













談一談如何在Python開發中拒絕SSRF漏洞
一 、SSRF漏洞常見防御手法及繞過方法
SSRF是一種常見的Web漏洞,通常存在于需要請求外部內容的邏輯中,比如本地化網絡圖片、XML解析時的外部實體注入、軟件的離線下載等。當攻擊者傳入一個未經驗證的URL,后端代碼直接請求這個URL,將會造成SSRF漏洞。
具體危害體現在以下幾點上:
URL為內網IP或域名,攻擊者將可以通過SSRF漏洞掃描目標內網,查找內網內的漏洞,并想辦法反彈權限
URL中包含端口,攻擊者將可以掃描并發現內網中機器的其他服務,再進一步進行利用
當請求方法允許其他協議的時候,將可能利用gopher、file等協議進行第三方服務利用,如利用內網的redis獲取權限、利用fastcgi進行getshell等
特別是這兩年,大量利用SSRF攻擊內網服務的案例被爆出來,導致SSRF漏洞慢慢受到重視。這就給Web應用開發者提出了一個難題:如何在保證業務正常的情況下防御SSRF漏洞?
很多開發者認為,只要檢查一下請求url的host不為內網IP,即可防御SSRF。這個觀點其實提出了兩個技術要點:
1.如何檢查IP是否為內網IP
2.如何獲取真正請求的host
于是,攻擊者通過這兩個技術要點,針對性地想出了很多繞過方法。
二、 如何檢查IP是否為內網IP
這實際上是很多開發者面臨的第一個問題,很多新手甚至連內網IP常用的段是多少也不清楚。
何謂內網IP,實際上并沒有一個硬性的規定,多少到多少段必須設置為內網。有的管理員可能會將內網的IP設置為233.233.233.0/24段,當然這是一個比較極端的例子。
通常我們會將以下三個段設置為內網IP段,所有內網內的機器分配到的IP是在這些段中:
- 192.168.0.0/16 => 192.168.0.0 ~ 192.168.255.255
- 10.0.0.0/8 => 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0/12 => 172.16.0.0 ~ 172.31.255.255
所以通常,我們只需要判斷目標IP不在這三個段,另外還包括一個 127.0.0.0/8 段即可。
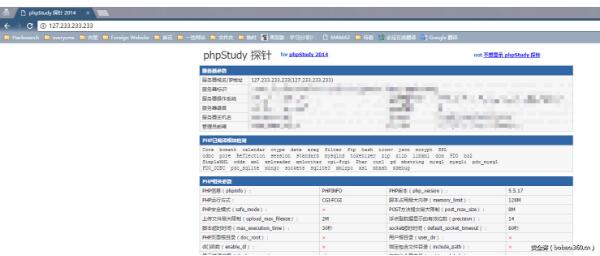
很多人會忘記 127.0.0.0/8 ,認為本地地址就是 127.0.0.1 ,實際上本地回環包括了整個127段。你可以訪問http://127.233.233.233/,會發現和請求127.0.0.1是一個結果:
所以我們需要防御的實際上是4個段,只要IP不落在這4個段中,就認為是“安全”的。
網上一些開發者會選擇使用“正則”的方式判斷目標IP是否在這四個段中,這種判斷方法通常是會遺漏或誤判的,比如如下代碼:

這是Sec-News最老版本判斷內網IP的方法,里面使用正則判斷IP是否在內網的幾個段中。這個正則也是我當時臨時在網上搜的,很明顯這里存在多個繞過的問題:
1. 利用八進制IP地址繞過
2. 利用十六進制IP地址繞過
3. 利用十進制的IP地址繞過
4. 利用IP地址的省略寫法繞過
這四種方式我們可以依次試試:
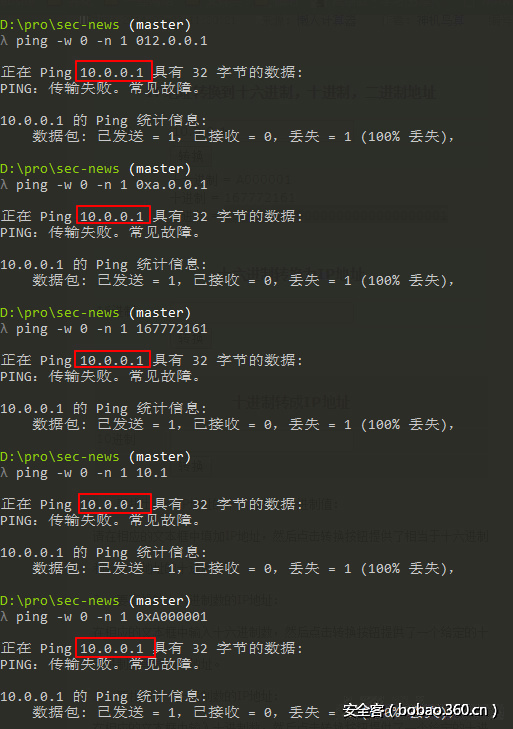
四種寫法(5個例子):012.0.0.1 、 0xa.0.0.1 、 167772161 、 10.1 、 0xA000001 實際上都請求的是10.0.0.1,但他們一個都匹配不上上述正則表達式。
