印度云端通信公司:我們是如何設計存儲4億個電話號碼的
如果你居住在印度,當不希望接受任何電話推銷員的騷擾時,你可以在全國客戶偏好登記冊(National Customer Preference Register,NCPR) 【1 】 中進行注冊。政府維護了這個由用戶注冊的電話號碼組成的數據庫。現在,差不多有4億個注冊號碼。所有注冊的電話推銷員必須及時更新數據,以保證他們在進行推銷時會參考這個偏好設置進行工作。
這些數據由一捆ZIP文件(當下是40個)提供,每個ZIP文件包含一個10M的CSV文件。這篇文章將會講述這2.4GB壓縮后的數據如何基于一些簡單的方式以一種可搜索的格式適配2GB的內存。
數據
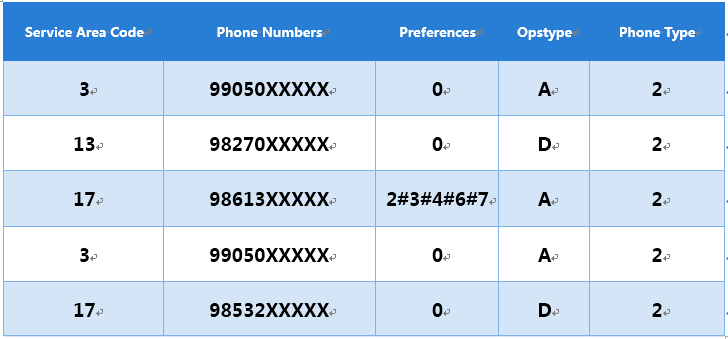
下面是CSV文件一瞥(出于隱私原因,有些數據進行了混淆)
關于存儲在SQL引擎中的一些說明
在內存為4GB的 Linode 機房的機器上, PostgreSQL數據表(使用COPY)加載數據約需要10分鐘:
real 10m0.159s
user 2m42.243s
sys 0m26.363s
添加一個主鍵大約耗時1.5到2個小時:
real 118m21.637s
user 0m0.043s
sys 0m0.020s
并使用32GB的硬盤空間:
![]()
觀察CSV數據
分析了數據之后,我們可以看到:
* 將近400M行數據
* 電話號碼全部(phone numbers)是10位
* 服務區域碼(service area code)是1-23之間的自然數
* 偏好(preference)依靠`#`來界定,可能是`0`或者是{1,2,3,4,5,7}的組合
* Ops類型(Opstype)用A表示啟用,用D表示未啟用
* 電話號碼類型(Phone Type)是{1,2,3}中的一個
這意味著一行數據可以用2個字節表示:
***個字節:1位存在標志位(existence flag),5位服務區域碼,2位電話號碼類型。
第二個字節:7位偏好,1位Ops類型。
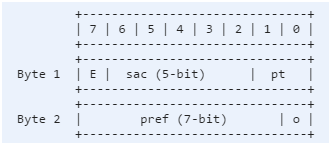
數據可以通過2*400MB來表示。存在標志位將會在下面的部分討論。
使之可搜索
每個條目都會按照電話號碼進行頻繁的搜索,而目前我們并沒有將數據與電話號碼進行匹配。我們需要添加字節來存儲電話號碼。不幸的是,10個數字并不能放入32位中(10 digits won't fit in 32 bits),使用5*400MB來存儲數字并不是一個樂觀的情況,而且根本沒辦法進行搜索。如果數據按順序排列(arranged in a sequence),那么索引為 (2*number) 和 (2*number+1)的內存位置便能給出所需的兩個字節。空行可以用***個字節中的存在標志表示。這意味著我們需要20GB的內存(2字節*10B的數字)。我們能進一步壓縮嗎?該數組看起來很稀疏(只有40%被占用)。
我們的解決方案是:使用兩種格式類型。
#p#
更進一步
我們還發現對于大多數移動手機號碼的數組是密集的 【 2 】 。所以,如果10個數字分成兩部分——4位的前綴(我們可以稱之為頭部)和6位的數字偏移量(尾部)——這樣一來,固定的4位前綴的所有可能值按順序排列時,它們都可以被放入2MB的空間里了。(每個尾部2字節)。現在,搜索變得簡單了,因為我們按照尾部進行偏移量計算,直接訪問數組即可。
這個稀疏的數列存儲在5字節的序列中,3個字節表示尾部,2個字節表示數據。尾部按照升序排列,所以搜索變的簡單了(二分搜索)。
對于持久化存儲,具有相同前綴的數字存儲在一個文件中,該文件的***個字節是類型的指示框。這些共需1.8GB的空間,這些數據可以存儲在內存中,通過webserver進行發布。
加工處理
使用快速Python腳本來轉換CSV數據為我們需要的格式是十分耗時的。分析表明,大部分時間花費在迭代處理2M固定頭部數據時。我們嘗試使用xrange進行優化,但是5小時對于處理整個數據,尤其是PostgreSQL處理僅需要2小時,實在太多了。我們希望能有些快速響應,更符合心理預期。相同的程序選擇Rust來實現,處理整個數據僅用20-30分鐘。
real 21m4.284s
user 20m58.427s
sys 1m37.607s
查找計時
為了測量該解決方案的速度,我們隨機生成了相同序列(固定的頭部)的電話號碼。結果如下圖所示。我們選取“9818”和“9000” 開頭的號碼去分別計算查找密集框(我們稱之為類型0)和稀疏框(類型1)的時間。對于SQL解決方案,頭部的密集程度并不影響。注意,在本次測量中,盡管我們為了公平起見,計時時包含了磁盤的讀寫,但是在我們的解決方案中,數據一旦被加載或放入內存中,不再需要磁盤訪問,之后由于數據存儲格式的優點,這個進程被加快。
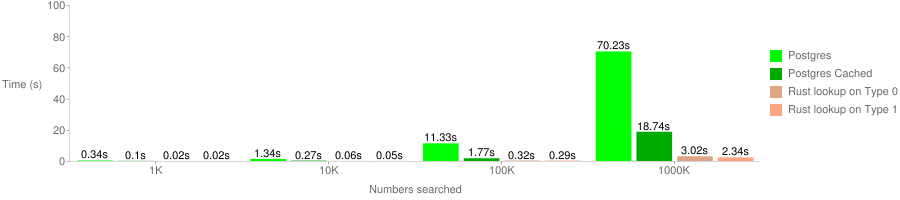
所有的測試都是在4GB的Linode機房機器上跑的,機器配置如下:
SSD, 4GB RAM, 4 virtual CPU cores, CPU Model: Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz
API和開源
在SparkTG,我們尊重客戶的偏好設置。盡管我們的客戶大部分都是與注冊的客戶交流,但我們還是保證他們最終不會撥出一個無關的電話。我們已經將該項目 【3】 開源,并且提供API 【4】 來查找號碼NCPR狀態,使得電話推銷找不到方式撥打注冊用戶的電話。
原文鏈接:http://www.jointforce.com/jfperiodical/article/show/925?utm_source=tuicool