中國開放政府數據的六個經典問題
愿不愿開放、能不能開放屬于政策層面的問題;能力夠不夠、體制機制如何保障,組織文化是否支撐屬于管理層面問題;數據好不好、數據質量控制、平臺體驗屬于技術層面的問題。這些都是中國開放數據的“一些經典問題”。
第17屆國際數字政府研究會議之“開放數據在中國”討論會在復旦大學舉辦。會上,復旦大學國際關系與公共事務學院副教授、數字與移動治理實驗室主任鄭磊作了主題為“中國開放政府數據的現狀和問題”的分享。
開放數據強調利用和再利用
鄭磊提出,所謂開放數據,具體而言就是要把開放進行到數據層,而不僅僅是經過加工分析后的信息層。
他指出,“開放”包含技術性開放和法律性開放,前者是指數據可以被機讀,可以被導入、下載和讀取,再被充分的利用和再利用,后者是指數據能夠不受限制地被明確允許商業、非商業的利用、再利用。“在技術和法律層面我們都滿足這個條件,才是開放。”他說。
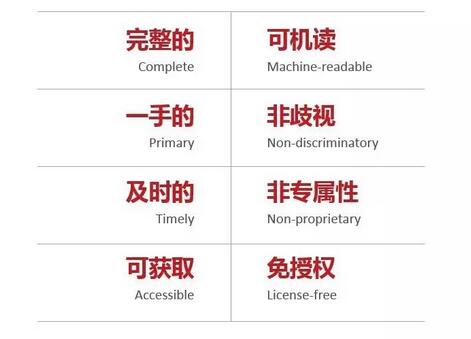
開放數據的特點
針對當下人們對開放數據與信息公開的混淆,鄭磊指出,首先,開放數據需要開放到數據層,而不僅限于信息層;其次,開放數據不僅為了保證公民的知情權,還希望數據可被利用和再利用,從而創造社會和經濟價值。
目前,上海、北京、無錫等地相繼建立開放數據平臺,它們究竟做得如何?在梳理全球約10種評估指標體系后,鄭磊團隊建立了一個中國開放數據的評估指標,希望借此評估這些開放數據平臺。
鄭磊介紹,這種從政府端進行的評估包括三部分:在基礎層,包括經濟、社會、組織、管理、人員能力等方面的準備;在平臺層,包括平臺做得如何、用戶體驗如何,獲取數據是否容易等;在基礎層、平臺層之上的數據層,是真正開放出來的“干貨”,包括開放數據的數量、格式、標準等。
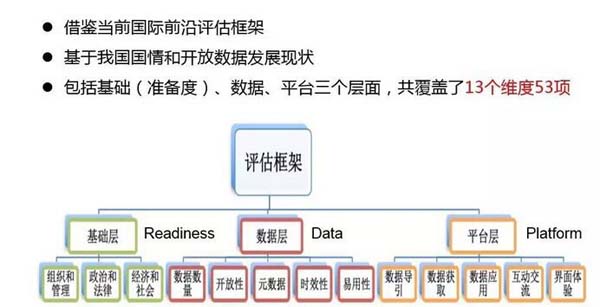
評價開放數據的三個層面
鄭磊補充道,國外的評估指標會評估供給端和需求端,但現在中國供給端才剛剛起步,需求端還沒有得到真正有價值的數據進行利用和產生結果,對需求端的評估也不容易開展,因此目前的這個評估框架還“不一定最***”,但能適用于當下的情況,它會隨著實踐的變化而變化。
真正的動態數據的比例僅為2%
中國開放數據做得如何?鄭磊團隊去年選取了北京、上海、武漢、無錫、湛江、寧波海曙、佛山南海、貴州等8個地方做了評估,今年正在對更多城市的開放數據平臺展開評估。
他們發現,各地的開放數總量和可機讀數據量相去甚遠。例如,截至今年1月,上海的開放數據總量達705個、可機讀數據量達691個,均列***,而很多城市雖然開放數據總量較高,但可機讀數據量卻只占很小比例。
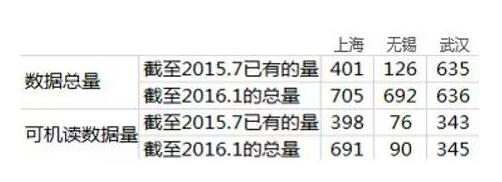
部分城市的開放數據數量
而在數據更新方面,這些平臺平均只有13.25%的數據被標注為動態數據,但實際更新頻率卻更低。2015年,這些被標明為動態的13.25%的數據中真正按承諾實現更新的比例僅為17.2%,所以實際上真正的動態數據只有2%。
鄭磊總結,目前中國開放數據的總體情況是:開放數據總量低、可機讀率低、少動態數據、未嚴格符合開放授權。
他介紹,目前開放數據的協議并沒有明確的保證,有的平臺只說現階段免費,以后是否免費并未明確。
數據是權力和利益
為什么中國開放數據現狀的不理想,鄭磊認為有六大原因。
***,愿不愿意開放?數據是權力和利益,各部門可能因此而不愿意開放。還有部門則認為沒有必要開放,覺得自己是專家,“數據分析自己***大,你們能玩出什么東西,你們不懂”。
第二,能不能開放?政府在開放數據的過程中會遇到的一個難題是,數據是否涉及國家秘密、商業秘密、個人隱私?這些原則都有,但沒有明確界定。
第三,能力夠不夠?著手開放數據工作后,能不能真正做出來?能否有體制、機制、人員能力、資金的保證?“這些部門愿不愿意把數據開放出來,用什么機制保證?包括激勵機制、更新機制、人員能力建設等,都非常難”。
第四,多一事不如少一事。鄭磊指出,這是風險規避性的政府組織文化問題,“能不做就不做,讓別人先去做,別人做得差不多自己再拷貝,而不是積主動探索和創新”。
“多一事不如少一事”是組織文化問題
第五,數據在哪里?鄭磊認為,這是個政府內部數據的碎片化問題。很多時候,人力、財力都投入了,但數據因政府內部的碎片化而分散,散落在各個部門,政府既不知道自己有什么數據,也經常找不到這個數據,也沒有數據清單,這就很難開放。
第六,數據好不好?有數據了,但是政府還不能確定數據的好壞。如果數據不好,那也不敢開放,開放后產生了負面的結果,政府是否需要承擔責任?這個是很現實的問題。鄭磊指出,政府當初采集這些數據是為了滿足內部需求,并非為了開放而采集,現在要開放出來還要花很多精力,更重要的是還不一定能保證數據質量。
鄭磊總結,上述六大原因之中,愿不愿開放、能不能開放屬于政策層面的問題;能力夠不夠、體制機制如何保障、組織文化是否支撐屬于管理層面問題;數據好不好、數據質量控制、平臺體驗屬于技術層面的問題。這些都是中國開放數據的“一些經典問題”。