更聰明一點的人是不會用正則表達式來檢測IP的(也許這類人并不知道內網IP的正則該怎么寫)。Wordpress的做法是,先將IP地址規范化,然后用“.”將其分割成數組parts,然后根據parts[0]和parts[1]的取值來判斷:

其實也略顯麻煩,而且曾經也出現過用進制方法繞過的案例( WordPress <4.5 SSRF 分析 ),不推薦使用。
我后來選擇了一種更為簡單的方法。眾所周知,IP地址是可以轉換成一個整數的,在PHP中調用ip2long函數即可轉換,在Python使用inet_aton去轉換。
而且IP地址是和2^32內的整數一一對應的,也就是說0.0.0.0 == 0,255.255.255.255 == 2^32 - 1。所以,我們判斷一個IP是否在某個IP段內,只需將IP段的起始值、目標IP值全部轉換為整數,然后比較大小即可。
于是,我們可以將之前的正則匹配的方法修改為如下方法:

這就是一個最簡單的方法,也最容易理解。
假如你懂一點掩碼的知識,你應該知道IP地址的掩碼實際上就是(32 - IP地址所代表的數字的末尾bit數)。所以,我們只需要保證目標IP和內網邊界IP的前“掩碼”位bit相等即可。借助位運算,將以上判斷修改地更加簡單:
- from socket import inet_aton
- from struct import unpack
- def ip2long(ip_addr):
- return unpack("!L", inet_aton(ip_addr))[0]
- def is_inner_ipaddress(ip):
- ip = ip2long(ip)
- return ip2long('127.0.0.0') >> 24 == ip >> 24 or \
- ip2long('10.0.0.0') >> 24 == ip >> 24 or \
- ip2long('172.16.0.0') >> 20 == ip >> 20 or \
- ip2long('192.168.0.0') >> 16 == ip >> 16
以上代碼也就是Python中判斷一個IP是否是內網IP的最終方法,使用時調用is_inner_ipaddress(...)即可(注意自己編寫捕捉異常的代碼)。
三、 host獲取與繞過
如何獲取"真正請求"的Host,這里需要考慮三個問題:
1. 如何正確的獲取用戶輸入的URL的Host?
2. 只要Host只要不是內網IP即可嗎?
3. 只要Host指向的IP不是內網IP即可嗎?
如何正確的獲取用戶輸入的URL的Host?
第一個問題,看起來很簡單,但實際上有很多網站在獲取Host上犯過一些錯誤。最常見的就是,使用http://233.233.233.233@10.0.0.1:8080/、http://10.0.0.1#233.233.233.233這樣的URL,讓后端認為其Host是233.233.233.233,實際上請求的卻是10.0.0.1。這種方法利用的是程序員對URL解析的錯誤,有很多程序員甚至會用正則去解析URL。
在Python 3下,正確獲取一個URL的Host的方法:
- from urllib.parse import urlparse
- url = 'https://10.0.0.1/index.php'
- urlparse(url).hostname
這一步一定不能犯錯,否則后面的工作就白做了。
只要Host只要不是內網IP即可嗎?
第二個問題,只要檢查一下我們獲取到的Host是否是內網IP,即可防御SSRF漏洞么?
