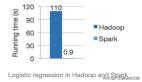
理解Spark的核心RDD
與許多專有的大數據處理平臺不同,Spark建立在統一抽象的RDD之上,使得它可以以基本一致的方式應對不同的大數據處理場景,包括MapReduce,Streaming,SQL,Machine Learning以及Graph等。這即Matei Zaharia所謂的“設計一個通用的編程抽象(Unified Programming Abstraction)。這正是Spark這朵小火花讓人著迷的地方。要理解Spark,就需得理解RDD。
RDD是什么?
RDD,全稱為Resilient Distributed Datasets,是一個容錯的、并行的數據結構,可以讓用戶顯式地將數據存儲到磁盤和內存中,并能控制數據的分區。同時,RDD還提供了一組豐富的操作來操作這些數據。在這些操作中,諸如map、flatMap、filter等轉換操作實現了monad模式,很好地契合了Scala的集合操作。
除此之外,RDD還提供了諸如join、groupBy、reduceByKey等更為方便的操作(注意,reduceByKey是action,而非transformation),以支持常見的數據運算。 通常來講,針對數據處理有幾種常見模型,包括:Iterative Algorithms,Relational Queries,MapReduce,Stream Processing。例如Hadoop MapReduce采用了MapReduces模型,Storm則采用了Stream Processing模型。
RDD混合了這四種模型,使得Spark可以應用于各種大數據處理場景。RDD作為數據結構,本質上是一個只讀的分區記錄集合。一個RDD可以包含多個分區,每個分區就是一個dataset片段。RDD可以相互依賴。 如果RDD的每個分區最多只能被一個Child RDD的一個分區使用,則稱之為narrow dependency;若多個Child RDD分區都可以依賴,則稱之為wide dependency。不同的操作依據其特性,可能會產生不同的依賴。
例如map操作會產生narrow dependency,而join操作則產生wide dependency。Spark之所以將依賴分為narrow與wide,基于兩點原因。 首先,narrow dependencies可以支持在同一個cluster node上以管道形式執行多條命令,例如在執行了map后,緊接著執行filter。相反,wide dependencies需要所有的父分區都是可用的,可能還需要調用類似MapReduce之類的操作進行跨節點傳遞。 其次,則是從失敗恢復的角度考慮。
narrow dependencies的失敗恢復更有效,因為它只需要重新計算丟失的parent partition即可,而且可以并行地在不同節點進行重計算。而wide dependencies牽涉到RDD各級的多個Parent Partitions。下圖說明了narrow dependencies與wide dependencies之間的區別:
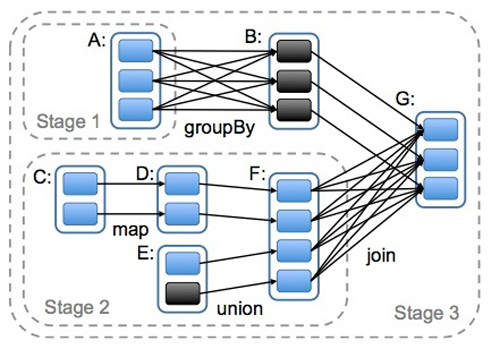
本圖來自Matei Zaharia撰寫的論文An Architecture for Fast and General Data Processing on Large Clusters。圖中,一個box代表一個RDD,一個帶陰影的矩形框代表一個partition。RDD如何保障數據處理效率?RDD提供了兩方面的特性persistence和patitioning,用戶可以通過persist與patitionBy函數來控制RDD的這兩個方面。RDD的分區特性與并行計算能力(RDD定義了parallerize函數),使得Spark可以更好地利用可伸縮的硬件資源。若將分區與持久化二者結合起來,就能更加高效地處理海量數據。 例如:
![]()
partitionBy函數需要接受一個Partitioner對象,如:
![]()
RDD本質上是一個內存數據集,在訪問RDD時,指針只會指向與操作相關的部分。例如存在一個面向列的數據結構,其中一個實現為Int的數組,另一個實現為Float的數組。如果只需要訪問Int字段,RDD的指針可以只訪問Int數組,避免了對整個數據結構的掃描。RDD將操作分為兩類:transformation與action。無論執行了多少次transformation操作,RDD都不會真正執行運算,只有當action操作被執行時,運算才會觸發。
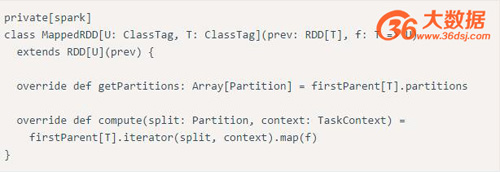
而在RDD的內部實現機制中,底層接口則是基于迭代器的,從而使得數據訪問變得更高效,也避免了大量中間結果對內存的消耗。 在實現時,RDD針對transformation操作,都提供了對應的繼承自RDD的類型,例如map操作會返回MappedRDD,而flatMap則返回FlatMappedRDD。當我們執行map或flatMap操作時,不過是將當前RDD對象傳遞給對應的RDD對象而已。 例如:
![]()
這些繼承自RDD的類都定義了compute函數。該函數會在action操作被調用時觸發,在函數內部是通過迭代器進行對應的轉換操作:
RDD對容錯的支持
支持容錯通常采用兩種方式: 數據復制或日志記錄。對于以數據為中心的系統而言,這兩種方式都非常昂貴,因為它需要跨集群網絡拷貝大量數據,畢竟帶寬的數據遠遠低于內存。RDD天生是支持容錯的。首先,它自身是一個不變的(immutable)數據集,其次,它能夠記住構建它的操作圖(Graph of Operation),因此當執行任務的Worker失敗時,完全可以通過操作圖獲得之前執行的操作,進行重新計算。
由于無需采用replication方式支持容錯,很好地降低了跨網絡的數據傳輸成本。不過,在某些場景下,Spark也需要利用記錄日志的方式來支持容錯。例如,在Spark Streaming中,針對數據進行update操作,或者調用Streaming提供的window操作時,就需要恢復執行過程的中間狀態。 此時,需要通過Spark提供的checkpoint機制,以支持操作能夠從checkpoint得到恢復。
針對RDD的wide dependency,最有效的容錯方式同樣還是采用checkpoint機制。不過,似乎Spark的***版本仍然沒有引入auto checkpointing機制。總結RDD是Spark的核心,也是整個Spark的架構基礎。 它的特性可以總結如下:
- 它是不變的數據結構存儲
- 它是支持跨集群的分布式數據結構
- 可以根據數據記錄的key對結構進行分區
- 提供了粗粒度的操作,且這些操作都支持分區
- 它將數據存儲在內存中,從而提供了低延遲性