













IT運維分析與海量日志搜索需要注意什么
日志易創始人兼CEO陳軍老師12月16日在【DBA+社群】中間件用戶組進行了一次主題為“IT運維分析與海量日志搜索 ”的線上分享。
目錄:
◆IT 運維分析(IT Operation Analytics)
◆日志的應用場景
◆過去及現在的做法
◆日志搜索引擎
◆日志易產品介紹
一、IT 運維分析
1、IT 運維分析
1.1 從 IT Operation Management (ITOM) 到 IT Operation Analytics (ITOA)
IT運維分析,即IT Operation Analytics,簡稱ITOA,是個新名詞。以前IT運維是ITOM,IT Operation Management ,IT 運維管理。這兩年大數據技術開始普及,把大數據技術應用于IT運維,通過數據分析提升IT運維效率與水平,就是ITOA。
1.2 大數據技術應用于IT運維,通過數據分析提升IT運維
ITOA主要用于:
◆可用性監控
◆應用性能監控
◆故障根源分析
◆安全審計
1.3 Gartner估計,到2017年15%的大企業會積極使用ITOA;而在2014年這一數字只有5%。
2、ITOA的數據來源有以下四個方面:
1.1 機器數據(Machine Data):是IT系統自己產生的數據,包括客戶端、服務器、網絡設備、安全設備、應用程序、傳感器產生的日志,及 SNMP、WMI 等時間序列事件數據,這些數據都帶有時間戳。機器數據無所不在,反映了IT系統內在的真實狀況,但不同系統產生的機器數據的質量、可用性、完整性可能差別較大。
1.2 通信數據(Wire Data):是系統之間2~7層網絡通信協議的數據,可通過網絡端口鏡像流量,進行深度包檢測 DPI(Deep Packet Inspection)、包頭取樣 Netflow 等技術分析。一個10Gbps端口一天產生的數據可達100TB,包含的信息非常多,但一些性能、安全、業務分析的數據未必通過網絡傳輸,一些事件的發生也未被觸發網絡通信,從而無法獲得。
1.3 代理數據(Agent Data):是在 .NET、PHP、Java 字節碼里插入代理程序,從字節碼里統計函數調用、堆棧使用等信息,從而進行代碼級別的監控。但要求改變代碼并且會增加程序執行的開銷,降低性能,而且修改了用戶的程序也會帶來安全和可靠性的風險。
1.4 探針數據(Probe Data),又叫合成數據(Synthetic Data):是模擬用戶請求,對系統進行檢測獲得的數據,如 ICMP ping、HTTP GET等,能夠從不同地點模擬客戶端發起,進行包括網絡和服務器的端到端全路徑檢測,及時發現問題。但這種檢測并不能發現系統為什么性能下降或者出錯,而且這種檢測是基于取樣,并不是真實用戶度量(Real User Measurement)。
擁有大量客戶端的公司,如BAT,會直接在客戶端度量系統性能,做Real User Measurement,通常不需要模擬用戶檢測。
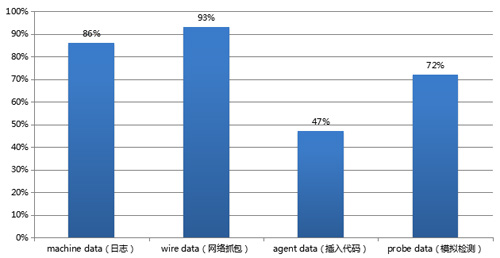
3、ITOA 四種數據來源使用占比
美國某ITOA公司的用戶調研發現,使用這四種不同數據來源的比例為:Machine Data 86%, Wire Data 93%, Agent Data 47%, Probe Data 72%。這四種數據來源各有利弊,結合在一起使用,效果最好。
4、日志:時間序列機器數據
通常結合日志與網絡抓包,能夠覆蓋大部分IT運維分析的需求。日志因為帶有時間戳,并由機器產生,也被稱為時間序列機器數據。
它包含了IT系統信息、用戶信息、業務信息。
日志反映的是事實數據:LinkedIn(領英)是非常著名的職業社交應用,非常重視用戶數據分析,也非常重視日志。
它的一個工程師寫了篇很有名的文章:
◆“The Log: What every software engineer should know about real-time data's unifying abstraction”, Jay Kreps, LinkedIn engineer
附:中文翻譯:深度解析LinkedIn大數據平臺
LinkedIn的用戶數據挖掘基于日志,公司內部有專門的部門處理所有的日志,各模塊的日志都被采集,傳送到這個部門。
著名的開源消息隊列軟件Kafka就是LinkedIn開發,用來傳輸日志的。
以Apache日志為例,包含了非常豐富的信息:
