













【圖文教程】打造高性能、高可靠的塊存儲系統
塊存儲系統
分布式存儲有出色的性能,可以扛很多故障,能夠輕松擴展,所以我們使用Ceph構建了高性能、高可靠的塊存儲系統,并使用它支撐公有云和托管云的云主機、云硬盤服務。
由于使用分布式塊存儲系統,避免了復制鏡像的過程,所以云主機的創建時間可以縮短到10秒以內,而且云主機還能快速熱遷移,方便了運維人員對物理服務器上硬件和軟件的維護。
用戶對于塊存儲系統最直觀的感受來源于云硬盤服務,現在我們的云硬盤的特點是:
- 每個云硬盤***支持 6000 IOPS和170 MB/s的吞吐率,95%的4K隨機寫操作的延遲小于2ms 。
- 所有數據都是三副本,強一致性,持久性高達10個9。
- 創建、刪除、掛載、卸載都是秒級操作。
- 實時快照。
- 提供兩種云硬盤類型,性能型和容量型。
軟硬件配置
經過多輪的選型和測試,并踩過無數的坑之后,我們選擇了合適我們的軟件和硬件。
軟件
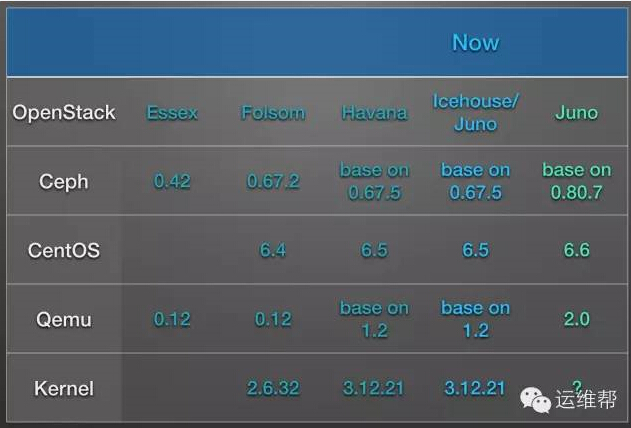
硬件
- 從SATA磁盤到SSD,為了提高IOPS和降低Latency。
- 從消費級SSD到企業級SSD,為了提高可靠性。
- 從RAID卡到HBA卡,為了提高IOPS和降低Latency。
最小部署架構
隨著軟硬件的升級,需求的調整, 我們的部署架構也不斷在演進,力求在成本、性能、可靠性上達到***平衡點。

最小規模部署中有12個節點,每個節點上有3塊SSD。節點上有2個萬兆口和1個千兆口,虛擬機網絡和存儲網絡使用萬兆口,管理網絡使用千兆口。每個集群中都有3個Ceph Monitor節點。
輕松擴展
云計算的好處是極強的擴展性,作為云計算的底層架構,也需要有快速的Scale-out能力。在塊存儲系統的部署架構中,可以以12臺節點為單位進行擴展。

改造OpenStack
原生的OpenStack并不支持統一存儲,云主機服務Nova、鏡像服務Glance、云硬盤服務Cinder的后端存儲各不相同,造成了嚴重的內耗。我們把這三大服務的后端統一起來,進行高效管理,解決了虛擬機創建時間長和鏡像風暴等問題,還能讓虛擬機隨便漂移。
原生的OpenStack
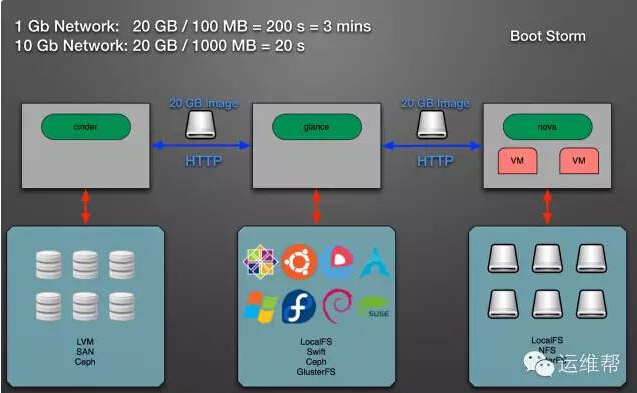
改造后的OpenStack

