做Data Mining,其實大部分時間都花在清洗數(shù)據(jù)
- 前言:很多初學(xué)的朋友對大數(shù)據(jù)挖掘第一直觀的印象,都只是業(yè)務(wù)模型,以及組成模型背后的各種算法原理。往往忽視了整個業(yè)務(wù)場景建模過程中,看似最普通,卻又最精髓的特征數(shù)據(jù)清洗。可謂是平平無奇,卻又一掌定乾坤,稍有閃失,足以功虧一簣。
大數(shù)據(jù)圈里的一位掃地僧
說明:這篇文章很早就想寫了,但是切入點一直拿捏不準(zhǔn),要講的內(nèi)容比較大眾化,卻又是重中之重。
一、數(shù)據(jù)清洗的那些事
構(gòu)建業(yè)務(wù)模型,在確定特征向量以后,都需要準(zhǔn)備特征數(shù)據(jù)在線下進(jìn)行訓(xùn)練、驗證和測試。同樣,部署發(fā)布離線場景模型,也需要每天定時跑P加工模型特征表。
而這一切要做的事,都離不開數(shù)據(jù)清洗,業(yè)內(nèi)話來說,也就是ETL處理(抽取Extract、轉(zhuǎn)換Transform、加載Load),三大法寶。

來自于百度百科
在大數(shù)據(jù)圈里和圈外,很多朋友都整理過數(shù)據(jù),我們這里稱為清洗數(shù)據(jù)。
不管你是叱咤風(fēng)云的Excel大牛,還是玩轉(zhuǎn)SQL的數(shù)據(jù)庫的能人,甚至是專注HQL開發(fā)ETL工程師,以及用MapReduce\Scala語言處理復(fù)雜數(shù)據(jù)的程序猿。(也許你就是小白一個)
我想說的是,解決問題的技術(shù)有高低,但是解決問題的初衷只有一個——把雜亂的數(shù)據(jù)清洗干凈,讓業(yè)務(wù)模型能夠輸入高質(zhì)量的數(shù)據(jù)源。
不過,既然做的是大數(shù)據(jù)挖掘,面對的至少是G級別的數(shù)據(jù)量(包括用戶基本數(shù)據(jù)、行為數(shù)據(jù)、交易數(shù)據(jù)、資金流數(shù)據(jù)以及第三方數(shù)據(jù)等等)。那么選擇正確的方式來清洗特征數(shù)據(jù)就極為重要,除了讓你事半功倍,還至少能夠保證你在方案上是可行的。
你可別告訴我,你仍然選擇用Excel,那我選擇狗帶。
二、大數(shù)據(jù)的必殺技
在大數(shù)據(jù)生態(tài)圈里,有著很多開源的數(shù)據(jù)ETL工具,每一種都私下嘗嘗鮮也可以。但是對于一個公司內(nèi)部來說,穩(wěn)定性、安全性和成本都是必須考慮的。
就拿Spark Hive和Hive來說,同樣是在Yarn上來跑P,而且替換任務(wù)的執(zhí)行引擎也很方便。

修改任務(wù)執(zhí)行引擎
的確,Spark的大多數(shù)任務(wù)都會比MapReduce執(zhí)行效率要快差不多1/3時間。但是,Spark對內(nèi)存的消耗是很大的,在程序運(yùn)行期間,每個節(jié)點的負(fù)載都很高,隊列資源消耗很多。因此,我每次提交Spark離線模型跑任務(wù)時,都必須設(shè)置下面的參數(shù),防止占用完集群所有資源。
spark-submit --master yarn-cluster --driver-memory 5g --executor-memory 2g --num-executors 20
其中:
- driver-memory是用于設(shè)置Driver進(jìn)程的內(nèi)存,一般不設(shè)置,或者1G。我這里調(diào)整到5G是因為RDD的數(shù)據(jù)全部拉取到Driver上進(jìn)行處理,那要確保Driver的內(nèi)存足夠大,否則會出現(xiàn)OOM內(nèi)存溢出。
- executor-memory是用于設(shè)置每個Executor進(jìn)程的內(nèi)存。Executor內(nèi)存的大小決定了Spark作業(yè)的性能。
- num-executors是用于設(shè)置Spark作業(yè)總共要用多少個Executor進(jìn)程來執(zhí)行。這個參數(shù)如果不設(shè)置,默認(rèn)啟動少量的Executor進(jìn)程,會很大程度影響任務(wù)執(zhí)行效率。
單獨(dú)的提交Spark任務(wù),優(yōu)化參數(shù)還可以解決大部分運(yùn)行問題。但是完全替換每天跑P加工報表的執(zhí)行引擎,從MapReduce到Spark,總會遇到不少意想不到的問題。對于一個大數(shù)據(jù)部門而言,另可效率有所延遲,但是數(shù)據(jù)穩(wěn)定性是重中之重。

