如何不必多掏錢,就能將數據庫的速度提升200倍?
譯文【51CTO.com快譯】這年頭幾乎每個人都在這樣那樣抱怨性能。數據庫管理員和程序員不斷發現自己處于這種情形:服務器遇到了瓶頸,或者查詢起來沒完沒了,這種情況并不少見。這種郁悶對我們所有人來說司空見慣了,解決方法不一。
最常見的一幕就是看一眼查詢后,責怪程序員在查詢方面沒有做得更好。也許他們原本可以使用合適的索引或物化視圖,或者干脆以一種更好的方法重寫查詢。而有時候,如果貴公司使用云服務,你可能要多啟用幾個節點。在其他情況下,如果服務器被太多慢騰騰的查詢搞得不堪重負,你可能要為不同的查詢設置不同的優先級,那樣至少比較緊迫的查詢(比如***執行官的查詢)更快地完成。如果數據庫不支持優先級隊列,管理員甚至會取消你的查詢,騰出一些資源,用于更緊迫的查詢。
不管你遇到過上述哪種情況,可能熟悉這種痛苦的經歷:不得不等待慢騰騰的查詢,或者購買更多的云實例,或者購買更快速、更龐大的服務器。大多數人熟悉傳統數據庫調整和查詢優化方法。這些方法有利也有弊。所以,我們在這里不會談論那些方法。我們在本文中是要談論更新穎的方法,它們不大為人所知,但在許多情況下確實可以有機會大大提升性能,并節省成本。
首先,不妨考慮這些場景:
場景1(探索性分析)——你是名分析員,要對數據進行交叉分析,尋找洞察力和模式,或者測試針對你的公司、客戶或服務所作的不同假設。在這種情況下,你通常不知道自己究竟會看到什么。你運行查詢,查看結果,然后決定是否需要運行不同的查詢。換句話說,你執行一系列探索性即席查詢,直至找到所需的結果。你運行的查詢中只有一些會用來填充公司報表、填寫表單,或者為客戶生成圖形。但每當你提交查詢,可能要等幾分鐘才能得到答案,時間的長短要看數據大小及集群中其他并行查詢的數量。等待過程中,你通常無所事事,無法決定下一個查詢,因為這取決于你仍在等待執行完畢的前一個查詢的輸出結果!
解決辦法:等待過程中,你可以立即看到“幾乎***”的答案。我這里所說的“幾乎***”的答案是啥意思?不妨比較下面這兩張圖。
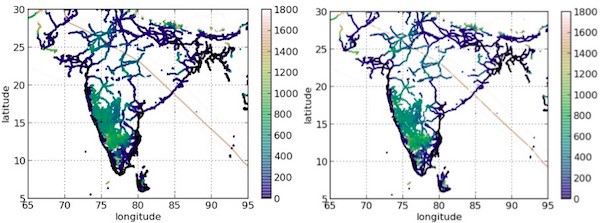
這些是同一款商業智能工具在運行從后端數據庫裝入數據的查詢后的輸出結果。由于使用全部10億個數據點,右邊這張圖耗時71分鐘才完成,而左邊這張圖只使用100萬個數據點,只花了3秒鐘就完成!當然,左邊這張圖相比右邊的***版本有點模糊。但要想一想:這么做值不值得?不用等待71分鐘,你立即可以獲得幾乎一樣的答案,然后決定是否想再等71分鐘獲得完整的答案,還是不等了,去做其他事情!
這肯定不是一個新想法!實際上,所有的Web瀏覽器已經在這么做。下次你試圖在瀏覽器上加載高分辨率圖像時,注意Web瀏覽器如何先試圖加載和顯示一個模糊的圖像,圖像逐漸變得越來越清晰。但是將同樣的原則運用于數據庫和SQL查詢處理卻鮮為人知。
于是,現在你可能有幾個問題:我們實際上如何獲得這種提速?即便你的數據分布呈偏態,這一招管用嗎?你仍看到異常數據?你需要使用特定的數據庫來享用速度和準確性之間這種類型的取舍嗎?我會在文章末尾回答所有這些問題,但我先說說另外幾個場景,你可能發覺同樣這個想法很有吸引力:立即見到準確性達到99.9%的結果,但速度要快200倍!
