從Hello World說程序運行機制
開篇
學習任何一門編程語言,都會從Hello World 開始。對于一門從未接觸過的語言,在短時間內我們都能用這種語言寫出它的hello world。然而,對于hello world 這個簡單程序的內部運行機制,我相信還有很多人都不是很清楚。
hello world 這些信息是如何通顯示器過顯示的?cpu執行的代碼和程序中我們寫的的代碼肯定不一樣,她是什么樣子的?又是如何從我們寫的代碼變成cpu能執行的代碼的?程序運行時代碼是在什么地方?她們是如何組織的?程序中的變量存儲在什么地方?函數調用是怎樣是現的?
這篇文章將簡單的討論程序的運行機制
開發平臺隱藏的過程
每一種語言都有自己的開發平臺,我們的程序大多是也都是在這里誕生的。從程序源代碼到可執行文件的轉化過程其實是分很多步而且是很復雜的,只是而現在的開發平臺把所有的這些事情都自己承擔了,給我們帶來方便的同時她也影藏了大量的實現細節。所以大多程序員只負責編寫代碼,其它的復雜的轉換工作則由開發平臺默默完成。
按照我的理解,簡單 的說從源代碼到可執行文件的過程可分為以下幾個階段:
1、從源代碼到機器語言并將產生的機器語言按照一定的規律組織起來。我們暫且稱為文件A。
2、把文件A和運行A需要的文件B(如庫函數)鏈接起來,形成文件A+
3、把文件A+裝載進入內存,運行文件
(其實如果是看參考書或者其他資料的話可能不止這幾步,只是這里為了簡化我把它歸納為3步)
這些事形成可執行文件的關鍵步驟,缺一不可。現在看到被開發平臺“蒙蔽”了吧。下面的部分將撥開迷霧,還你開發平臺的真面目。
目標文件
在計算機領域有過一句經典的話:
“any problem in computer science can be sloved by another layer of indirecition”
“計算機科學領域的任何問題都可以通過增加一個中間層來解決”
比如說要實現從A到B的轉換,可以先把A轉換為文件A+,再把文件A+轉換為我們需要的文件B。(其實在波利亞的《how to slove it》里面對這種方法也有敘述。在解題的時候可以通過增加中間層來簡化問題)
那么從源代碼到可執行文件的過程可以這樣理解。從源代碼到可執行文件也是一樣的, 通過(不斷的)在他們之間增加中間層,來解決問題。和上文說的, 先把源程序轉化為中間文件A,再把中間文件轉化為我們需要的目標文件。
在處理文件的時候就是按照這種思路來的。
其實上面說的文件A更專業的說法是:目標文件。她不是可執行程序,需要和其它的目標文件進行鏈接、裝載后才能執行。對于一個源程序, 開發平臺首先要做的就是把源程序翻譯成機器語言。其中很重要的一部就是編譯。相信很多人都知道,就是把源代碼翻譯成機器語言(其實就是一堆二進制代碼)。編譯知識很重要,卻不是本文的重點,有興趣的可自行google。
目標文件格式:
現在來看一下上面說的目標文件是如何組織的(也就是存放結構)。
起源:
想象一下如果是你來設計會如何組織這些二進制代碼?就像書桌上的物品要分類放置才整潔一樣,為了便于管理翻譯出來的二進制代碼也分類存放,把表示代碼的放在一起,表示數據的放在一起。這樣,二進制代碼就分為了不同的塊來存放。這樣的一個區域就是被稱為段(segment)的東西。
標準:
和計算機科學中的很多東西一樣,為了方便人們的交流、程序的兼容等問題。也為這種二進制的存放方式制訂了標準,于是COFF(common object file format)就誕生了。現在的windows、Linux、等主流操作系統下的目標文件格式和COFF大同小異,都可以認為是它的變種。
