如何借助GlusterFS構建存儲池
譯文【51CTO.com快譯】GlusterFS可存儲網絡上的數據,還可以用作云環境下的存儲后端。
不久之前,軟件定義存儲還是各大存儲解決方案廠商獨占的領域,如今卻可以用開源免費軟件來加以實施。另一個好處是,你有望獲得基于硬件的解決方案所沒有的額外功能。GlusterFS讓你得以構建一個可擴展、虛擬化的存儲池,它由常規存儲系統組成(這些存儲系統組成網絡RAID),并使用不同的方法來定義卷,描述數據如何分布在每個存儲系統上。
不管你選擇了哪一種類型的卷,GlusterFS都可以利用單個的存儲資源構建一個通用的存儲陣列,并通過單一命名空間提供給客戶(見圖1)。客戶還可以是使用GlusterFS服務器存儲后端用于虛擬系統的應用程序,比如云軟件。相比這種類型的其他解決方案,GlusterFS無需專用的元數據服務器在存儲池中查找文件。相反使用了一種哈希算法,讓任何存儲節點得以識別存儲池中的文件。這與其他存儲解決方案相比是一大優點,因為元數據服務器常常是瓶頸和單一故障點。
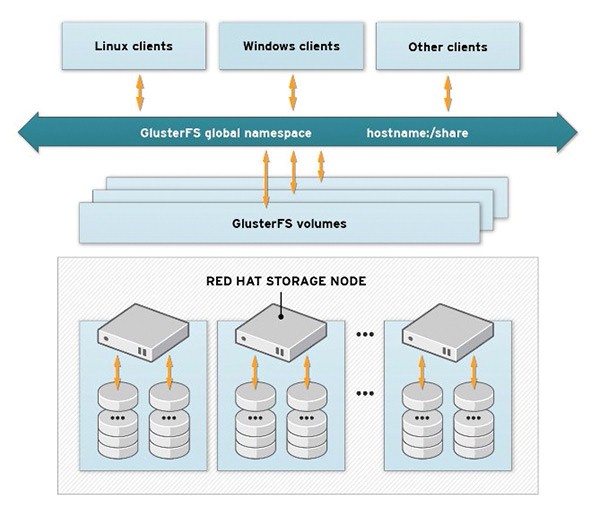
圖1:客戶系統通過單一命名空間,訪問所需的GlusterFS卷
如果你看一下GlusterFS的內部結構,就會驚訝地發現:文件系統實施在用戶空間里面,訪問通過用戶空間中的文件系統(FUSE)接口來進行。這樣一來,處理文件系統非常容易、非常靈活,不過代價是性能受到影響。然而,libgfapi庫能夠直接訪問文件系統。比如說,Qemu用它來存儲GlusterFS上虛擬系統的映像,沒必要經由FUSE掛載來繞行。
如前所述,文件系統是在可分布于多個系統上的卷上創建的。單個系統通過TCP/IP或InfiniBand遠程直接內存訪問(RDMA)加以連接。然后,通過原生的GlusterFS客戶軟件、通過網絡文件系統(NFS)或服務器消息塊(SMB)協議,就可以使用存儲卷。除了鏡像數據外,GlusterFS還可以使用轉換工具,將數據分布到單個存儲系統上。
對分布式數據和鏡像數據而言,最小的單位是文件本身;以條帶化(striping)為列,一個文件的每個部分分布在系統上。這種系統的擴展性良好,如果你需要管理大文件更是如此。這種模式下的性能幾乎隨著系統的數量呈線性增長。鏡像數據時,GlusterFS創建一個文件的多個副本。多種模式的數據還可以結合起來。比如說,結合分布式數據和鏡像數據讓你可以兼顧性能和數據安全性。
分散模式就好比是一種RAID 5配置,它是比較新的模式。為了獲得容錯和高可用性,你還可以通過異地復制,將存儲卷鏡像到遠程站點。如果災難發生,服務器在分布式存儲卷方面出現故障,就很容易恢復數據。
Gluster卷還可以加以擴展,可能立即擴展:為此,你只要為卷添加一個額外的brick。用Gluster專業術語來講,brick是存儲系統的目錄,卷是由這些目錄組成的。單一卷的brick通常但未必駐留在不同的系統上。為了擴大可信賴存儲池,你只要為現有的聯合體添加額外的服務器。
這里的例子基于Fedora 22,旨在為基于Qemu/KVM和libvirt虛擬化框架的虛擬系統提供后端存儲。Glusterfs軟件包包含在常規的Fedora軟件庫中,只要使用dnf軟件包管理器就可以安裝:
dnf install glusterfs glusterfs-cli glusterfs-server
除了安裝GlusterFS社區版外還有一個辦法:還可以向Linux發行版經銷商紅帽公司購買商用Gluster Storage產品。它隨帶典型的企業功能(比如,你可以訪問Linux發行版經銷商的支持服務)。
安裝GlusterFS
為了避免讓例子過于復雜,我的環境包括兩個系統。每個系統提供一個brick,它將在兩個系統之間復制。在這兩個系統上,glusterfs服務都由systemd來啟動(代碼片段1)。
代碼片段1
GlusterFS服務
- # systemctl start glusterd.service
- # systemctl status glusterd.service
- glusterd.service - GlusterFS, a clustered file-system server
- Loaded: loaded (/usr/lib/systemd/system/glusterd.service; disabled; vendor preset: disabled)
- Active: active (running) since Thu 2015-08-27 21:26:45 CEST; 2min 53s ago
- Process: 1424 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid (code=exited, status=0/SUCCESS)
- Main PID: 1425 (glusterd)
- CGroup: /system.slice/glusterd.service ??1425 /usr/sbin/glusterd -p /var/run/glusterd.pid
- Aug 27 21:26:45 gluster2.example.com systemd[1]: Starting GlusterFS, a clustered file-system server...
