你一定要知道這個運維產品的能力閉環體系
實現一個運維產品的閉環,比碎片式的產品建設更有意義。
拋開我最近創業對這一問題的必要性思考,回歸到一個企業內運維團隊本身,個人覺得也需要思考這個命題。一個完善的運維平臺才能做到對業務的運營有效支撐。個人把產品的水平閉環思考分解成如下幾個問題,從這些角度下去,發現很容易找到該問題本質。
前言
當我們建設一個運維或者業務系統的時候,一定要記得軟件工程方法作用性,比如說系統中的角色(Role)、系統的Use Case(注意不是測試用例)、領域模型(Domain Model)等等。
一、從運維角色來看
從一個系統的完整運維棧來說,存在很多角色。基礎設施層涉及網絡管理員/服務器管理員,再往上服務器資源交付之后,OS層有系統管理員或者基于基礎資源構建的OS云平臺管理員。從應用或服務的角度看過去,在OS之上承載的公共組件服務或者業務的應用服務等等。
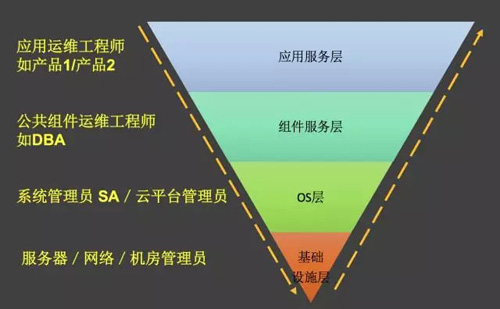
系統建設開始的時候,可以按照角色獨立建設,我理解這是“分而治之”的策略。但隨著后面應用運維的運維平臺的一體化能力不斷增強(比如說騰訊織云/藍鯨),此時就對底層的運維平臺能力開放性要求越來越高。
當然這個地方我建議分成如下三個階段:
1.獨立的按照核心角色需求建設運維平臺。比如說GSLB管理平臺,優先考慮域名管理員的管理需求,如域名管理/Zone管理/View管理/IP地址庫管理等等。
2.某些場景開放給應用運維平臺人工處理。依然以DNS管理平臺為例,這個地方需要打破“DNS管理平臺是DNS管理員的平臺”這一認知。逐漸把能力開放出來,釋放管理員的管理壓力。比如說把域名的管理權限開放給業務運維角色,畢竟這一需求是因為業務而起,但Zone/View/IP地址的管理權限依然要收斂在核心dns管理員角色這邊。
3.某些場景開放給應用運維平臺自動化處理,即API化。第二個階段運行逐漸成熟之后,最重要的是理念已經達成一致,此時可以考慮能力API開放,控制好接口的權限。上層驅動底層能力服務化,進一步打破“我的事情我做主”的職責邊界,從而才能實現“DevOps自動化”的目標。
其實這些角色的需求在不同的平臺中都有存在的,只不過是多與少的問題,底層的服務化能力越強,上層的自動化能力也就愈強;上層的能力整體性越強,越來依賴和驅動底層的能力服務化。
二、從運維場景來看
場景是驅動運維閉環的最好方式,核心的維度就是持續交付。持續交付是一種PDCA式的運維過程,資源交付/服務交付/應用交付等都可以構成一體化的場景吧!拿應用交付舉例來說:
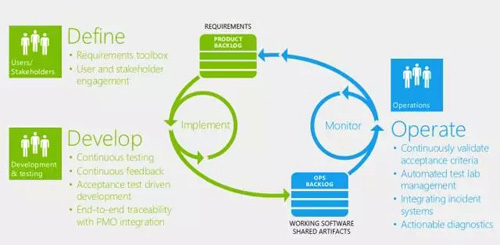
從用戶需求產生到研發/測試/運維,這是一個完整的持續交付鏈。從研發側有一個實施/實現過程,在運維側有個監控能力。在對接的能力上,一方面是用戶的需求隊列;Dev和Ops的對接是一個Ops的需求隊列,從持續集成上來看就是統一構建庫。
從以上的圖可以看出來,這個能力是閉環的,持續迭代的(類似PDCA環),這也是持續交付的典型特征。持續交付的另外一個典型特征:把后續的產品能力優化直接體現在實時的數據運營分析框架之上(持續反饋,類似PDCA中的C),任何滯后與非實時的數據價值都會大大縮水,數據化的運營思路能不斷驅動產品的質量提升。此時我們謹記:運維即IT運營。
三、從域模型的角度來看