- 180.150.189.243 - - [15/Apr/2015:00:27:19 +0800] “POST /report HTTP/1.1” 200 21 “https://rizhiyi.com/search/” “Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0” “10.10.33.174” 0.005 0.001
里面包含的字段:
- Client IP: 180.150.189.243
- Timestamp: 15/Apr/2015:00:27:19 +0800
- Method: POST
- URI: /report
- Version: HTTP/1.1
- Status: 200
- Bytes: 21
- Referrer: https://rizhiyi.com/search/
- User Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0
- X-Forward: 10.10.33.174
- Request_time: 0.005
- Upstream_request_time:0.001
可見,日志是非結構化文本數據,如果分析,最好把它轉換為結構化數據。
上面就是抽取了各個字段,把日志結構化了,結構化之后,統計、分析就很方便了。
二、日志的應用場景
1、運維監控
包括可用性監控和應用性能監控 (APM)。
2、安全審計
包括安全信息事件管理 (SIEM)、合規審計、發現高級持續威脅 (APT)。
3、用戶及業務統計分析
#p#
三、過去及現在的做法
1、過去
過去對日志是不夠重視的,比如:
1.1 日志沒有集中處理
◆運維工程師登陸每一臺服務器,使用腳本命令或程序查看。
1.2 日志被刪除
◆磁盤滿了刪日志,或者日志回滾。
◆黑客入侵后會刪除日志,抹除入侵痕跡。
1.3 日志只做事后追查
◆沒有集中管理、實時監控、分析。
1.4 使用數據庫存儲日志
后來開始集中管理日志,但使用數據庫存儲日志有什么問題?
◆無法適應TB級海量日志
◆數據庫的schema無法適應千變萬化的日志格式
◆無法提供全文檢索
我見過使用數據庫存日志的,數據庫就三列:產生日志的服務器IP、時間戳、日志原文。沒有對日志字段進行抽取。如果抽取,不同日志有不同字段,數據庫無法適應,而且,數據庫無法提供全文檢索。
2、近年
近年,開始使用Hadoop處理日志,但Hadoop是批處理,查詢慢,不夠及時。Hadoop適合做數據離線挖掘,無法做在線數據挖掘 OLAP (On Line Analytic Processing)。后來又有Storm、Spark Streaming這些流式處理架構,延時比Hadoop好不少,但Hadoop/Storm/Spark都只是一個開發框架,不是拿來即用的產品。也有用各種NoSQL處理日志的,但NoSQL是key-value store,不支持全文檢索。
3、現在
我們需要日志實時搜索分析引擎,它有三個特點:
◆快:
日志從產生到搜索分析出結果只有幾秒的延時。
Google、百度的新聞搜索也只能搜索5分鐘之前的新聞。
◆大:
每天處理 TB 級的日志量。
◆靈活:
Google for IT, 可搜索、分析任何日志,運維工程師的搜索引擎。
簡而言之,這是Fast Big Data,除了大,還要快。
四、日志搜索引擎
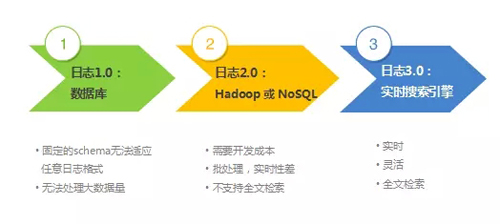
1、日志管理系統的進化:
2、日志易:日志實時搜索分析平臺
1.1 可接入各種來源的數據
◆可接入服務器、網絡設備、操作系統、應用程序的日志文件,數據庫,甚至恒生電子交易系統二進制格式的日志。
1.2 企業部署版及SaaS 版
SaaS版每天500MB日志處理免費,https://www.rizhiyi.com/register/。
五、日志易產品介紹
它的主要功能有:日志搜索、告警、統計、關聯分析(關聯不同系統的日志)。用戶可以在Web頁面配置解析規則,抽取任何日志的任何字段,也開放API,對接第三方系統,供客戶或第三方二次開發。
采用了高性能、可擴展分布式架構,可支持20萬EPS (Event Per Second), 每天數TB日志。
日志易還是個可編程的日志實時搜索分析引擎,用戶可以在搜索框編寫SPL(Search Processing Language,搜索處理語言),使用各種分析命令,通過管道符把這些命令串起來,組成上百行的腳本程序,進行復雜的分析。
這就是李彥宏在云計算剛出現的時候說的“框計算”。給大家看一個例子:某省移動公司做的業務分析。

Q & A
Q1:您說的可編程是ES的表達式?能講一下實現了那些表達式,我們能做些什么功能?