- Aug 27 21:26:45 gluster2.example.com systemd[1]: Started GlusterFS, a clustered file-system server.
在這兩臺計算機上,專用的塊設備掛載在/storage/下面。之后將用來創建GlusterFS卷的brick在該設備上設置。在這個例子中,每個系統只使用一個brick。然而,如果你之前將所有存儲系統添加到前面所述的可信賴存儲池,這才有可能實現。登錄到哪個存儲系統來創建可信賴存儲池沒有關系。在這個例子中,***個系統(gluster1)用于這個用途:
- # gluster peer probe gluster2
- Probe successful
本地系統自動屬于可信賴存儲池,它不需要添加上去。來自gluster peer status的輸出現在應該會將另一個系統標為兩個系統上的peer。下面這個命令在兩個存儲系統之間生成一個復制卷。在此之后需要啟用該卷:
- # gluster volume create gv0 replica gluster1:/storage/brick1/gv0/ gluster2:/storage/brick1/gv0/
- volume create: gv0: success: please start the volume to access data
- # gluster volume start gv0
- volume start: gv0: success
由于傳輸模式在默認情況下被設成TCP/IP,不需要指定它。如果你偏愛InfiniBand而非TCP/IP,只要在創建卷時指定rdma transport作為進一步的變量。這種方式創建的卷為你提供了額外的功能特性。比如說,你可以允許只從某個特定的網絡來訪問:
- # gluster volume set gv0 auth.allow 192.168.122.*
- volume set: success
此處(http://www.admin-magazine.com/Articles/Build-storage-pools-with-GlusterFS/(offset)/3#article_i2)大致介紹了所有可用的Gluster選項。安裝卷后,你可以輸入volume info命令,獲得詳細信息(見代碼片段2)。
代碼片段2
獲得卷的詳細信息
- # gluster volume info gv0
- Volume Name: gv0
- Type: Replicate
- Volume ID: 4f8d25a9-bbee-4e8c-a922-15a7f5a7673d
- Status: Started
- Number of Bricks: 1 x 2 = 2
- Transport-type: tcp
- Bricks:
- Brick1: gluster1:/storage/brick1/gv0
- Brick2: gluster2:/storage/brick1/gv0
- Options Reconfigured:
- auth.allow: 192.168.122.*
使用FUSE實現最快的客戶訪問
可以使用各種方法,以便最終訪問以這種方式創建的卷。經由FUSE的原生訪問提供了***性能,你也可以為卷創建一個NFS或SMB共享區,以便通過網絡來訪問。然而,我建議使用原生客戶軟件,不僅僅為了獲得更好的性能,還因為確保可以透明地訪問單個brick,不管用來掛載卷的存儲服務器是哪一臺。如果你想創建GlusterFS卷,通過NFS-Ganesha或CTDB,配置一臺具有高可用性的數據服務器,那么使用NFS或SMB值得關注。如果你按如下方式運行mount命令,就要用到原生客戶軟件:
- mount -t glusterfs gluster1:/gv0 /mnt/glusterfs/
為了提供***訪問卷的服務,往你的etc/fstab文件添加一個相應的行。眼下值得一提的是,使用哪種存儲系統來訪問無關重要,因為它只是用來讀取元數據,元數據表明了你的卷到底是如何組成的。你可以在這里找到為卷提供brick的所有系統。
擴展存儲池
GlusterFS讓用戶很容易調整現有的存儲池。比如說,如果你想為存儲池添加一個新的存儲系統,可以使用下列命令:
- gluster peer probe gluster3
- gluster volume add-brick replica 3 gv0 gluster3:/storage/brick1/gv0/
這里,gluster3系統被添加到存儲池,將現有的卷擴大一個brick。調用gluster卷信息應該會證實這一點:現在這個卷已有三個brick。視選擇的模式而定,你可能需要為卷添加額外的brick。比如說,分布式復制卷需要四個brick。
你可以從卷刪除brick,這個過程就跟添加brick來得一樣容易。如果不再需要某個存儲系統,可以從可信賴存儲池刪除它:
- gluster volume remove-brick gv0 gluster3:/storage/brick1/gv0/
- gluster peer detach gluster3
你為分布式卷添加brick或從分布式卷刪除brick后,需要重新排序數據,以體現brick數量發生變化的事實。為了啟動這個過程,使用這個命令:
- gluster volume rebalance gv0 start
使用參數status而不是start調用這個參數,為你提供了重組進度方面的詳細信息。
GlusterFS作為云存儲
由于良好性能和易于擴展,GlusterFS經常用作云環境的存儲解決方案。既可以部署在純粹基于libvirt的Qemu/KVM環境,也可以部署在多個KVM實例并行運行的環境。oVirt框架和紅帽的商用變種(Enterprise Virtualization)是兩個例子。它們提供了這一功能:將Gluster卷用作一段時間的存儲池或存儲域。Qemu可以直接訪問磁盤,沒必要經由FUSE掛載繞行,這歸功于GlusterFS版本3.4中集成了libgfapi庫。性能測試表明,直接訪問GlusterFS卷獲得了與直接訪問brick幾乎一樣的性能。
下面這個例子表明了如何為基于libvirt的KVM實例提供一個簡單的存儲池。至此,我假設虛擬機管理程序已安裝,只有之前創建的Gluster卷需要連接到該虛擬機管理程序。原則上來說,除了借助命令行工具可以實現外,這還可以借助圖形化virt-manager(虛擬機管理器)工具來實現(見圖2)。
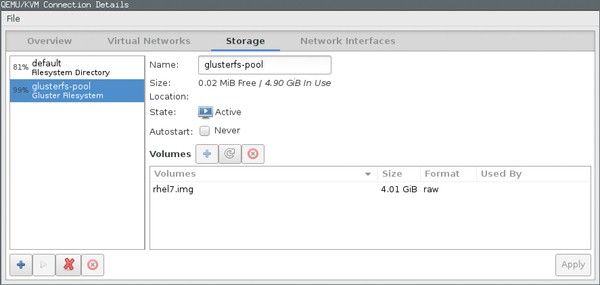
圖2:使用virt-manager圖形化工具,你可以創建GlusterFS存儲池,但眼下,你仍無法創建卷
代碼片段3顯示了一個XML文件,該文件描述了一個Gluster卷,然后把它添加到libvirt框架。你只要指定單一的存儲系統,同時指定配置卷時使用的卷名。下一步,創建一個新的libvirt存儲池,并啟用它:
- # virsh pool-define /tmp/gluster-storage.xml
- Pool glusterfs-pool defined from /tmp/gluster-storage.xml
- # virsh pool-start glusterfs-pool
- Pool glusterfs-pool started
代碼片段3
池定義
- <pool type='gluster'>
- <name>glusterfs-pool</name>
- <source>
- <host name='192.168.122.191'/>
- <dir path='/'/>
- <name>gv0</name>
- </source>
- </pool>
如果這一步行,可以輸入virsh pool-list,即可顯示本地虛擬機管理程序上的現有存儲池的概況信息:
- # virsh pool-list --all
Name State Autostart
------------------------------------------------
default active yes
glusterfs-pool active no
卷可以分配給這個存儲池里面的虛擬機。遺憾的是,截至本文截稿時,libvirt并不允許你在GlusterFS池里面創建卷,所以需要手動創建卷(見圖2)。下面這個命令在虛擬機管理程序上創建一個4GB大小的卷,用于安裝紅帽企業級Linux系統:
qemu-img create gluster://192.168.122.191/gv0/rhel7.img 4G
IP地址對應于可信賴存儲池里面的***個存儲系統,GlusterFS卷之前在該存儲池里面創建。virsh vol-list命令顯示卷已正確創建:
- # virsh vol-list glusterfs-pool
Name Path
---------------------------------------------------
rhel7.img gluster://192.168.122.191/gv0/rhel7.img
***,你可以使用virt-manager或virt-install命令行工具,創建所需的虛擬系統,并定義剛設置為存儲后端的那個卷。在GlusterFS卷上安裝虛擬系統的一個很簡單的例子看起來就像這樣:
- # virt-install --name rhel7 --memory 4096 --disk vol=glusterfs-pool/rhel7.img,bus=virtio --location ftp://192.168.122.1/pub/products/rhel7/
當然,你需要相應修改針對virt-install的調用。這里目的只是顯示如何可以把GlusterFS卷用作安裝系統的后端。
***,還要注意GlusterFS版本3.3帶來了另一個創新,那就是統一文件和對象(UFO)轉換工具,它讓文件系統能夠將POSIX文件處理成對象,反之亦然。在OpenStack環境下,文件系統是內置的OpenStack存儲組件Swift的名副其實的替代者,因為它支持所有的OpenStack存儲協議(文件、塊和對象)。
結束語
GlusterFS可以基于免費軟件和商用硬件,構建可橫向擴展的存儲系統。管理員可以在數據安全和性能之間作一選擇,也可以兩者兼顧。
原文標題:Build storage pools with GlusterFS,作者:Thorsten Scherf
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】