使用原生的OpenStack創建虛擬機需要1~3分鐘,而使用改造后的OpenStack僅需要不到10秒鐘時間。這是因為nova-compute不再需要通過HTTP下載整個鏡像,虛擬機可以通過直接讀取Ceph中的鏡像數據進行啟動。
我們還增加兩個OpenStack沒有的功能: QoS 和 共享云硬盤。云計算的另外一個好處是租戶資源隔離,所以必備QoS。共享云硬盤可以掛載給多臺云主機,適用于數據處理的場景。
我們還使用了OpenStack的multi-backend功能,支持多種云硬盤類型,現在我們的云硬盤類型有性能型、容量型,可以滿足數據庫和大文件應用。
#p#
高性能
存儲系統主要的性能指標是IOPS和Latency。我們對于IOPS的優化已經達到了硬件的瓶頸,除非更換更快的固態硬盤或者閃存卡,或者是改變整個架構。我們對于Latency的優化也快接近完成,可以達到企業級存儲的水平。
復雜的I/O棧
整個塊存儲系統有著長長的I/O棧,每個I/O請求要穿過很多線程和隊列。
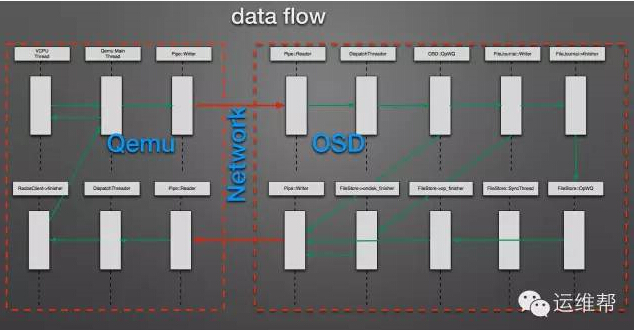
優化操作系統
優化操作系統的參數可以充分利用硬件的性能。
CPU
- 關閉CPU節能模式
- 使用Cgroup綁定Ceph OSD進程到固定的CPU Cores上
Memory
- 關閉NUMA
- 設置vm.swappiness=0
Block
- 設置SSD的調度算法為deadline
FileSystem
- 設置掛載參數”noatime nobarrier”
優化Qemu
Qemu作為塊存儲系統的直接消費者,也有很多值得優化的地方。
- Throttle: 平滑的I/O QoS算法
- RBD: 支持discard和flush
- Burst: 支持突發請求
- Virt-scsi: 支持多隊列
優化Ceph
我們對于Ceph的優化是重頭戲,有很多問題也是時間長、規模上去之后才暴露出來的。