域是一種業務域名,降低系統復雜理解的第一步,不是考慮具體的數據和行為實現。復雜的業務系統如同電信的BOSS系統,也分成了幾個核心域,如:客戶域/事件域/產品域/營銷域/賬務域/地址域等等。這樣能確保不同的BOSS子系統(如CRM/計費系統)等,都可以確保在底層數據模型和行為設計上是一致的。
以下是我對運維領域模型的一個分類,如下:
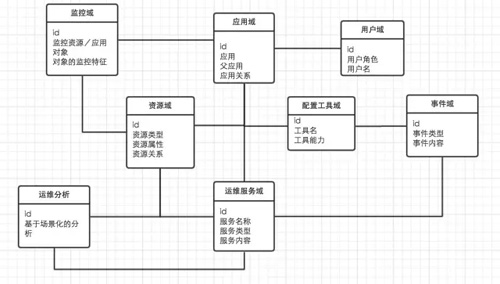
1.應用域。是一個面向應用的信息管理,是構成運維系統場景化的核心元數據,在所有的運維系統中都應該在這個維度上建立起管理關聯。最合理的表達是業務之間的內在邏輯關系,業界通行的做法是資源tag化。
2.資源域。資源是一個泛化的概念,傳統的資源范圍包含了網絡資源/服務器資源等物理資源,但隨著云計算的逐漸普及,此時應該把資源的概念延伸到一些服務上,比如說mysql是一種rds存儲資源;分布式hadoop是一種分布式存儲及計算資源。這個也符合Heroku關于12factor中一個描述,把后端服務當作一種附加資源來看待。
3.運維服務域。資源及服務資源的管理都需要抽象成服務,服務化的管理能力以平臺化/可視化管理為基礎的。mysql有mysql管理平臺,服務器有服務器的管理平臺,cache有cache管理平臺,這些管理平臺能力起來之后,進一步服務化其能力。另外一種服務化能力,是面向應用的場景化服務能力,比如說業務的擴容/遷移等服務能力。
4.配置工具域。以配置管理為基礎,但是這個內容和范疇也需要延伸,它的能力不僅僅是作用在OS對象本身,還能過痛過這個平臺能力去操作外部的資源(通過外部服務實現的)。
以上的域名能構成一個全自動化平臺的能力體系。
5.監控域。無論是資源還是服務,都需要很強的監控能力,他是能過直接表達資源和服務的狀態,通過這些狀態進一步表達業務/應用的健康狀況,目標是確保業務高可用。
6.事件域。無論是作業事件/監控事件,在分布式系統中都存在著很多的事件,這些事件可以放在統一的事件中心中紀錄和存儲,注意和ITIL事件系統不一樣。事件集中管理/關聯,在告警分析的場景下是能過有分析價值的。
7.運營分析。它不能構成一個域,只能稱為一種場景。基于很多運營場景,場景化的數據分析和應用,通過數據來驅動運維優化,類似運營商的經營分析系統。
8.用戶域。這個域名很簡單,把DevOps各類角色管理起來,可以和域帳號對接。
基于這些域可以構建不同的功能子系統,比如說作業管理/運維調度系統/持續部署/監控平臺/CMDB等等。
當然這個是一個運維內部系統,其實如果是一個外部運維SaaS平臺的話,還有客戶域,計費域、賬務域等等。不過,在SaaS模型下,計費和帳務模型可以簡單,我們當前采用的就是“Host.月”的計費模型,這樣的話確保平臺更簡單。
四、從IT運營價值來看
角色+場景能導出對某一類資源的管理功能需求,從而反映IT對業務運營的能力支撐。
一方面:運維平臺的能力必須要向上開放,滿足運營的快速交付。沒有理由在構筑藩籬,這是傳統維護思維的核心障礙。曾經一個團隊就不愿意開放,導致系統的建設七零八落,也就無法滿足DevOps快速交付的能力要求。
另一方面:運營的精細化能力要在數據上體現出來,滿足運營的持續改進。比如說對業務質量的優化,質量模型,數據的來源,數據的實時性等等都需要;性能的優化,就需要運營系統能夠采集所有的接口性能數據;某個頁面的體驗優化,就需要把頁面的性能指標完整的采集下來。精細化/實時/端到端的數據采集/處理/分析體系是運營價值的核心部分。
堅持產品的垂直與水平閉環體系,才是一個做出一個真正好用的運維平臺!