Spark運(yùn)行Stage
所以,大部分?jǐn)?shù)據(jù)處理,甚至是業(yè)務(wù)場景模型每天的數(shù)據(jù)清洗加工,都會優(yōu)先考慮Hive基于MapRedcue的執(zhí)行引擎,少部分會單獨(dú)使用編寫MapReduce、Spark程序來進(jìn)行復(fù)雜處理。
三、實踐中的數(shù)據(jù)清洗
這節(jié)要介紹的內(nèi)容其實很多,單獨(dú)對于Hive這方面,就包括執(zhí)行計劃、常用寫法、內(nèi)置函數(shù)、一些自定義函數(shù),以及優(yōu)化策略等等。
幸運(yùn)的是,這方面資源在網(wǎng)上很全,這是一個值得欣慰的點,基本遇到的大多數(shù)問題都能夠搜到滿意答案。
因此,文章這個版塊主要順著這條主線來——(我在大數(shù)據(jù)挖掘?qū)嵺`中所做的模型特征清洗),這樣對于大數(shù)據(jù)挖掘的朋友們來說,更具有針對性。
3.1 知曉數(shù)據(jù)源
(這里不擴(kuò)展數(shù)據(jù)源的抽取和行為數(shù)據(jù)的埋點)
大數(shù)據(jù)平臺的數(shù)據(jù)源集中來源于三個方面,按比重大小來排序:
60%來源于關(guān)系數(shù)據(jù)庫的同步遷移: 大多數(shù)公司都是采用MySQL和Oracle,就拿互聯(lián)網(wǎng)金融平臺來說,這些數(shù)據(jù)大部分是用戶基本信息,交易數(shù)據(jù)以及資金數(shù)據(jù)。
30%來源于平臺埋點數(shù)據(jù)的采集:渠道有PC、Wap、安卓和IOS,通過客戶端產(chǎn)生請求,經(jīng)過Netty服務(wù)器處理,再進(jìn)Kafka接受數(shù)據(jù)并解碼,最后到Spark Streaming劃分為離線和實時清洗。
10%來源于第三方數(shù)據(jù):做互聯(lián)網(wǎng)金融都會整合第三方數(shù)據(jù)源,大體有工商、快消、車房、電商交易、銀行、運(yùn)營商等等,有些是通過正規(guī)渠道來購買(已脫敏),大部分?jǐn)?shù)據(jù)來源于黑市(未脫敏)。這個市場魚龍混雜、臭氣熏天,很多真實數(shù)據(jù)被注入了污水,在這基礎(chǔ)上建立的模型可信度往往很差。
得數(shù)據(jù),得天下?
3.2 業(yè)務(wù)場景模型的背景
看過我以前文章集的朋友都知道一點,我致力于做大數(shù)據(jù)產(chǎn)品。
在之前開發(fā)數(shù)據(jù)產(chǎn)品的過程中,有一次規(guī)劃了一個頁面——用戶關(guān)系網(wǎng)絡(luò),底層是引用了一個組合模型。
簡單來說是對用戶群體細(xì)分,判斷用戶屬于那一類別的羊毛黨群體,再結(jié)合業(yè)務(wù)運(yùn)營中的彈性因子去綜合評估用戶的風(fēng)險。
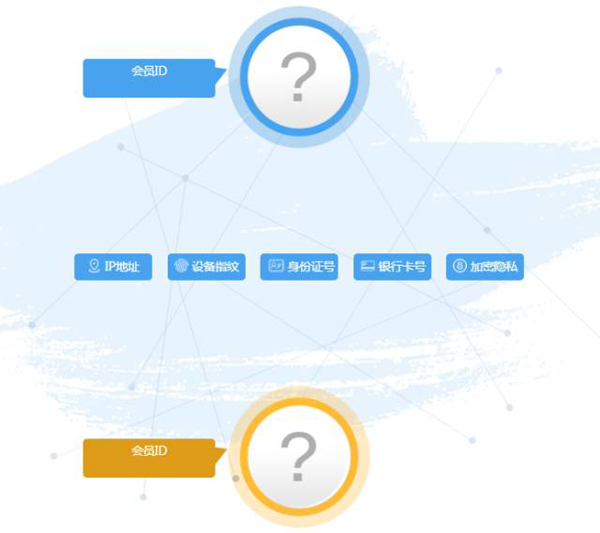
截圖的原型Demo
大家看到這幅圖會有什么想法?
簡單來說,原型展示的是分析兩個用戶之間在很多維度方面的關(guān)聯(lián)度
當(dāng)時這個功能在后端開發(fā)過程中對于特征數(shù)據(jù)的處理花了很多時間,有一部分是數(shù)據(jù)倉庫工具HQL所不能解決的,而且還需要考慮完整頁面(截圖只是其中一部分)查詢的響應(yīng)時間,這就得預(yù)先標(biāo)準(zhǔn)化業(yè)務(wù)模型的輸出結(jié)果。
我可以簡單描述下需求場景:
- 拿IP地址來說,在最近30天范圍內(nèi),用戶使用互聯(lián)網(wǎng)金融平臺,不管是PC端,還是無線端,每個用戶每個月都會產(chǎn)生很多IP數(shù)據(jù)集。
- 對于擁有千萬級別用戶量的平臺,肯定會出現(xiàn)這樣的場景——很多用戶在最近一個月內(nèi)都使用過相同的IP地址,而且數(shù)量有多有少。
- 對某個用戶來說,他就好像是一個雪花中的焦點,他使用過的IP地址就像雪花一樣圍繞著他。而每個IP地址都曾被很多用戶使用過。
簡單來說,IP地址只是一個媒介,連接著不同用戶。——你中有我,我中有你。