a.out:
a.out是目標文件的默認名字。也就是說,當編譯一個文件的時候,如果不對編譯后的目標文件重命名,編譯后就會產生一個名字為a.out的文件。具體的為什么會用這個名字這里就不在深究了。有興趣的可以自己google。
下面的圖可以讓你更直觀的了解目標文件:
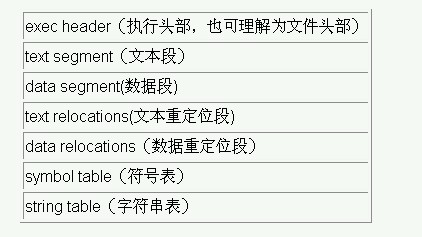
上圖是目標文件的典型結構,實際的情況可能會有所差別,但都是在這個基礎上衍生出來的。
ELF文件頭:即上圖中的***個段。其中的header是目標文件的頭部,里面包含了這個目標文件的一些基本信息。如該文件的版本、目標機器型號、程序入口地址等等。
文本段:里面的數據主要是程序中的代碼部分。
數據段:程序中的數據部分,比如說變量。
重定位段:
重定位段包括了文本重定位和數據重定位,里面包含了重定位信息。一般來說,代碼中都會存在引用了外部的函數,或者變量的情況。既然是引用,那么這些函數、變量并沒存在該目標文件內。在使用他們的時候, 就要給出他們的實際地址(這個過程發生在鏈接的時候)。正是這些重定位表,提供了尋找這些實際地址的信息。理解了上面之后,文本重定位和數據重定位也就不難理解了。
符號表:符號表包含了源代碼中所有的符號信息 。 包括每個變量名、函數名等等。里面記錄了每個符號的信息,比如說代碼中有“student”這個符號,對應的在符號表中就包括這個符號的信息。包括這個符號所在的段、它的屬性(讀寫權限)等相關信息。
其實符號表最初的來源可以說是在編譯的詞法分析階段。在做詞法分析的時候,就把代碼中的每個符號及其屬性都記錄在符號表中。
字符串表:和符號表差不多的功能,存放了一些字符串信息。
其中還有一點要說嗎的是:目標文件都是以二進制來存儲的,它本身就是二進制文件。
現實中的目標文件會比這個模型要復雜些,但是它的思路都是一樣的,就是按照類型來存儲,再加上一些描述目標文件信息的段和鏈接中需要的信息。
a.out剖分
Hello World
空口無憑,我們現在就來研究一下hello world編譯后形成的目標文件,這里用 C 來描述。
簡單的hellow world 源碼:
- /*hello.c*/
- #include<stdio.h>
- int main()
- {
- int a=5;
- printf("hellow world \n");
- }
為了在數據段中也有數據可放,這里增加了“int a=5”。
如果在VC上的話,點擊運行便能看到結果。為了能看清楚內部到底是如何處理的,我們使用GCC來編譯。
運行
gcc hello.c
再看我們的目錄下,就多了目標文件a.out。
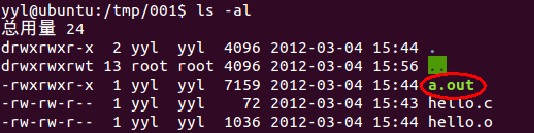
現在我們想做的是看看a.out里到底有什么,可能有童鞋回想到用vim文本查看,當時我也是這么天真的認為。但a.out是何等東西,怎能這么簡單就暴露出來呢 。是的,vim不行。“我們遇到的問題大多是前人就已經遇到并且已經解決的”,對,其中有一個很強悍的工具叫做objdump。有了它,我們就能徹底的去了解目標文件的各種細節,當然還有一個叫做readelf也很有用,這個在后面介紹。這兩個工具一般Linux里面都會自帶有有,可以自行google
注:這里的代碼主要是在Linux下用GCC編譯,查看目標文件用的是Objdump、readelf。但是我會把所有的運行結果都上圖,所以之前沒有接觸過Linux的童鞋來看下面的內容也完全沒問題哦。我用的是ubuntu,感覺挺好~