#p#
高可靠性
存儲需要高可靠性,保證數據可用并且數據不丟失。因為我們的架構中沒有使用UPS和NVRAM,所以寫請求的數據都是落到三塊硬盤之后才返回,這樣***限度地保證了用戶的數據安全。
如何計算持久性
持久性是數據丟失的概率,可以用于度量一個存儲系統的可靠性,俗稱 “多少個9”。數據的放置(DataPlacement)決定了數據持久性,而Ceph的CRUSH MAP又決定了數據的放置,因此CRUSH MAP的設置決定了數據持久性。但是,即時我們知道需要修改CRUSH MAP的設置,但是我們應該怎么修改CRUSH MAP的設置呢,我們該如何計算數據持久性呢?
我們需要一個計算模型和計算公式,通過以下資料,我們可以構建一個計算模型和計算公式。
- Reliability model
- 《CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data》
- 《Copysets: Reducing the Frequency of Data Loss in Cloud Storage》
- 《Ceph的CRUSH數據分布算法介紹》
最終的計算公式是: P = func(N, R, S, AFR)
- P: 丟失所有副本的概率
- N: 整個Ceph Pool中OSD的數量
- R: 副本數
- S: 在一個Bucket中OSD的個數
- AFR: 磁盤的年平均故障率
這個計算模型是怎么樣得到計算公式的呢?下面是4個步驟。
- 先計算硬盤發生故障的概率。
- 定義哪種情況下丟失數據不能恢復。
- 計算任意R個OSD發生故障的概率。
- 計算Ceph丟失PG的概率。
硬盤發生故障的概率是符合泊松分布的:
- fit = failures in time = 1/MTTF ~= 1/MTBF = AFR/(24*365)
- 事件概率 Pn(λ,t) = (λt)n e-λt / n!
Ceph的每個PG是有R份副本的,存放在R個OSD上,當存有這個PG的R個OSD都發生故障時,數據是不可訪問的,當這R個OSD都損壞時,數據是不可恢復的。
計算一年內任意R個OSD發生相關故障概率的方法是:
- 計算一年內有OSD發生故障的概率。
- 在Recovery時間內,(R-1)個OSD發生故障的概率。
- 以上概率相乘,就是一年內任意R個OSD發生相關故障概率,假設是 Pr。
- N個OSD中,任意R個OSD的組合數是C(R, N)。
因為這任意R個OSD不一定存有同一個PG的副本,所以這任意R個OSD發生故障并不會導致數據不可恢復,也就是不一定會導致數據丟失。