答案是否定的,原因是,Host可能是IP形式,也可能是域名形式。如果Host是域名形式,我們是沒法直接比對的。只要其解析到內網IP上,就可以繞過我們的is_inner_ipaddress了。
網上有個服務 http://xip.io ,這是一個“神奇”的域名,它會自動將包含某個IP地址的子域名解析到該IP。比如 127.0.0.1.xip.io ,將會自動解析到127.0.0.1,www.10.0.0.1.xip.io將會解析到10.0.0.1:
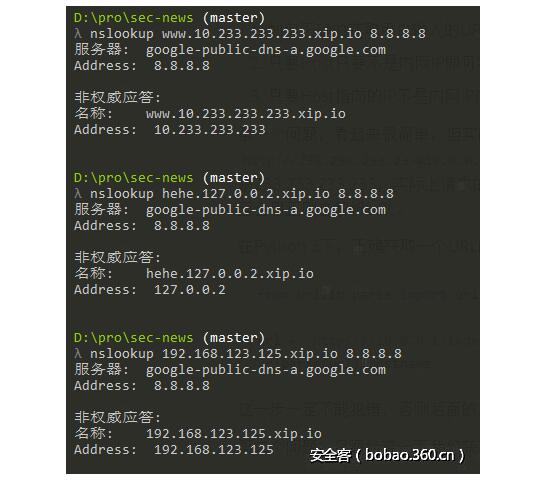
這個域名極大的方便了我們進行SSRF漏洞的測試,當我們請求http://127.0.0.1.xip.io/info.php的時候,表面上請求的Host是127.0.0.1.xip.io,此時執行is_inner_ipaddress('127.0.0.1.xip.io')是不會返回True的。但實際上請求的卻是127.0.0.1,這是一個標準的內網IP。
所以,在檢查Host的時候,我們需要將Host解析為具體IP,再進行判斷,代碼如下:
- import socket
- import re
- from urllib.parse import urlparse
- from socket import inet_aton
- from struct import unpack
- def check_ssrf(url):
- hostname = urlparse(url).hostname
- def ip2long(ip_addr):
- return unpack("!L", inet_aton(ip_addr))[0]
- def is_inner_ipaddress(ip):
- ip = ip2long(ip)
- return ip2long('127.0.0.0') >> 24 == ip >> 24 or \
- ip2long('10.0.0.0') >> 24 == ip >> 24 or \
- ip2long('172.16.0.0') >> 20 == ip >> 20 or \
- ip2long('192.168.0.0') >> 16 == ip >> 16
- try:
- if not re.match(r"^https?://.*/.*$", url):
- raise BaseException("url format error")
- ip_address = socket.getaddrinfo(hostname, 'http')[0][4][0]
- if is_inner_ipaddress(ip_address):
- raise BaseException("inner ip address attack")
- return True, "success"
- except BaseException as e:
- return False, str(e)
- except:
- return False, "unknow error"
首先判斷url是否是一個HTTP協議的URL(如果不檢查,攻擊者可能會利用file、gopher等協議進行攻擊),然后獲取url的host,并解析該host,最終將解析完成的IP放入is_inner_ipaddress函數中檢查是否是內網IP。
只要Host指向的IP不是內網IP即可嗎?
第三個問題,是不是做了以上工作,解析并判斷了Host指向的IP不是內網IP,即防御了SSRF漏洞?
答案繼續是否定的,上述函數并不能正確防御SSRF漏洞。為什么?
當我們請求的目標返回30X狀態的時候,如果沒有禁止跳轉的設置,大部分HTTP庫會自動跟進跳轉。此時如果跳轉的地址是內網地址,將會造成SSRF漏洞。
這個原因也很好理解,我以Python的requests庫為例。requests的API中有個設置,叫allow_redirects,當將其設置為True的時候requests會自動進行30X跳轉。而默認情況下(開發者未傳入這個參數的情況下),requests會默認將其設置為True:

所以,我們可以試試請求一個302跳轉的網址:

默認情況下,將會跟蹤location指向的地址,所以返回的status code是最終訪問的頁面的狀態碼。而設置了allow_redirects的情況下,將會直接返回302狀態碼。
所以,即使我們獲取了http://t.cn/R2iwH6d的Host,通過了is_inner_ipaddress檢查,也會因為302跳轉,跳到一個內網IP,導致SSRF。
這種情況下,我們有兩種解決方法:
1. 設置allow_redirects=False,不允許目標進行跳轉
2. 每跳轉一次,就檢查一次新的Host是否是內網IP,直到抵達最后的網址
第一種情況明顯是會影響業務的,只是規避問題而未解決問題。當業務上需要目標URL能夠跳轉的情況下,只能使用第二種方法了。
所以,歸納一下,完美解決SSRF漏洞的過程如下:
1. 解析目標URL,獲取其Host
2. 解析Host,獲取Host指向的IP地址
3. 檢查IP地址是否為內網IP
4. 請求URL
5. 如果有跳轉,拿出跳轉URL,執行1
0x04 使用requests庫的hooks屬性來檢查SSRF
那么,上一章說的5個過程,具體用Python怎么實現?