A1:transaction (事務關聯)、eval(算術表達式)、stats(統計)、sort(排序)等等。https://www.rizhiyi.com/docs/howtouse/transaction.html 發布了部分命令的使用指南。
Q2:為什么hadoop不行,這個產品能行,跟ELK有什么區別?
A2:Hadoop實時性差。ELK功能很有限,權限管理很差。日志易有非常豐富的用戶分組、日志分組、基于角色的權限管理。
Q3:請問需要提前對業務日志做格式改造嗎?
A3:不需要,用戶在日志易的Web管理頁配置解析規則,就可以抽取日志的字段了。
Q4:不同日志的怎么關聯起來分析嗎?
A4:不同的日志需要有共同的字段,如ID,來做關聯。
Q5:權限管理自己實現,用web控制,ES索引控制就好了,還有其他權限?
A5:主要是哪個人能看哪條日志里的哪個字段,而且要做到很靈活,方便管理,日志易在中國平安有上百用戶在同時使用,幾百種日志,增加一個用戶,他有什么權限,能看哪些日志,要很方便管理。
Q6:Nosql + spark + Kafka +flume怎么樣?
A6:這還是批處理,而且不支持全文檢索。
Q7:每天6TB的數據,需要多少個elk的節點?然后是否需要增加一些ssd來做處理?
A7:取決于服務器的性能,近百臺服務器吧,有SSD當然更好。
Q8:企業版數據采集,分享一下你們的經驗!
A8:企業版就是部署在客戶的環境,日志易只提供工具,不碰用戶的數據。采集可以使用Linux自帶的rsyslog agent,也可以使用日志易提供的agent,日志易提供的agent可以壓縮、加密,壓縮比1:15。
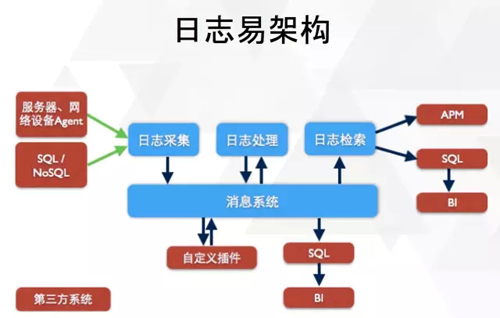
Q9:是否方便展示一下這個系統的架構?
A9:
Q10:你們對es做的改造能實現不同的業務數據按任意的字段進行關聯分析嗎?
A10:只要不同業務的日志包含了相同的字段,就可以關聯分析。
Q11:日志易跟 Splunk 有什么大的區別?
A11:最大的區別是Splunk在檢索的時候抽取字段,日志易是在索引之前抽取字段。所以日志易的檢索速度比Splunk快。
Q12:SaaS版的架構能介紹下嗎?日志易是如何做到數據隔離的?
A12:SaaS環境下,每個租戶有自己的子域名,各租戶登陸到自己的子域名。內部有權限控制、管理。
Q13:看你們的介紹有使用spark-streaming,那它在系統中是用來做什么功能呢?
A13:抽取字段,把日志從非結構化數據轉換成結構化數據。
Q14:你們和SumoLogic比的區別或亮點是什么?
A14:SumoLogic有一些功能,如Log Reduce等,日志易還沒有實現,SumoLogic是純SaaS,日志易同時支持部署版和SaaS。
陳軍
◆日志易創始人兼CEO
◆擁有17年IT及互聯網研發管理經驗,曾就職于Cisco、Google、騰訊和高德軟件,歷任高級軟件工程師、專家工程師、技術總監、技術副總裁等崗位。
◆負責過Cisco路由器研發、Google數據中心系統及搜索系統研發、騰訊數據中心系統和集群任務調度系統研發、高德軟件云平臺系統研發及管理,對數據中心自動化運維和監控、云計算、搜索、大數據和日志分析具有豐富的經驗。
◆他發明了4項計算機網絡及分布式系統的美國專利,擁有美國南加州大學計算機碩士學位。


