場景2(超載集群)——與如今的大多數數據庫用戶一樣,你可能沒有一個集群專門供自己使用。換句話說,你與你的團隊共享集群,甚至共享其他報表和商業智能工具。這些工具對同一個共享的數據庫資源池執行SQL查詢。如果這些共享的集群超載,實際上就會發生下面三種情況中的一種:
A.全面沮喪。你什么都沒做,任由每個人遭受一樣的痛苦。換句話說,一旦數據庫查詢積壓,CPU核心處于滿載狀態,沒人能夠足夠快地完成查詢。
B.局部沮喪。你做得比較巧妙,終止或暫停優先級較低的查詢,讓更緊迫的查詢(比如你經理的那些查詢)先完成。換句話說,你確保幾個更重要的人滿意,但是讓其他人很生氣!
C.如果這種情況頻繁發生,可能要購買更多更大的服務器,或者遷移到云端,按需要啟用更多的節點。當然,這種方案要花一定的費用,也不方便。另外,它也通常不是短期的解決辦法。
大多數人沒有認識到的一點是,還有第四種方法比前面兩種方法更好,而且不像第三方方法,也不要你花錢。那么這種方法是什么呢?第四種方法如下:
為低優先級查詢返回99.9%準確的答案,為其余查詢返回100%準確的答案!這之所以可行,是由于按照統計定律,你只要使用0.1%的數據和處理,通常就能獲得99.9%準確的答案。這就是為什么犧牲0.1%的準確性意味著,實際上速度可以提升100倍至200倍。我知道沒人想要湊合著使用99.9%的準確性,但是你需要考慮其他的選擇:終止查詢,被列入長長的等待名單,或者無所事事,等待查詢完成。正如我在場景1下提到的那樣,在許多情況下,你仍可以獲得完整的答案,在等待完整答案的同時就使用99.9%準確的答案。我會在文章末尾回過來探討“如何實現”的問題。不過眼下,記住:99.9%的準確性并不意味著你錯失0.1%的輸出結果。通常你仍看到一切,但是實際數字可能偏差0.1%,這意味著在大多數情況下,你甚至看不出區別所在,除非你確實瞇著眼在打量。比較這兩個圖:
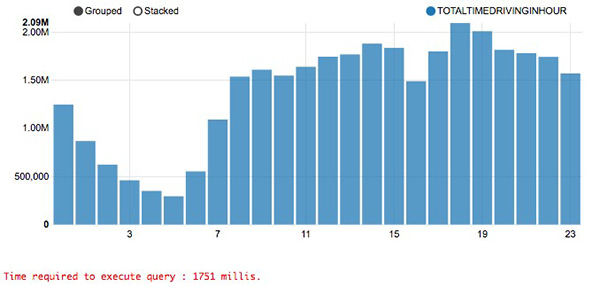
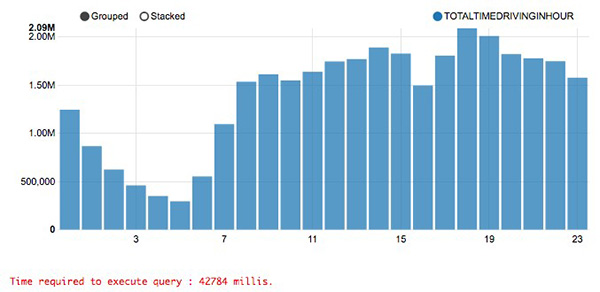
這些是使用著名的紐約市出租車數據集,詢問打車到鬧市區所用總時間的查詢輸出。
你能區別哪個是100%準確的答案,哪個是99.9%準確的答案嗎?在大多數人看來,這兩個一樣。但是上面那個查詢只花了1.7秒,而下面這個查詢卻花了42.7秒。這意味著,若犧牲0.1%的準確性,你的CPU時間可以節省25倍!不妨談論***一種場景,然后我會告訴你“如何實現”這部分。
場景3(機器學習和數據科學)——如果你是機器學習專家或數據科學家,會常常發現要訓練統計模型、調整參數,或者做一些特征選擇和工程。這方面最常讓人沮喪的問題之一是,你需要嘗試大量的參數或特性,而訓練機器學習模型要花很長時間。集群不斷忙于訓練和測試不同的模型,這就限制了數據科學家可以試用的一組不同模型和參數,或者至少減慢了這個過程。
在許多應用中,你不需要完全準確的答案,就能做出相當合理的決策。A/B測試、根源分析、特征選擇、可視化、噪聲數據或值缺失的數據庫都屬于這種情形。只有你是計費部門的人,才不想要這么做!
