學習庫、圖形處理引擎以及流分析引擎等等。對于企業而言,即使擁有極為杰出的數據科學家人才(當然這一前提同樣很難實現),他們也幾乎不可能通過MapReduce實現上述分析目標。除此之外,Spark還提供易于使用且速度驚人的預置庫。在此基礎之上,數據科學家們將被解放出來,從而將主要精力集中在數據準備及質量控制之外的、更為關鍵的事務身上。有了Spark的協助,他們甚至能夠確保對分析結果做出正確的解釋。
2. Spark讓一切更為簡便
長久以來,Hadoop面臨的最大難題就是使用難度過高,企業甚至很難找到有能力打理Hadoop的人才。雖然隨著新版本的不斷出爐,如今Hadoop在便捷性與功能水平方面已經得到了長足進步,但針對難度的詬病之聲依然不絕于耳。相較于強制要求用戶了解一系列高復雜性知識背景,例如Java與MapReduce編程模式,Spark項目則在設計思路上保證了每一位了解數據庫及一定程度腳本技能(使用Python或者Scala語言)的用戶都能夠輕松上手。在這種情況下,企業能夠更順暢地找到有能力理解其數據以及相關處理工具的招聘對象。此外,供應商還能夠快速為其開發出分析解決方案,并在短時間內將創新型成果交付至客戶手中。
3. Spark提供多種語言選項
在討論這一話題時,我們不禁要問:如果SQL事實上并不存在,那么我們是否會為了應對大數據分析挑戰而發明SQL這樣一種語言?答案恐怕是否定的——至少不會僅僅只發明SQL。我們當然希望能夠根據具體問題的不同而擁有更多更為靈活的選項,通過多種角度實現數據整理與檢索,并以更為高效的方式將數據移動到分析框架當中。Spark就拋開了一切以SQL為中心的僵化思路,將通往數據寶庫的大門向最快、最精致的分析手段敞開,這種不畏數據與業務挑戰的解決思路確實值得贊賞。
4. Spark加快結果整理速度
隨著業務發展步伐的不斷加快,企業對于實時分析結果的需要也變得愈發迫切。Spark項目提供的并發內存內處理機制能夠帶來數倍于其它采用磁盤訪問方式的解決方案的結果交付速度。傳統方案帶來的高延遲水平會嚴重拖慢增量分析及業務流程的處理速度,并使以此為基礎的運營活動難于開展。隨著更多供應商開始利用Spark構建應用程序,分析任務流程的執行效率將得到極大提高。分析結果的快速交付意味著分析人士能夠反復驗證自己的論斷,給出更為精確且完整的答案。總而言之,Spark項目讓分析師們將精力集中在核心工作上:更快更好地為難題找出解答。
5. Spark對于Hadoop供應商選擇不設硬性要求
目前各大Hadoop發行版本都能夠支持Spark,其理由也非常充分。Spark是一套中立性解決方案,即不會將用戶綁定到任何一家供應商身上。由于Spark屬于開源項目,因此企業客戶能夠分析地構建Spark分析基礎設施而不必擔心其是否會受到某些Hadoop供應商在特定發展思路方面的挾持。如果客戶決定轉移平臺,其分析數據也能夠順利實現遷移。
Spark項目蘊含著巨大的能量,而且已經在短時間內經受住了考驗、證明其有能力密切匹配大數據分析業務的實際要求。目前我們所迎來的還僅僅是“Spark時代”的開端。隨著企業越來越多地發揮Spark項目中的潛能,我們將逐步見證Spark在任意大數據分析環境下鞏固其核心技術地位,圍繞其建立起的生態系統也將繼續茁壯成長。如果企業客戶希望認真考量高級實時分析技術的可行性,那么將Spark引入自身大數據集幾乎已經成為一種必然。
原文標題:5 reasons to turn to Spark for big data analytics
核子可樂譯