假設每個PG對應一組OSD(有R個OSD, 稱之為Copy Set),有可能多個PG對應同一組OSD。假設有M個不同的Copy Set, M是一個非常重要的數字。
我們再來對Copy Set進行精確的定義:Copy Set上至少有一個PG的所有副本,當這個Copy Set損壞時,這個PG的所有副本也會丟失,這個PG上的所有數據就不可恢復。所以Ceph丟失數據的事件就是Ceph丟失PG, Ceph丟失PG就是有一個Copy Set發生損壞,一個Copy Set丟失的概率就是 P = Pr * M / C(R, N) 。
持久性公式就是個量化工具,它可以指明努力的方向。我們先小試牛刀,算一下默認情況下的持久性是多少?
假設我們有3個機架,每個機架上有8臺節點,每個幾點上有3塊硬盤,每個硬盤做一個OSD,則一共有72個OSD。
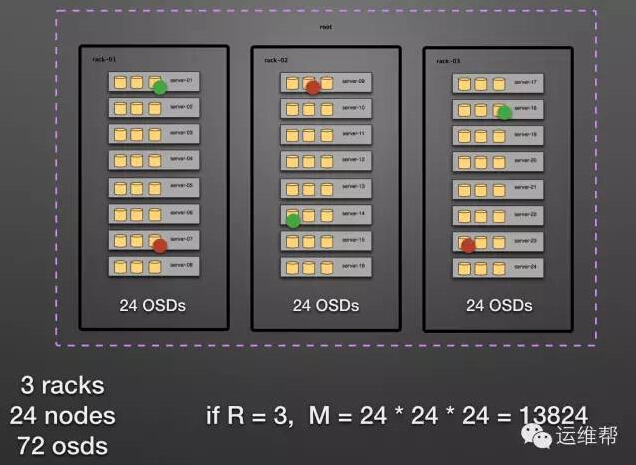
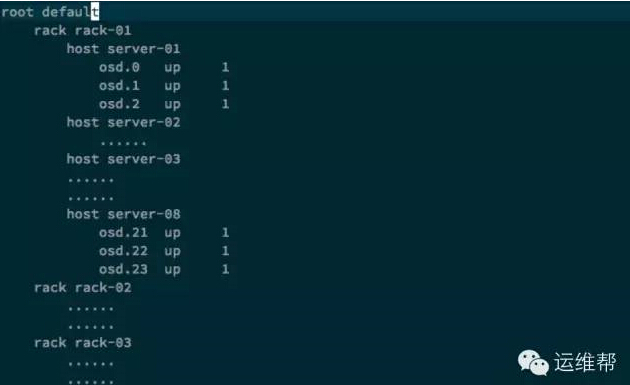
默認的crush map設置如下所示
通過持久性公式,我們得到下面的數據。
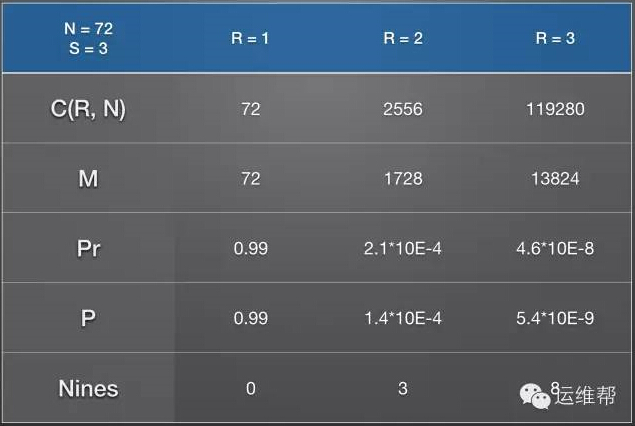
默認情況下,持久性有8個9,已經比一般的RAID5、RAID10要高,和RAID6差不多,但是還不能滿足公有云的要求,因為公有云的規模很大,故障事件的數學期望也會很大,這就逼著我們盡量提高持久性。
提高持久性的方法有很多,比如增加副本數,使用Erase Code等。不過這些方法都有弊端,增加副本數勢必會擴大成本;使用Erase Code會導致Latency提高,不適合于塊存儲服務。在成本和Latency的制約下,還有什么辦法可以提高持久性呢?
前面我們已經得到一個量化公式 P = Pr * M / C(R, N), 我們從量化公式入手,去提高持久性(也就是降低P)。要想降低P, 就得降低Pr、M,或者是提高C(R, N)。因為C(R, N)已經確定,我們只能降低Pr和M。
降低恢復時間
從Pr的定義可以知道Pr與恢復時間有關,恢復時間越短,Pr的值越低。那么恢復時間跟什么有關系呢?
我們需要增加更多的OSD用于數據恢復,以便減少恢復時間。目前host bucket不能增加更多的OSD,這是因為主機的網絡帶寬限制和硬盤插槽限制。解決辦法是從CRUSH MAP入手,增加一種虛擬的Bucket: osd-domain, 不再使用host bucket。


