Linux進程資源用量監控和按用戶設置進程限制

由于 2016 年 2 月 2 號開始啟用了新的 LFCS 考試要求,我們在已經發表的 LFCS 系列 基礎上增加了一些必要的主題。為了準備考試,同時也建議你看看 LFCE 系列 文章。
每個 Linux 系統管理員都應該知道如何驗證硬件、資源和主要進程的完整性和可用性。另外,基于每個用戶設置資源限制也是其中一項必備技能。
在這篇文章中,我們會介紹一些能夠確保系統硬件和軟件正常工作的方法,這些方法能夠避免潛在的會導致生產環境下線或錢財損失的問題發生。
報告 Linux 進程統計信息
你可以使用 mpstat 單獨查看每個處理器或者系統整體的活動,可以是每次一個快照或者動態更新。
為了使用這個工具,你首先需要安裝 sysstat:
- # yum update && yum install sysstat [基于 CentOS 的系統]
- # aptitutde update && aptitude install sysstat [基于 Ubuntu 的系統]
- # zypper update && zypper install sysstat [基于 openSUSE 的系統]
你可以在 在 Linux 中學習 Sysstat 和其中的工具 mpstat、pidstat、iostat 和 sar 了解更多和 sysstat 和其中的工具相關的信息。
安裝完 mpstat 之后,就可以使用它生成處理器統計信息的報告。
你可以使用下面的命令每隔 2 秒顯示所有 CPU(用 -P ALL 表示)的 CPU 利用率(-u),共顯示 3 次。
- # mpstat -P ALL -u 2 3
示例輸出:
- Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
- 11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
- 11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
- 11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
- 11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
- 11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
- 11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
- 11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
- 11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
- 11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
- 11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
- 11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
- 11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
- 11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
- 11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
- 11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
- 11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
- 11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
- 11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
- Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
- Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
- Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
- Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
- Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
- Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
要查看指定的 CPU(在下面的例子中是 CPU 0),可以使用:
- # mpstat -P 0 -u 2 3
示例輸出:
- Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
- 11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
- 11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
- 11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
- 11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
- Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
上面命令的輸出包括這些列:
- CPU: 整數表示的處理器號或者 all 表示所有處理器的平均值。
- %usr: 運行在用戶級別的應用的 CPU 利用率百分數。
- %nice: 和 %usr 相同,但有 nice 優先級。
- %sys: 執行內核應用的 CPU 利用率百分比。這不包括用于處理中斷或者硬件請求的時間。
- %iowait: 指定(或所有)CPU 的空閑時間百分比,這表示當前 CPU 處于 I/O 操作密集的狀態。更詳細的解釋(附帶示例)可以查看這里。
- %irq: 用于處理硬件中斷的時間所占百分比。
- %soft: 和 %irq 相同,但是是軟中斷。
- %steal: 虛擬機非自主等待(時間片竊取)所占時間的百分比,即當虛擬機在競爭 CPU 時所從虛擬機管理程序那里“贏得”的時間。應該保持這個值盡可能小。如果這個值很大,意味著虛擬機正在或者將要停止運轉。
- %guest: 運行虛擬處理器所用的時間百分比。
- %idle: CPU 沒有運行任何任務所占時間的百分比。如果你觀察到這個值很小,意味著系統負載很重。在這種情況下,你需要查看詳細的進程列表、以及下面將要討論的內容來確定這是什么原因導致的。
運行下面的命令使處理器處于極高負載,然后在另一個終端執行 mpstat 命令:
- # dd if=/dev/zero of=test.iso bs=1G count=1
- # mpstat -u -P 0 2 3
- # ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
- # mpstat -u -P 0 2 3
最后,和 “正常” 情況下 mpstat 的輸出作比較:
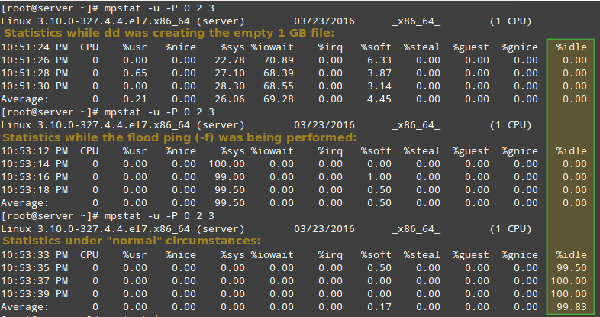
Linux 處理器相關統計信息報告
正如你在上面圖示中看到的,在前面兩個例子中,根據 %idle 的值可以判斷 CPU 0 負載很高。
在下一部分,我們會討論如何識別資源饑餓型進程,如何獲取更多和它們相關的信息,以及如何采取恰當的措施。
Linux 進程報告
我們可以使用有名的 ps 命令,用 -eo 選項(根據用戶定義格式選中所有進程) 和 --sort 選項(指定自定義排序順序)按照 CPU 使用率排序列出進程,例如:
- # ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
上面的命令只會顯示 PID、PPID、和進程相關的命令、 CPU 使用率以及 RAM 使用率,并按照 CPU 使用率降序排序。創建 .iso 文件的時候運行上面的命令,下面是輸出的前面幾行:
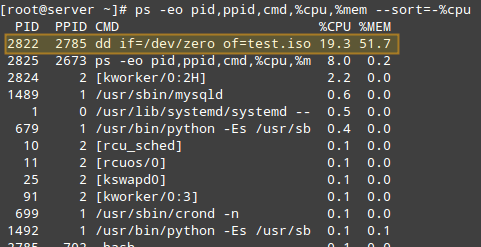
根據 CPU 使用率查找進程
一旦我們找到了感興趣的進程(例如 PID=2822 的進程),我們就可以進入 /proc/PID(本例中是 /proc/2822) 列出目錄內容。
這個目錄就是進程運行的時候保存多個關于該進程詳細信息的文件和子目錄的目錄。
例如:
- /proc/2822/io 包括該進程的 IO 統計信息(IO 操作時的讀寫字符數)。
- /proc/2822/attr/current 顯示了進程當前的 SELinux 安全屬性。
- /proc/2822/cgroup 如果啟用了 CONFIGCGROUPS 內核設置選項,這會顯示該進程所屬的控制組(簡稱 cgroups),你可以使用下面命令驗證是否啟用了 CONFIGCGROUPS:
- # cat /boot/config-$(uname -r) | grep -i cgroups
