













一個SparkSQL作業的一生可能只是一集瑯琊榜
Spark是時下很火的計算框架,由UC Berkeley AMP Lab研發,并由原班人馬創建的Databricks負責商業化相關事務。而SparkSQL則是Spark之上搭建的SQL解決方案,主打交互查詢場景。
人人都說Spark/SparkSQL快,各種Benchmark滿天飛,但是到底Spark/SparkSQL快么,或者快在哪里,似乎很少有人說得清。因為Spark是基于內存的計算框架?因為SparkSQL有強大的優化器?本文將帶你看一看一個SparkSQL作業到底是如何執行的,順便探討一下SparkSQL和Hive On MapReduce比起來到底有何區別。
SQL On Hadoop的解決方案已經玲瑯滿目了,不管是元祖級的Hive,Cloudera的Impala,MapR的 Drill,Presto,SparkSQL甚至Apache Tajo,IBM BigSQL等等,各家公司都試圖解決SQL交互場景的性能問題,因為原本的Hive On MapReduce實在太慢了。
那么Hive On MapReduce和SparkSQL或者其他交互引擎相比,慢在何處呢?讓我們先看看一個SQL On Hadoop引擎到底如何工作的。
現在的SQL On Hadoop作業,前半段的工作原理都差不多,類似一個Compiler,分來分去都是這基層。
小紅是數據分析,她某天寫了個SQL來統計一個分院系的加權均值分數匯總。
- SELECT dept, avg(math_score * 1.2) + avg(eng_score * 0.8) FROM students
- GROUP BY dept;
其中STUDENTS表是學生分數表(請不要在意這個表似乎不符合范式,很多Hadoop上的數據都不符合范式,因為Join成本高,而且我寫表介紹也會很麻煩)。
她提交了這個查詢到某個SQL On Hadoop平臺執行,然后她放下工作,切到視頻網頁看一會《瑯琊榜》。
在她看視頻的時候,我們的SQL平臺可是有很努力的工作滴。
首先是查詢解析。
這里和很多Compiler類似,你需要一個Parser(就是著名的程序員約架專用項目),Parser(確切說是Lexer加Parser)的作用是把一個字符串流變成一個一個Token,再根據語法定義生成一棵抽象語法樹AST。這里不詳細展開,童鞋們可以參考編譯原理。比較多的項目會選 ANTLR(Hive啦,Presto啦等等),你可以用類似BNF的范式來寫Parser規則,當然也有手寫的比如SparkSQL。AST會進一步包裝成一個簡單的基本查詢信息對象,這個對象包含了一個查詢基本的信息,比如基本語句的類型是SELECT還是INSERT,WHERE是什么,GROUP BY是什么,如果有子查詢,還需要遞歸進去,這個東西大致來說就是所謂的邏輯計劃。
- TableScan(students)
- -> Project(dept, avg(math_score * 1.2) + avg(eng_score * 0.8))
- ->TableSink
上面是無責任示意,具體到某個SQL引擎會略有不同,但是基本上都會這么干。如果你想找一個代碼干凈易懂的SQL引擎,可以參考Presto(可以算我讀過的開源代碼寫的最漂亮的了)。
到上面為止,你已經把字符串轉換成一個所謂的LogicalPlan,這個Plan距離可以求值來說還比較殘疾。最基本來說,我還不知道dept是個啥吧,math_score是神馬類型,AVG是個什么函數,這些都不明了。這樣的LogicalPlan可以稱為Unresolved(殘疾的)Logical Plan。
缺少的是所謂的元數據信息,這里主要包含兩部分:表的Schema和函數信息。表的Schema信息主要包含表的列定義(名字,類型),表的物理位置,格式,如何讀取;函數信息是函數簽名,類的位置等。
有了這些,SQL引擎需要再一次遍歷剛才的殘廢計劃,進行一次深入的解析。最重要的處理是列引用綁定和函數綁定。列引用綁定決定了一個表達式的類型。而有了類型你可以做函數綁定。函數綁定幾乎是這里最關鍵的步驟,因為普通函數比如CAST,和聚合函數比如這里的AVG,分析函數比如Rank以及 Table Function比如explode都會用完全不同的方式求值,他們會被改寫成獨立的計劃節點,而不再是普通的Expression節點。除此之外,還需要進行深入的語義檢測。比如GROUP BY是否囊括了所有的非聚合列,聚合函數是否內嵌了聚合函數,以及最基本的類型兼容檢查,對于強類型的系統,類型不一致比如date = ‘2015-01-01’需要報錯,對于弱類型的系統,你可以添加CAST來做Type(類型) Coerce(茍合)。
然后我們得到了一個尚未優化的邏輯計劃:
- TableScan(students=>dept:String, eng_score:double, math_score:double)
- ->Project(dept, math_score * 1.2:expr1, eng_score * 0.8:expr2)
- ->Aggregate(avg(expr1):expr3, avg(expr2):expr4, GROUP:dept)
- ->Project(dept, expr3+expr4:avg_result)
- ->TableSink(dept, avg_result->Client)
所以我們可以開始上肉戲了?還早呢。
剛才的計劃,還差得很遠,作為一個SQL引擎,沒有優化怎么好見人?不管是SparkSQL還是Hive,都有一套優化器。大多數SQL on Hadoop引擎都有基于規則的優化,少數復雜的引擎比如Hive,擁有基于代價的優化。規則優化很容易實現,比如經典的謂詞下推,可以把Join查詢的過濾條件推送到子查詢預先計算,這樣JOIN時需要計算的數據就會減少(JOIN是最重的幾個操作之一,能用越少的數據做JOIN就會越快),又比如一些求值優化,像去掉求值結果為常量的表達式等等。基于代價的優化就復雜多了,比如根據JOIN代價來調整JOIN順序(最經典的場景),對SparkSQL 來說,代價優化是最簡單的根據表大小來選擇JOIN策略(小表可以用廣播分發),而沒有JOIN順序交換這些,而JOIN策略選擇則是在隨后要解釋的物理執行計劃生成階段。
到這里,如果還沒報錯,那你就幸運滴得到了一個Resolved(不殘廢的)Logical Plan了。這個Plan,再配上表達式求值器,你也可以折騰折騰在單機對表查詢求值了。但是,我們不是做分布式系統的么?數據分析妹子已經看完《瑯琊榜》的片頭了,你還在悠閑什么呢?