我們可以寫一個循環,循環條件就是“該次請求的狀態碼是否是30X”,如果是就繼續執行循環,繼續跟進location,如果不是,則退出循環。代碼如下:
- r = requests.get(url, allow_redirects=False)
- while r.is_redirect:
- url = r.headers['location']
- succ, errstr = check_ssrf(url)
- if not succ:
- raise Exception('SSRF Attack.')
- r = requests.get(url, allow_redirects=False)
這個代碼思路大概沒有問題,但非常簡陋,而且效率不高。
只要你翻翻requests的源代碼,你會發現,它在處理30X跳轉的時候考慮了很多地方:
- 所有請求放在一個requests.Session()中
- 跳轉有個緩存,當下次跳轉地址在緩存中的時候,就不用多次請求了
- 跳轉數量有最大限制,不可能無窮無盡跳下去
- 解決307跳轉出現的一些BUG等
如果說就按照之前簡陋的代碼編寫程序,固然可以防御SSRF漏洞,但上述提高效率的方法均沒用到。
那么,有更好的解決方法么?當然有,我們翻一下requests的源代碼,可以看到一行特殊的代碼:
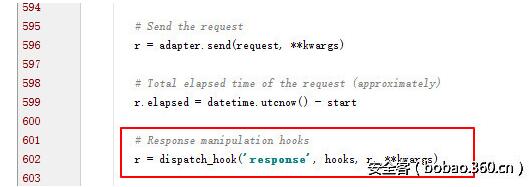
hook的意思就是“劫持”,意思就是在hook的位置我可以插入我自己的代碼。我們看看dispatch_hook函數做了什么:
- def dispatch_hook(key, hooks, hook_data, **kwargs):
- """Dispatches a hook dictionary on a given piece of data."""
- hookshooks = hooks or dict()
- hookshooks = hooks.get(key)
- if hooks:
- if hasattr(hooks, '__call__'):
- hooks = [hooks]
- for hook in hooks:
- _hook_data = hook(hook_data, **kwargs)
- if _hook_data is not None:
- hook_data = _hook_data
- return hook_data
hooks是一個函數,或者一系列函數。這里做的工作就是遍歷這些函數,并調用:
- _hook_data = hook(hook_data,**kwargs)
我們翻翻文檔,可以找到hooks event的說明 http://docs.python-requests.org/en/master/user/advanced/?highlight=hook#event-hooks :
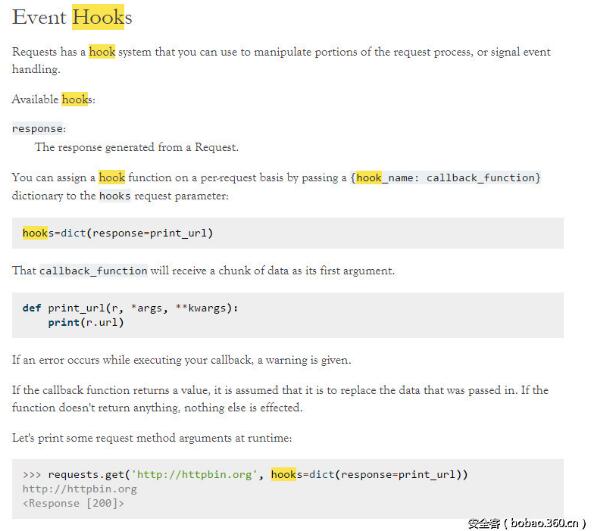
文檔中定義了一個print_url函數,將其作為一個hook函數。在請求的過程中,響應對象被傳入了print_url函數,請求的域名被打印了下來。
我們可以考慮一下,我們將檢查SSRF的過程也寫為一個hook函數,然后傳給requests.get,在之后的請求中一旦獲取response就會調用我們的hook函數。這樣,即使我設置allow_redirects=True,requests在每次請求后都會調用一次hook函數,在hook函數里我只需檢查一下response.headers['location']即可。
說干就干,先寫一個hook函數:
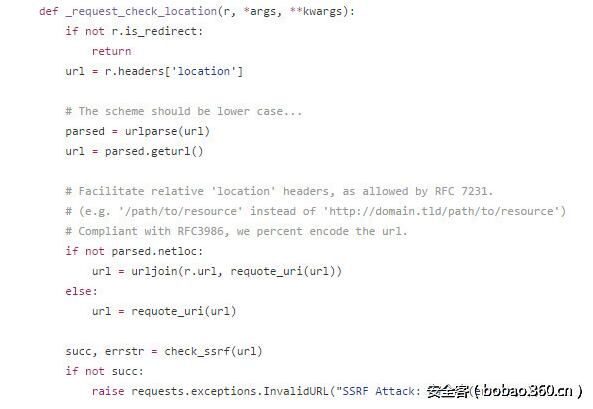
當r.is_redirect為True的時候,也就是說這次請求包含一個跳轉。獲取此時的r.headers['location'],并進行一些處理,最后傳入check_ssrf。當檢查不通過時,拋出一個異常。
然后編寫一個請求函數safe_request_url,意思是“安全地請求一個URL”。使用這個函數請求的域名,將不會出現SSRF漏洞:

我們可以看到,在第一次請求url前,還是需要check_ssrf一次的。因為hook函數_request_check_location只是檢查30X跳轉時是否存在SSRF漏洞,而沒有檢查最初請求是否存在SSRF漏洞。
不過上面的代碼還不算完善,因為_request_check_location覆蓋了原有(用戶可能定義的其他hooks)的hooks屬性,所以需要簡單調整一下。
最終,給出完整代碼:
- import socket
- import re
- import requests
- from urllib.parse import urlparse
- from socket import inet_aton
- from struct import unpack