我可能會寫另一篇文章來介紹如何加快參數調整或特征選擇。
但是我們“如何”才能讓查詢加快200倍,但又只犧牲一點極小的準確性?
答案在于一種名為近似查詢處理(簡稱AQP)的技術。有不同的方法來實現AQP,但是最簡單的辦法是使用表的隨機樣本。結果是,如果你的數據呈偏態,你不想使用隨機樣本,因為這會錯失可能存在于原始表中的大多數異常數據和罕見項。所以,實際上更常見的是一種名為“分層樣本”的樣本。分層樣本是什么?不妨看看下面這張圖:
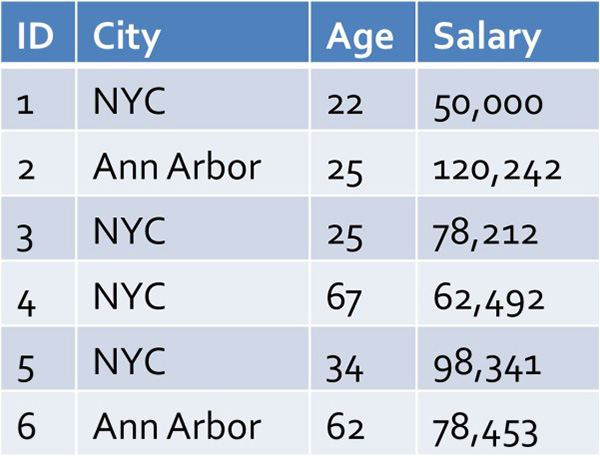
假設你想對這個表運行下列查詢:
SELECT avg(salary) FROM table WHERE city = ‘Ann Arbor’
當然你可以運行這個查詢,但是如果這個表有數億行,或者它跨多個機器來分區,可能要好幾分鐘才能完成。相反,你可以決定只對表的隨機(即統一)樣本運行查詢,比如說:
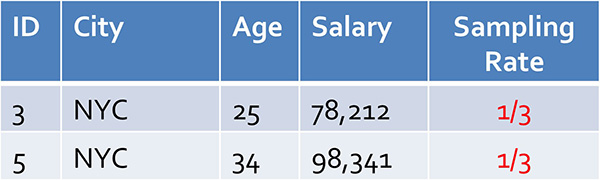
正如你所見,由于Ann Arbor元組相比原始表中的NYC元組很罕見,你很可能在樣本表中很少看到Ann Arbor或根本就看不到。相反,分層樣本會先根據City對表進行分層(即分區),然后隨機采樣顯示每個城市的行:
ID City Age Salary Sampling Rate
3 NYC 67 62,492 1/4
***nn Arbor 25 120,242 1/2
結果發現,不用深入分析統計數據,諸如此類的分層樣本會確保:通過處理一小部分的原始元組,你就能獲得非常高的準確性。
現在,下一個問題是如何創建這些樣本?又如何衡量準確性?有自動方法可以這么做。市面上有幾款產品,可以用來隱藏這種復雜性,那樣你只要摁一下按鈕,它們就會幫你從頭搞到尾,以極快地速度返回答案,有一些甚至為你提供旋鈕,只要轉動旋鈕,就可以決定想要多高的準確性以換取多快的提速。
BlinkDB / G-OLA
雖然外面有許多AQP方案,但是BlinkDB可能是***個成為開源項目的分布式(大規模并行)AQP引擎。本著完全披露的精神,我參與這個項目,所以我在這里可能有偏見,因為我確實很喜歡BlinkDB的方法,我認為它確實影響了后面介紹的許多學術方案和行業方案。Databricks(商業化Apache Spark的公司)在繼續開展BlinkDB方面的工作。Databricks不久前宣布了BlinkDB的擴展方案,將逐步完善其查詢答案,直至用戶滿意為止。這個擴展方案名為G-OLA。G-OLA之前從未公開發布過,BlinkDB有好長時間沒有更新了。
SnappyData
SnappyData是一種開源內存混合分析平臺,它在一個引擎中提供了OLTP、OLAP和數據流(Streaming)。數據庫引擎本身是通過擴展Apache Spark而構建的(因而它與Spark全面兼容)。內存核心還通過精選的分層采樣及其他概率結構提供了AQP。查詢語法類似BlinkDB,這讓用戶可以指定所需的準確性。這意味著你可以把準確性當作可調節撥盤。比如,如果你想要準確答案(這是默認行為),可以要求100%的準確性;但如果想要快速的答案,也可以在一秒左右的時間內獲得99%準確性的答案。在我看來,SnappyData的一大優點是,它使用精選的分層樣本。這意味著,你可以在幾秒內運行分析查詢,即便是在查詢數TB的數據,在筆記本電腦上運行,或者在共享集群中運行(有另外眾多并行查詢)。它還內置了支持數據流的功能,這讓你可以構建樣本,并且實時更新樣本,以響應入站數據流。