為了讓妹子在看完電視劇之前算完幾百G的數據,我們必須借助分布式的威力,畢竟單節點算的話夠妹子看完整個瑯琊榜劇集了。剛才生成的邏輯計劃,之所以稱為邏輯計劃,是因為它只是邏輯上看起來似乎能執行了(誤),實際上我們并不知道具體這個東西怎么對應Spark或者MapReduce任務。
邏輯執行計劃接下來需要轉換成具體可以在分布式情況下執行的物理計劃,你還缺少:怎么和引擎對接,怎么做表達式求值兩個部分。
表達式求值有兩種基本策略,一個是解釋執行,直接把之前帶來的表達式進行解釋執行,這個是Hive現在的模式;另一個是代碼生成,包括 SparkSQL,Impala,Drill等等號稱新一代的引擎都是代碼生成模式的(并且配合高速編譯器)。不管是什么模式,你最終把表達式求值部分封裝成了類。代碼可能長得類似如下:
- // math_score * 1.2
- val leftOp = row.get(1/* math_score column index */);
- val result = if (leftOp == null) then null else leftOp * 1.2;
每個獨立的SELECT項目都會生成這樣一段表達式求值代碼或者封裝過的求值器。但是AVG怎么辦?當初寫wordcount的時候,我記得聚合計算需要分派在Map和Reduce兩個階段呀?這里就涉及到物理執行轉換,涉及到分布式引擎的對接。
AVG這樣的聚合計算,加上GROUP BY的指示,告訴了底層的分布式引擎你需要怎么做聚合。本質上來說AVG聚合需要拆分成Map階段來計算累加,還有條目個數,以及Reduce階段二次累加最后每個組做除法。
因此我們要算的AVG其實會進一步拆分成兩個計劃節點:Aggregates(Partial)和Aggregates(Final)。 Partial部分是我們計算局部累加的部分,每個Mapper節點都將執行,然后底層引擎會做一個Shuffle,將相同Key(在這里是Dept)的行分發到相同的Reduce節點。這樣經過最終聚合你才能拿到最后結果。
拆完聚合函數,如果只是上面案例給的一步SQL,那事情比較簡單,如果還有多個子查詢,那么你可能面臨多次Shuffle,對于MapReduce 來說,每次Shuffle你需要一個MapReduce Job來支撐,因為MapReduce模型中,只有通過Reduce階段才能做Shuffle操作,而對于Spark來說,Shuffle可以隨意擺放,不過你要根據Shuffle來拆分Stage。這樣拆過之后,你得到一個多個MR Job串起來的DAG或者一個Spark多個Stage的DAG(有向無環圖)。
還記得剛才的執行計劃么?它最后變成了這樣的物理執行計劃:
- TableScan->Project(dept, math_score * 1.2: expr1, eng_score * 0.8: expr2)
- -> AggretatePartial(avg(expr1):avg1, avg(expr2):avg2, GROUP: dept)
- -> ShuffleExchange(Row, KEY:dept)
- -> AggregateFinal(avg1, avg2, GROUP:dept)
- -> Project(dept, avg1 + avg2)
- -> TableSink
這東西到底怎么在MR或者Spark中執行啊?對應Shuffle之前和之后,物理上它們將在不同批次的計算節點上執行。不管對應 MapReduce引擎還是Spark,它們分別是Mapper和Reducer,中間隔了Shuffle。上面的計劃,會由 ShuffleExchange中間斷開,分別發送到Mapper和Reducer中執行,當然除了上面的部分還有之前提到的求值類,也都會一起序列化發送。