下面是a.out的組織結構:(每段的起始地址、、大小等等)
查看目標文件的命令是 objdump -h a.out
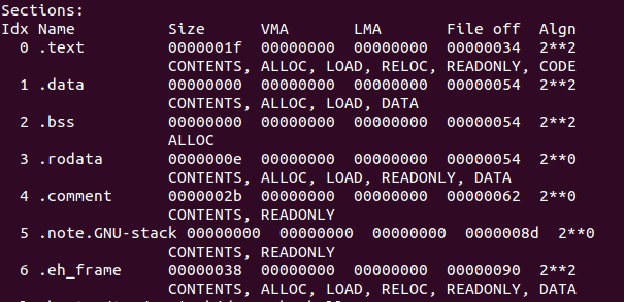
就和上文中描述的目標文件的格式一樣,可以看出是分類存儲的。目標文件被分為了6段。
從左到右,***列(Idx Name)是段的名字,第二列(Size)是大小 ,VMA為虛擬地址,LMA為物理地址,File off是文件內的偏移。也就是這段相對于段中某一參考(一般是段起始)的距離。***的Algn是對段屬性的說明,暫時不用理會
“text”段:代碼段。
“data”段:也就是上面說的數據段,保存了源代碼中的數據,一般是以初始化的數據。
“bss”段:也是數據段,存放那些未初始化的數據,因為這些數據還未分配空間,所以單獨存放。
“rodata”段:只讀數據段,里面存放的數據是只讀的。
“cmment”存放的是編譯器版本信息。
剩下的兩段對我們的討論沒有實際意義,就不再介紹。認為他們包含了一些鏈接、編譯、裝在的信息就可。
注:
這里的目標文件格式只是列出實際情況中主要部分。實際情況還有一些表未列出。如果你也在用Linux,可以用objdump -X 列出更詳細的段內容。
深入a.out
上面部分通過實例說了目標文件中的典型的段,主要是段的信息,如大小 等相關的屬性。
那么這些段里面究竟有些什么東西呢,“text”段里到底存了什么東西,還是用我們的objdump。
objdump -s a.out 通過-s選項就可以查看目標文件的十六進制格式。
查看結果如下:
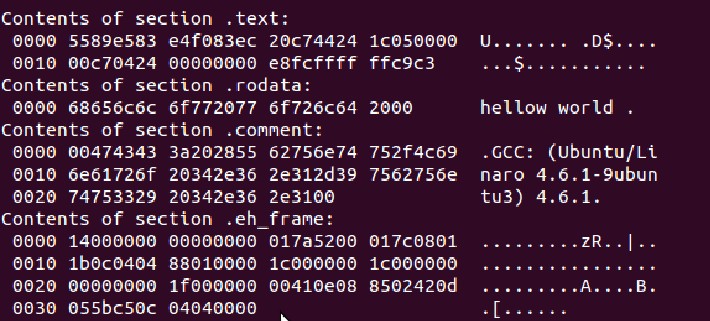
如上圖所示,列出了各段的十六進制表示形式。可以看出圖中共分為兩欄,左邊的一欄是十六進制的表示, 右邊則顯示相應的信息。比較明顯的如“rodata”只讀數據段中就有 “hello world”。。汗,好像程序里的“hello”打錯了,后面多加了一個“w”,截圖麻煩。原諒下哈。
你也可以查看“hellow world”的ASCII值,對應的十六進制就是里面的內容了。“comment”上文中說的這個段包含了一些編譯器的版本信息,這個段后面的內容就是了:GCC編譯器,后面的是版本號。
a.out反匯編
編譯的過程總是先把源文先變為匯編形式,再翻譯為機器語言。(添加中間層嘛)看了這么多的a.out,再研究一下他的匯編形式是恨必要的
objdump -d a.out可以列出文件的匯編形式。不過這里只列出了主要部分,即main函數部分,其實在main函數執行的開始和main函數執行以后都還有多工作要做。即初始化函數執行環境以及釋放函數占用的空間等。
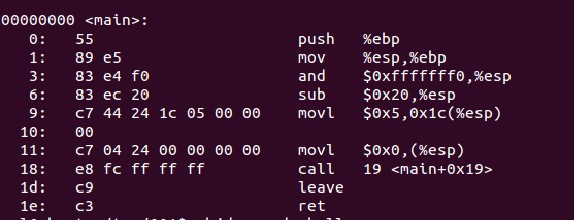
上面的圖中,左邊是代碼的十六進制形式,左邊是匯編形式。對匯編熟悉的童鞋應該能看懂大部分,這里就不在多述。
a.out頭文件
在介紹目標文件格式的時候,提到過頭文件這個概念,里面包含了這個目標文件的一些基本信息。如該文件的版本、目標機器型號、程序入口地址等等。
下圖是文件頭的形式:
可以用readelf -h 來查看。(下圖中查看的是 hello.o,它是源文件hello.c編譯但未鏈接的文件。 這個和查看a.out 大部分是一樣的)
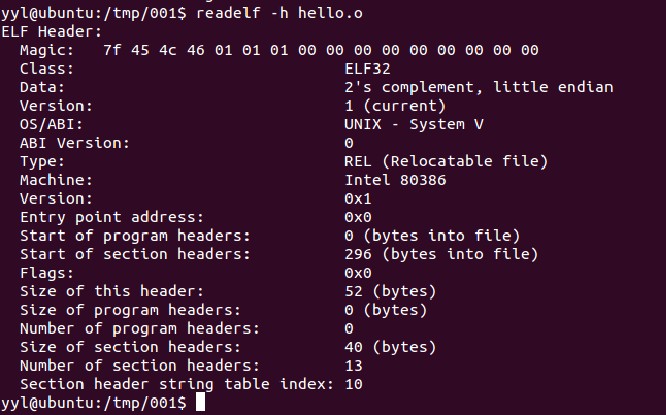
圖中分為兩欄,左邊一欄表示的是屬性,右邊是屬性值。***行常被稱為魔數。后面是一連串的數字,其中的具體含義就不多說了,可以自己去google。