雪花狀
有了上面的背景描述,那么就需要每個讀者都去思考下這三個問題:
問題一、如何先通過某個用戶最近30天的IP列表去找到使用相同IP頻數(shù)最多的那一批用戶列表呢?
問題二、如何結(jié)合關(guān)系網(wǎng)絡(luò)的每個維度(IP、設(shè)備指紋、身份證、銀行卡和加密隱私等等),去挖掘與該用戶關(guān)聯(lián)度最高的那一批用戶列表?
問題三、如何對接產(chǎn)品標(biāo)準(zhǔn)化模型輸出,讓頁面查詢的效應(yīng)時間變得更快些?
思考就像吃大理核桃般,總是那么耐人尋味。
3.3 學(xué)會用Hive解決70%的數(shù)據(jù)清洗
對于70%的數(shù)據(jù)清洗都可以使用Hive來完美解決,而且網(wǎng)絡(luò)參考資料也很全,所以大多數(shù)場景我都推薦用它來清洗。——高效、穩(wěn)定

一只小蜜蜂呀,飛到花叢中
不過在使用過程中,我有兩點建議送給大家,就當(dāng)作雞年禮物吧。
第一點建議:要學(xué)會顧全大局,不要急于求成,學(xué)會把復(fù)雜的查詢拆開寫,多考慮集群整個資源總量和并發(fā)任務(wù)數(shù)。
第二點建議:心要細(xì),在線下做好充足的測試,確保安全性、邏輯正確和執(zhí)行效率才能上線。
禮物也送了,繼續(xù)介紹
對于上述的用戶關(guān)系網(wǎng)絡(luò)場景,這里舉IP維度來實踐下,如何利用Hive進(jìn)行數(shù)據(jù)清洗。
下面是用戶行為日志表的用戶、IP地址和時間數(shù)據(jù)結(jié)構(gòu)。

用戶、IP和時間
回到上面的第一個思考,如何先通過某個用戶最近30天的IP列表去找到使用相同IP頻數(shù)最多的那一批用戶列表呢?
我當(dāng)時采取了兩個步驟。
步驟一:清洗最近30天所有IP對應(yīng)的用戶列表,并去重用戶

清洗IP對應(yīng)的用戶列表
這里解釋三個內(nèi)置函數(shù)concat_ws、collect_set和cast,先更了解必須去親自實踐:
- concat_ws,它是用來分隔符字符串連接函數(shù)。
- collect_set,它是用來將一列多行轉(zhuǎn)換成一行多列,并去重用戶。
- cast,它是用來轉(zhuǎn)換字段數(shù)據(jù)類型。
果然很方便吧,下面是第一個步驟的執(zhí)行結(jié)果。