如果啟用了該選項,你應該看到:
- CONFIG_CGROUPS=y
根據 紅帽企業版 Linux 7 資源管理指南 第一到四章的內容、openSUSE 系統分析和調優指南 第九章、Ubuntu 14.04 服務器文檔 Control Groups 章節,你可以使用 cgroups 管理每個進程允許使用的資源數目。
/proc/2822/fd 這個目錄包含每個打開的描述進程的文件的符號鏈接。下面的截圖顯示了 tty1(第一個終端) 中創建 .iso 鏡像進程的相關信息:
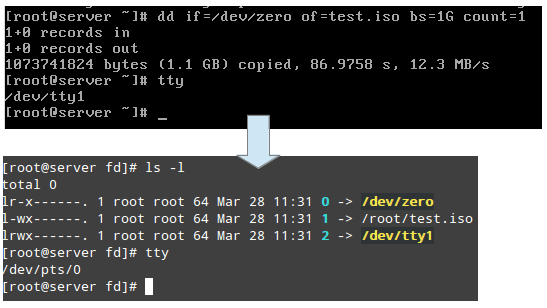
查找 Linux 進程信息
上面的截圖顯示 stdin(文件描述符 0)、stdout(文件描述符 1)、stderr(文件描述符 2) 相應地被映射到 /dev/zero、 /root/test.iso 和 /dev/tty1。
更多關于 /proc 信息的可以查看 Kernel.org 維護的 “/proc 文件系統” 和 Linux 開發者手冊。
在 Linux 中為每個用戶設置資源限制
如果你不夠小心、讓任意用戶使用不受限制的進程數,最終你可能會遇到意外的系統關機或者由于系統進入不可用的狀態而被鎖住。為了防止這種情況發生,你應該為用戶可以啟動的進程數目設置上限。
你可以在 /etc/security/limits.conf 文件末尾添加下面一行來設置限制:
- * hard nproc 10
第一個字段可以用來表示一個用戶、組或者所有人(*), 第二個字段強制限制可以使用的進程數目(nproc) 為 10。退出并重新登錄就可以使設置生效。
然后,讓我們來看看非 root 用戶(合法用戶或非法用戶) 試圖引起 shell fork 炸彈 (參見 WiKi) 時會發生什么。如果我們沒有設置限制, shell fork 炸彈會無限制地啟動函數的兩個實例,然后無限循環地復制任意一個實例。最終導致你的系統卡死。
但是,如果使用了上面的限制,fort 炸彈就不會成功,但用戶仍然會被鎖在外面直到系統管理員殺死相關的進程。
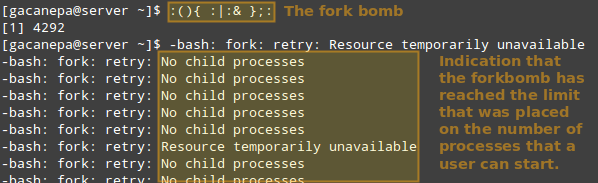
運行 Shell Fork 炸彈
提示: limits.conf 文件中可以查看其它 ulimit 可以更改的限制。
其它 Linux 進程管理工具
除了上面討論的工具, 一個系統管理員還可能需要:
a) 通過使用 renice 調整執行優先級(系統資源的使用)。這意味著內核會根據分配的優先級(眾所周知的 “niceness”,它是一個范圍從 -20 到 19 的整數)給進程分配更多或更少的系統資源。
這個值越小,執行優先級越高。普通用戶(而非 root)只能調高他們所有的進程的 niceness 值(意味著更低的優先級),而 root 用戶可以調高或調低任何進程的 niceness 值。
renice 命令的基本語法如下:
- # renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
如果 new priority 后面的參數沒有(為空),默認就是 PID。在這種情況下,PID=identifier 的進程的 niceness 值會被設置為 <new priority>。
b) 需要的時候中斷一個進程的正常執行。這也就是通常所說的“殺死”進程。實質上,這意味著給進程發送一個信號使它恰當地結束運行并以有序的方式釋放任何占用的資源。
按照下面的方式使用 kill 命令殺死進程:
- # kill PID
另外,你也可以使用 pkill 結束指定用戶(-u)、指定組(-G) 甚至有共同的父進程 ID (-P) 的所有進程。這些選項后面可以使用數字或者名稱表示的標識符。
- # pkill [options] identifier
例如:
- # pkill -G 1000
會殺死組 GID=1000 的所有進程。而
- # pkill -P 4993
會殺死 PPID 是 4993 的所有進程。
在運行 pkill 之前,先用 pgrep 測試結果、或者使用 -l 選項列出進程名稱是一個很好的辦法。它需要和 pkill 相同的參數、但是只會返回進程的 PID(而不會有其它操作),而 pkill 會殺死進程。
- # pgrep -l -u gacanepa
用下面的圖片說明:

在 Linux 中查找用戶運行的進程
總結
在這篇文章中我們探討了一些監控資源使用的方法,以便驗證 Linux 系統中重要硬件和軟件組件的完整性和可用性。
我們也學習了如何在特殊情況下采取恰當的措施(通過調整給定進程的執行優先級或者結束進程)。
我們希望本篇中介紹的概念能對你有所幫助。如果你有任何疑問或者評論,可以使用下面的聯系方式聯系我們。