接下來的是一些和目標文件相關的信息。由于和我們要討論的問題關系不大,這里就不展開討論了。
上面是內容用具體的實例說了目標文件內部的組織形式,目標文件只是產生可執行文件過程中的一個中間過程,對于程序是如何運行的還沒做討論,目標文件是如何轉變為可執行文件以及可執行文件是如何執行的將在下面的部分中討論
對鏈接的簡單認識
鏈接通俗的說就是把幾個可執行文件。如果程序A中引用了文件B中定義的函數,為了A中的函數能正常執行,就需要把B中的函數部分也放在A的源代碼中,那么將A和B合并成一個文件的過程就是鏈接了。有專門的過程用來鏈接程序,稱為鏈接器。他將一些輸入的目標文件加工后合成一個輸出文件。這些目標文件中往往有相互的數據、函數引用。
上文中我們看過了hello world的反匯編形式,是一個還沒有經過鏈接的文件,也就是說當引用外部函數的時候是不知道其地址的,如下圖:
上圖中,cal指令就是調用了printf()函數,因為這時候printf()函數并不在這個文件中,所以無法確定它的地址,在十六進制中就用“ff ff ff ”來表示它的地址。等經過鏈接以后,這個地址就會變為函數的實際地址,應為連接后這個函數已經被加載進入這個文件中了。
鏈接的分類:按把A相關的數據或函數合并為一個文件的先后可以把鏈接分為靜態鏈接和動態鏈接。
靜態鏈接:
在程序執行之前就完成鏈接工作。也就是等鏈接完成后文件才能執行。但是這有一個明顯的缺點,比如說庫函數。如果文件A 和文件B 都需要用到某個庫函數,鏈接完成后他們連接后的文件中都有這個庫函數。當A和B同時執行時,內存中就存在該庫函數的兩份拷貝,這無疑浪費了存儲空間。當規模擴大的時候,這種浪費尤為明顯。靜態鏈接還有不容易升級等缺點。為了解決這些問題,現在的很多程序都用動態鏈接。
動態鏈接:和靜態鏈接不一樣,動態鏈接是在程序執行的時候才進行鏈接。也就是當程序加載執行的時候。還是上面的例子 ,如果A和B都用到了庫函數Fun(),A和B執行的時候內存中就只需要有Fun()的一個拷貝。
關于鏈接還有很多知識,以后會用專門的文章來談。這里就不展開講了。
對裝載的簡單解釋
我們知道,程序要運行是必然要把程序加載到內存中的。在過去的機器里都是把整個程序都加載進入物理內存中,現在一般都采用了虛擬存儲機制,即每個進程都有完整的地址空間,給人的感覺好像每個進程都能使用完成的內存。然后由一個內存管理器把虛擬地址映射到實際的物理內存地址。
按照上文的敘述, 程序的地址可以分為虛擬地址和實際地址。虛擬地址即她在她的虛擬內存空間中的地址,物理地址就是她被加載的實際地址。
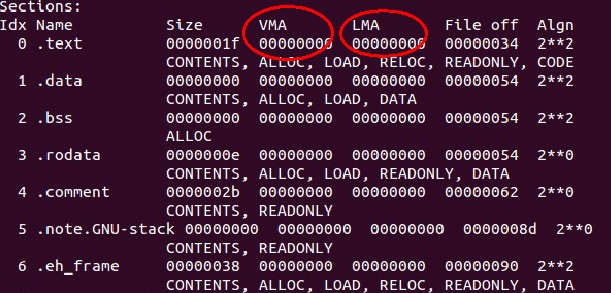
在上文中查看段 的時候或許你已經注意到了,由于文件是未鏈接、未加載的,所以每個段的虛擬地址和物理地址都是0.
加載的過程可以這樣理解:先為程序中的各部分分配好虛擬地址,然后再建立虛擬地址到物理地址的映射。其實關鍵的部分就是虛擬地址到物理地址的映射過程。程序裝在完成之后,cpu的程序計數器pc就指向文件中的代碼起始位置,然后程序就按順序執行。
小結一下
寫這篇文章的目的在于梳理程序運行的機制,在一個可執行文件執行的背后都隱藏了什么。從源代碼到可執行文件通常要經歷許多中間步驟,每一個中間步驟都生成一個中間文件。只是現在的集成開發環境都吧這些步驟影藏了,習慣于集成開發環境的我們也就逐漸的忽略了這些重要的技術內幕。
這篇文章也只是介紹了一下這個過程的主線而已。其中的每一個細節展開來講都可足已用一篇文章來論述。上面寫的多是我個人的理解和看法。有不足的地方、還望能不吝賜教。