- from requests.utils import requote_uri
- def check_ssrf(url):
- hostname = urlparse(url).hostname
- def ip2long(ip_addr):
- return unpack("!L", inet_aton(ip_addr))[0]
- def is_inner_ipaddress(ip):
- ip = ip2long(ip)
- return ip2long('127.0.0.0') >> 24 == ip >> 24 or \
- ip2long('10.0.0.0') >> 24 == ip >> 24 or \
- ip2long('172.16.0.0') >> 20 == ip >> 20 or \
- ip2long('192.168.0.0') >> 16 == ip >> 16
- try:
- if not re.match(r"^https?://.*/.*$", url):
- raise BaseException("url format error")
- ip_address = socket.getaddrinfo(hostname, 'http')[0][4][0]
- if is_inner_ipaddress(ip_address):
- raise BaseException("inner ip address attack")
- return True, "success"
- except BaseException as e:
- return False, str(e)
- except:
- return False, "unknow error"
- def safe_request_url(url, **kwargs):
- def _request_check_location(r, *args, **kwargs):
- if not r.is_redirect:
- return
- url = r.headers['location']
- # The scheme should be lower case...
- parsed = urlparse(url)
- url = parsed.geturl()
- # Facilitate relative 'location' headers, as allowed by RFC 7231.
- # (e.g. '/path/to/resource' instead of 'http://domain.tld/path/to/resource')
- # Compliant with RFC3986, we percent encode the url.
- if not parsed.netloc:
- url = urljoin(r.url, requote_uri(url))
- else:
- url = requote_uri(url)
- succ, errstr = check_ssrf(url)
- if not succ:
- raise requests.exceptions.InvalidURL("SSRF Attack: %s" % (errstr, ))
- success, errstr = check_ssrf(url)
- if not success:
- raise requests.exceptions.InvalidURL("SSRF Attack: %s" % (errstr,))
- all_hooks = kwargs.get('hooks', dict())
- if 'response' in all_hooks:
- if hasattr(all_hooks['response'], '__call__'):
- r_hooks = [all_hooks['response']]
- else:
- r_hooks = all_hooks['response']
- r_hooks.append(_request_check_location)
- else:
- r_hooks = [_request_check_location]
- all_hooks['response'] = r_hooks
- kwargs['hooks'] = all_hooks
- return requests.get(url, **kwargs)
外部程序只要調用safe_request_url(url)即可安全地請求某個URL,該函數的參數與requests.get函數參數相同。
完美在Python Web開發中解決SSRF漏洞。其他語言的解決方案類似,大家可以自己去探索。
參考內容:
http://www.luteam.com/?p=211
http://docs.python-requests.org/