IP馬賽克
步驟二:清洗用戶在IP媒介下,所有關(guān)聯(lián)的用戶集列表

清洗用戶在IP媒介下的關(guān)聯(lián)用戶集
最終對于IP媒介清洗的數(shù)據(jù)效果如下所示:
![]()
用戶ID、IP關(guān)聯(lián)的用戶集
同理對于其他維度的媒介方法一樣,到這一步,算是完成Hive階段的初步清洗,是不是很高效。
![]()
最終結(jié)果的樣式
但是對于分析用戶細(xì)分來說,還需要借助MapReduce,或者Scala來深層次處理特征數(shù)據(jù)。
3.4 使用Scala來清洗特殊的數(shù)據(jù)
對于使用Spark框架來清洗數(shù)據(jù),我一般都是處于下面兩個原因:
- 常規(guī)的HQL解決不了
- 用簡潔的代碼高效計算,也就是考慮開發(fā)成本和執(zhí)行效率
對于部署本機(jī)的大數(shù)據(jù)挖掘環(huán)境,可以查看這兩篇文章來實踐動手下:
- 《簡單之極,搭建屬于自己的Data Mining環(huán)境(Spark版本)》
- 《深入淺出,在Data Mining環(huán)境下Code第一個算法(Spark版本)》
工欲善其事,必先利其器。有了這么好的利器,處理復(fù)雜的特征數(shù)據(jù),那都是手到擒來。
借助于Hive清洗處理后的源數(shù)據(jù),我們繼續(xù)回到第二個思考——如何結(jié)合關(guān)系網(wǎng)絡(luò)的每個維度,去初步挖掘與該用戶關(guān)聯(lián)度最高的那一批用戶列表?
看到這個問題,又產(chǎn)生了這幾個思考:
- 目前有五個維度,以后可能還會更多,純手工顯然不可能,再使用Hive好像也比較困難。
- 每個維度的關(guān)聯(lián)用戶量也不少,所以基本每個用戶每行數(shù)據(jù)的處理采用單機(jī)串行的程序去處理顯然很緩慢。不過每行的處理是獨(dú)立性的。
- 同一個關(guān)聯(lián)用戶會在同一個維度,以及每一個維度出現(xiàn)多次,還需要進(jìn)行累計。
如果才剛剛處理大數(shù)據(jù)挖掘,遇到這樣的問題的確很費(fèi)神,就連你們常用的Python和R估計也難拯救你們。但是如果實戰(zhàn)比較多,這樣的獨(dú)立任務(wù),完全可以并發(fā)到每臺計算節(jié)點上去每行單獨(dú)處理,而我們只需要在處理每行時,單獨(dú)調(diào)用清洗方法即可。
這里我優(yōu)先推薦使用Spark來清洗處理(后面給一個MapReduce的邏輯),整個核心過程主要有三個板塊
- 預(yù)處理,對所有關(guān)聯(lián)用戶去重,并統(tǒng)計每個關(guān)聯(lián)用戶在每個維度的累計次數(shù)
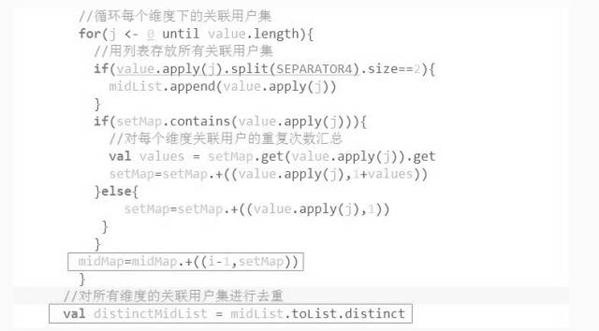
核心就在這兩處
- 評分,循環(huán)上述關(guān)聯(lián)用戶集,給關(guān)聯(lián)度打一個分
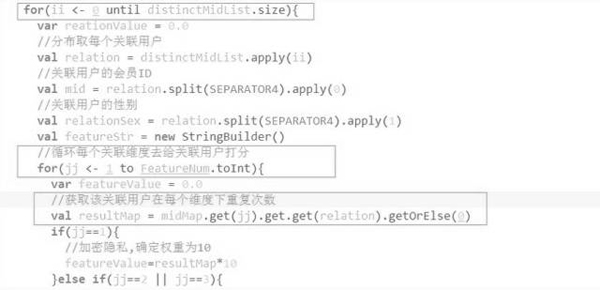
核心在這三處
- 標(biāo)準(zhǔn)化清洗處理,用戶關(guān)聯(lián)用json串拼接
![]()
第二個階段清洗結(jié)果
得到上面清洗結(jié)果,我們才能更好的作為模型的源數(shù)據(jù)輸出,感覺是不是很費(fèi)神,所以才印證了這句話——做Data Mining,其實大部分時間都花在清洗數(shù)據(jù)
3.5 附加分:使用MapReduce來清洗特殊的數(shù)據(jù)
針對上述的數(shù)據(jù)清洗,同樣可以MapReduce來單獨(dú)處理。只是開發(fā)效率和執(zhí)行效率有所影響。
當(dāng)然也不排除適用于MapReduce處理的復(fù)雜數(shù)據(jù)場景。
對于在本地Windows環(huán)境寫MapRecue代碼,可以借鑒上述文章中部署的數(shù)據(jù)挖掘環(huán)境,修改下Maven工程的pom.xml文件就可以了。
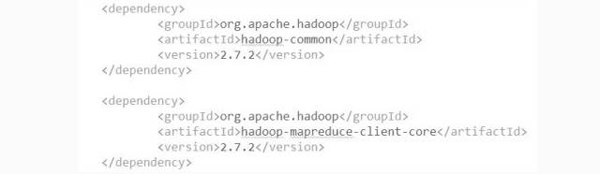
在pom.xml文件添加hadoop依賴
而我在以往做大數(shù)據(jù)挖掘的過程里,也有不少場景需要借助MR來處理,比如很早的一篇文章《一種新思想去解決大矩陣相乘》,甚至是大家比較常見的數(shù)據(jù)傾斜——特別是處理平臺行為日志數(shù)據(jù),特別容易遇到數(shù)據(jù)傾斜。
這里提供一個上述Spark清洗數(shù)據(jù)的MR代碼邏輯,大家可以對比看看與Spark代碼邏輯的差異性。
- Map階段