通過使用osd-domain bucket,我們把持久性提高了10倍,現在持久性有9個9。
減少Coepy Set個數
如何減少Copy Set的個數呢?Copy Sets是和PG的映射有關的,我們從CRUSH MAP的規則和條件入手,減少Copy Set的個數。解決辦法增加虛擬的Bucket: replica-domain, 不再使用rack bucket。每個PG必須在一個replica-domain上,PG不能跨replica-domain,這樣可以顯著減少Copy Set的個數。

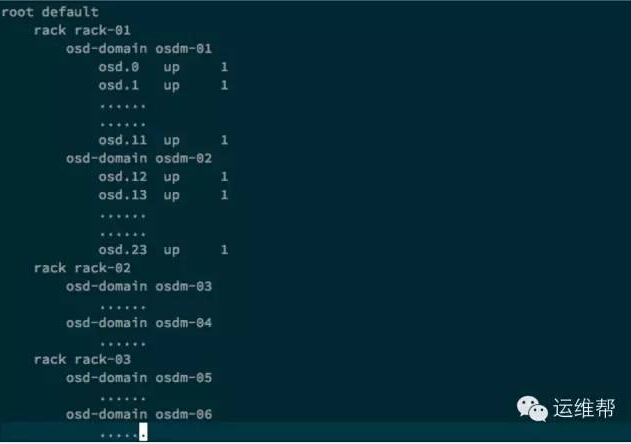
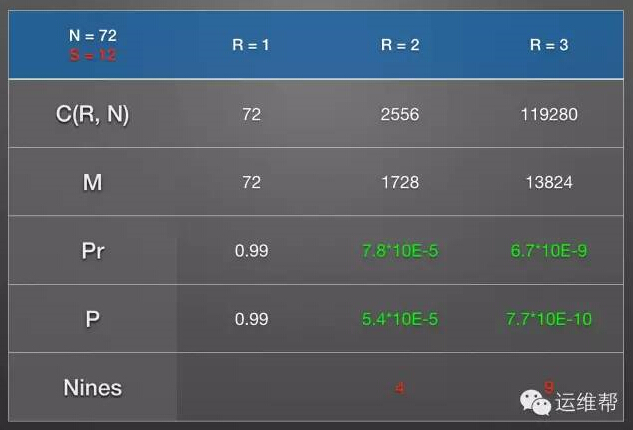
通過使用replica-domain,現在的持久性有10個9,持久性比默認的crush map設置提高了100倍。
#p#
自動化運維
Ceph的運維比較費心,稍有差池,整個云平臺都會受到影響,因此我們覺得運維的目標是可用性:
減少不必要的數據遷移,進而減少slow requests,保證SLA。
部署
我們整個云平臺都是使用Puppet部署的,因此我們使用了Puppet去部署Ceph。一般Ceph的安裝是分階段的:
- 安裝好Ceph Monitor集群。
- 格式化Disk,使用文件系統的UUID去注冊OSD, 得到OSD ID。
- 根據OSD ID去創建數據目錄,掛載Disk到數據目錄上。
- 初始化CRUSH MAP。
Puppet只需要完成前三步,第四步一般根據具體情況用腳本去執行。因為OSD ID是在執行過程中得到的,而Puppet是編譯后執行,這是一個悲傷的故事,所以puppet-ceph模塊必須設計成retry的。
相比eNovance和Stackforge的puppet-ceph模塊,我們的puppet-ceph模塊的優點是:
- 更短的部署時間
- 支持Ceph所有的參數
- 支持多種硬盤類型
- 使用WWN-ID替代盤符。
維護
升級Ceph的過程很簡單,三條命令就可以搞定:
- ceph osd set noout #避免在異常情況下不可控
- ceph osd down x #提前mark down, 減少slow request
- service ceph restart osd.x
更換硬件或者升級內核時需要對機器進行重啟,步驟也很簡單:
- 把這臺機器上的虛擬機遷移到其他機器上
- ceph osd set noout
- ceph osd down x #把這個機器上的OSD都設置為down狀態
- service ceph stop osd.x
- 重啟機器
擴展集群的時候需要非常小心,因為它會觸發數據遷移:
- 設置crush map
- 設置recovery options
- 在凌晨12點觸發數據遷移
- 觀察數據遷移的速度,觀察每個機器上網口的帶寬,避免跑滿
- 觀察slow requests的數量
你總會碰到硬盤損壞的時候,替換硬盤時需要非常小心,你要小心的設置crush map,你要保證要替換硬盤過程中replica-domain的weight的值是不變的,這樣才能保證不必須要的數據遷移。
監控
Ceph自家的Calamari長得不錯,但是不夠實用,而且它的部署、打包還不完善,在CentOS上還有一些BUG,我們只能繼續使用原有的工具。
- 收集:使用diamond,增加新的colloctor,用于收集更詳細的數據。
- 保存:使用graphite,設置好采集精度和保存精度。
- 展示:使用grafana,挑了十幾個工具,發現還是grafana好看好用。
- 報警:zabbix agent && ceph health
我們根據Ceph軟件架構對每個OSD分成了很多個throttle層,下面是throttle模型:

有了throttle model,我們可以對每個throttle進行監控,我們在diamond上增加了新的collector用于對這些throttle進行監控,并重新定義了metric name。

***,我們可以得到每個OSD每層throttle的監控數據。但平時只會關注IOPS、吞吐率、OSD Journal延遲、讀請求延遲、容量使用率等。
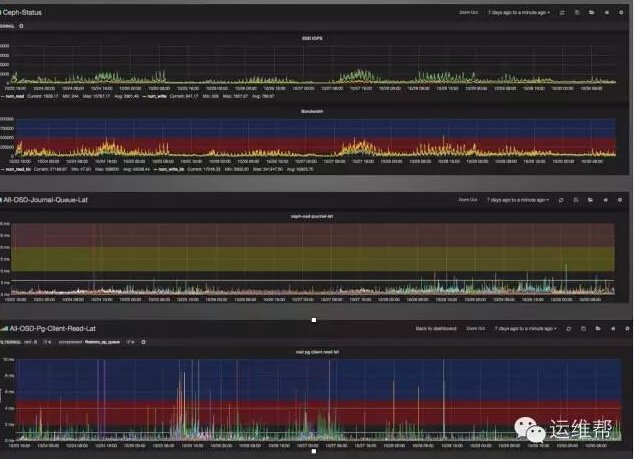
事故
在云平臺上線已經快一年了,我們遇到的大小事故有:
- SSD GC問題,會導致讀寫請求的Latency非常大,飆到幾百毫秒。
- 網絡故障,會導致Monitor把OSD設置為down狀態。
- Ceph Bug, 會導致OSD進程直接崩掉。
- XFS Bug, 會導致集群所有OSD進程直接崩掉。
- SSD 損壞。
- Ceph PG inconsistent。
- Ceph數據恢復時把網絡帶寬跑滿。
總體來說,Ceph是非常穩定和可靠的。
【本文來源:運維幫微信號】