SnappyData的另一個出色功能是,它隨帶許多高級用戶接口,這意味著你不需要精通數據統計,就可以使用其AQP功能。比如,現在它有一種免費的云服務iSight,它使用Apache Zeppelin作為前端,以便在后臺運行完整查詢的同時,立即顯示查詢響應。
Presto
Facebook的Presto有一項試驗功能,可以近似處理基本的聚集查詢。我其實不知道***版本是不是擁有這項功能,但缺點是,你不得不使用不同的語法(即修改SQL查詢),那樣才能調用那些近似聚集功能。如果你有現有的商業智能工具或應用軟件并不使用這一種特別的語法,那很麻煩,因為它們無法得益于潛在的速度提升,除非對它們重寫,以便可以使用這種新的語法。
InfoBright
InfoBright提供了近似查詢功能(名為IAQ)。不像其他系統,IAQ根本就不使用樣本。遺憾的是,近似功能如何工作,它們提供什么樣的準確性保證方面公布的細節不多,不過在看了其博客后,我認為他們在構建底層數據的模型,并使用那些模型來回答查詢,而不是使用樣本。我也不是很了解IAQ,因為它不是開源,我在其官方網站上也找不到許多詳細信息,不過聽起來它像是一種值得關注的方法。
ABS
分析引導系統(ABS)是另一種近似查詢引擎,它使用樣本和高效的統計方法,以估計誤差。***代碼有點過時了,只適用于Apache Hive的早期版本。這個項目目前不活躍。
Verdict
Verdict是一種中間件,介于你的應用程序或商業智能工具與后端SQL數據庫之間。你只要對現有數據庫執行與以前一樣的查詢,立即就能獲得近似的答案。原則上,可以將Verdict與任何SQL數據庫結合使用,這意味著你不會受制于任何特定的數據庫管理系統(DBMS)。但目前,它只隨帶面向Spark SQL、Hive和Impala的驅動程序。優點在于,它是通用的,可以與任何SQL數據庫兼容,而且是開源的;缺點是由于它是中間件,可能不如InfoBright或SnappyData等一些商用解決方案來得高效。
Oracle 12C
Oracle 12C推出了approximate count distinct和近似百分比功能。這些近似聚集提升了性能,計算時少占用內存。Oracle 12C還提供了物化視圖支持,那樣用戶甚至可以預先計算近似聚集。雖然近似百分比和count distinct查詢大有用處,實際上也很常見,但是并不廣泛支持其他類型的查詢。但是考慮到Oracle的龐大用戶群,連這些有限的功能也會讓許多用戶從中得益。不過,據我所知,其他許多數據庫廠商長期支持approximate count distinct查詢(比如使用HyperLogLog算法)。
原文標題:How To Make Your Database 200x Faster Without Having To Pay More?,作者:Barzan Mozafari
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】