邏輯思路
- Reduce階段(這里用不上)

Reduce階段的框架
- Drive階段

驅(qū)動階段的配置
上面這三個階段就是MR任務(wù)常規(guī)的流程,處理上述問題的思路其實和Spark邏輯差不多。只是這套框架性代碼量太多,有很多重復(fù)性,每寫一個MR任務(wù)的工作量也會比較大,執(zhí)行效率我并沒有去測試作比較。
如果Spark跑線上任務(wù)模型會出現(xiàn)不穩(wěn)定的話,我想以后我還是會遷移到MapReduce上去跑離線模型。拭目以待吧!
總結(jié)
說到這里,整篇文章概括起來有三點:
- 講述了數(shù)據(jù)清洗在業(yè)務(wù)場景建模過程中的重要性和流程操作。
- 介紹了兩款主流計算框架的適用場景和差異性。
- 更列舉了不同數(shù)據(jù)處理工具在每個業(yè)務(wù)場景下的優(yōu)勢和不同。
但是,還是那么一句話——使用什么技術(shù)不在乎,我更迷戀業(yè)務(wù)場景驅(qū)動下的技術(shù)挑戰(zhàn)。
與你溝通最關(guān)鍵的,也許會是直屬領(lǐng)導(dǎo),也許會是業(yè)務(wù)運(yùn)營人員,甚至是完全不懂技術(shù)的客戶。他們最關(guān)心的是你在業(yè)務(wù)層面上的技術(shù)方案能否解決業(yè)務(wù)痛點問題。
所以,做大數(shù)據(jù)挖掘要多關(guān)心業(yè)務(wù),別一味只談技術(shù)。
作者介紹
汪榕,3年場景建模經(jīng)驗,曾累計獲得8次數(shù)學(xué)建模一等獎,包括全國大學(xué)生國家一等獎,在國內(nèi)期刊發(fā)表過相關(guān)學(xué)術(shù)研究。兩年電商數(shù)據(jù)挖掘?qū)嵺`,負(fù)責(zé)開發(fā)精準(zhǔn)營銷產(chǎn)品中的用戶標(biāo)簽體系。發(fā)表過數(shù)據(jù)挖掘相關(guān)的多篇文章。目前在互聯(lián)網(wǎng)金融行業(yè)從事數(shù)據(jù)挖掘工作,參與開發(fā)反欺詐實時監(jiān)控系統(tǒng)。微博:樂平汪二。