實際在MapReduce模型中,你最終執行的是一個特殊的Mapper和特殊的Reducer,它們分別在初始化階段載入被序列化的Plan和求值器信息,然后在map和reduce函數中依次對每個輸入求值;而在Spark中,你生成的是一個一個RDD變換操作。
比如一個Project操作,對于MapReduce來說,偽代碼大概是這樣的:
- void configuration() {
- context = loadContext()
- }
- void map(inputRow) {
- outputRow = context.projectEvaluator (inputRow);
- write(outputRow);
- }
對于Spark,大概就是這樣:
- currentPlan.mapPartitions { iter =>
- projection = loadContext()
- iter.map { row => projection(row) } }
至此為止,引擎幫你愉快滴提交了Job,你的集群開始不緊不慢地計算了。
到這里為止,似乎看起來SparkSQL和Hive On MapReduce沒有什么區別?其實SparkSQL快,并不快在引擎。
SparkSQL的引擎優化,并沒有Hive復雜,畢竟人Hive多年積累,十多年下來也不是吃素的。但是Spark本身快呀。
Spark標榜自己比MapReduce快幾倍幾十倍,很多人以為這是因為Spark是“基于內存的計算引擎”,其實這不是真的。Spark還是要落磁盤的,Shuffle的過程需要也會將中間數據吐到本地磁盤上。所以說Spark是基于內存計算的說法,不考慮手動Cache的情景,是不正確的。
SparkSQL的快,根本不是剛才說的那一坨東西哪兒比Hive On MR快了,而是Spark引擎本身快了。
事實上,不管是SparkSQL,Impala還是Presto等等,這些標榜第二代的SQL On Hadoop引擎,都至少做了三個改進,消除了冗余的HDFS讀寫,冗余的MapReduce階段,節省了JVM啟動時間。
在MapReduce模型下,需要Shuffle的操作,就必須接入一個完整的MapReduce操作,而接入一個MR操作,就必須將前階段的MR結果寫入HDFS,并且在Map階段重新讀出來,這才是萬惡之源。
事實上,如果只是上面的SQL查詢,不管用MapReduce還是Spark,都不一定會有顯著的差異,因為它只經過了一個shuffle階段。
真正體現差異的,是這樣的查詢:
- SELECT g1.name, g1.avg, g2.cnt
- FROM (SELECT name, avg(id) AS avg FROM students GROUP BY name) g1
- JOIN (SELECT name, count(id) AS cnt FROM students GROUP BY name) g2
- ON (g1.name = g2.name)
- ORDER BY avg;
而他們所對應的MR任務和Spark任務分別是這樣的:
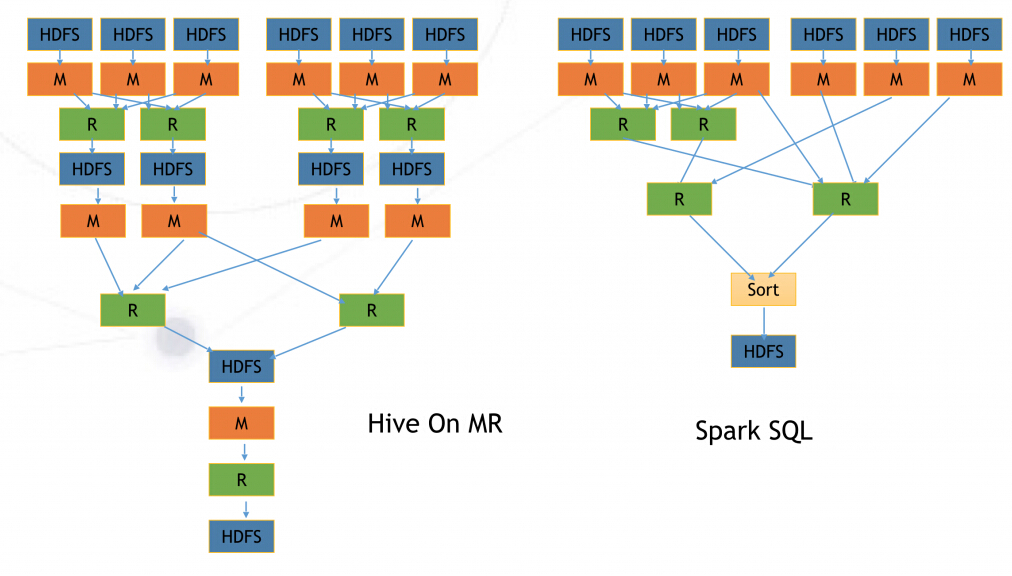
一次HDFS中間數據寫入,其實會因為Replication的常數擴張為三倍寫入,而磁盤讀寫是非常耗時的。這才是Spark速度的主要來源。
另一個加速,來自于JVM重用。考慮一個上萬Task的Hive任務,如果用MapReduce執行,每個Task都會啟動一次JVM,而每次JVM啟動時間可能就是幾秒到十幾秒,而一個短Task的計算本身可能也就是幾秒到十幾秒,當MR的Hive任務啟動完成,Spark的任務已經計算結束了。對于短 Task多的情形下,這是很大的節省。
說到這里,小紅已經看完《瑯琊榜》回來了,接下去我們討論一下劇情吧。。。
















