通過靜態分析檢測二進制代碼中的Use-After-Free漏洞
前言
Use-After-Free是一種眾所周知的漏洞類型,經常被現代的攻擊代碼所利用(參見Pwn2own 2016)。在研究項目AnaStaSec中,AMOSSYS提供了許多關于如何靜態檢測二進制代碼中的此類漏洞的介紹。在這篇博文中,我們將向讀者闡述學術界在如何檢測這種類型的漏洞方面提出的各種建議。當然,他們當前的目標是定義一種通用方法,這樣的話,我們就可以根據自己的需求來構建相應的概念驗證工具了。
關于Use-After-Free(UAF)漏洞
UAF的原理很容易理解。當程序嘗試訪問先前已被釋放的內存區時,就會出現“Use-After-Free”漏洞。在這種情況下創建的懸空指針將指向內存中已經釋放的對象。
舉個例子,下面的代碼將導致一個UAF漏洞。如果下面的代碼在運行過程中執行了if分支語句的話,由于指針ptr指向無效的存儲器區,所以可能發生不確定的行為。
- char * ptr = malloc(SIZE);
- …
- if (error){
- free(ptr);
- }
- …
- printf("%s", ptr);
圖 1:Use-After-Free示例代碼
換句話說,如果發生如下所示的3個步驟,就會出現UAF漏洞:
(1)分配一個內存區并且讓一個指針指向它。
(2)內存區被釋放,但原來的指針仍然可用。
(3)使用該指針訪問先前釋放的內存區。
大多數時候,UAF漏洞會只會導致信息泄漏,但有的時候,它還可能導致代碼執行——攻擊者對這種情況更感興趣。導致代碼執行通常發生在下列情況下:
- 程序分配了內存塊A,后來將其釋放了。
- 攻擊者分配了內存塊B,并且該內存塊使用的就是之前分配給內存塊A的那片內存。
- 攻擊者將數據寫入內存塊B。
- 程序使用之前釋放的內存塊A,訪問攻擊者留下的數據。
在C++中,當類A被釋放后,攻擊者立刻在原來A所在的內存區上建立一個類B的時候,就經常出現這種漏洞。這樣的話,當調用類A的方法的時候,實際上執行的是攻擊者加載到類B中的代碼。
現在我們已經掌握了UAF的概念,接下來我們將考察安全社區是如何檢測這種漏洞的。
靜態和動態分析的優缺點
二進制代碼的分析方法主要有兩種:靜態分析和動態分析。就目前來說,動態地分析整個代碼是非常困難的,因為要想生成可以覆蓋所有二進制代碼執行路徑的輸入的話,絕不是一件容易的事情。因此,當我們專注于代碼覆蓋問題時,靜態分析方法似乎更為適用。
然而,根據論文[Lee15]和[Cab12]的介紹,與Use-After-Free漏洞檢測有關的大多數學術論文仍然集中在動態分析方面。這主要是因為。動態分析方法易于檢測同一指針的副本,也稱為別名。換句話說,使用動態分析方法時,我們可以直接訪問內存中的值,這種能力對于代碼分析來說是非常重要的。如果使用動態分析的話,我們能夠獲得更高的準確性,但同時也會失去一些完整性。
然而,本文將專注于靜態分析方法。在學術界看來,這種方法仍然面臨兩大困難:
1) 最大的困難是如何管理程序中的循環。實際上,當計算循環中待處理的變量的所有可能值時,需要知道循環將被執行多少次。這個問題通常被稱為停機問題。在可計算性理論中,所謂停機問題就是去判斷程序會最終停下來,還是一直運行下去。不幸的是,這個問題已經被證明是無解的。換句話說,沒有通用算法可以在給出所有可能輸入的情況下解決所有可能程序的停止問題,即不存在一個判定一切程序的程序,因為這個程序本身也是程序。在這種情況下,為了解決這個問題,只好借助于靜態分析工具來進行相應的簡化了。
2) 另一個困難在于內存的表示方式。一個簡單的解決方案是維護一個大數組,其中保存指針的內存值。然而,這不是看起來那么簡單。例如,一個內存地址可以具有多個可能的值,或者一些變量可以具有多個可能的地址。此外,如果有太多可能取值,那么將所有的值都單獨保存的話是不合理的。因此,必須對這種內存表示進行一些簡化。
為了降低靜態分析的復雜性,一些論文像[Ye14]或像Polyspace或Frama-C這樣的工具,都是在C源代碼級別來分析問題的,因為這個級別包含了最大程度的信息。但是,人們在分析應用程序的時候,通常是無法訪問源代碼的。
從二進制代碼到中間表示
當我們進行二進制分析的時候,第一步是建立相關的控制流圖(CFG)。控制流圖是一種有向圖,用來表示程序在執行期間可能經過的所有路徑。CFG的每個節點代表一條指令。由一條邊連接的兩個節點表示可以連續執行的兩個指令。如果一個節點具有兩個延伸到其他節點的邊,這表明該節點是一個條件跳轉指令。因此,通過CFG我們可以將一個二進制代碼組織成一個指令的邏輯序列。在為可執行文件建立CFG的時候,最常見的方法是使用反匯編程序IDA Pro。
當處理二進制代碼方面,學術論文好像都是用相同的方式來處理UAF漏洞的。論文[Gol10]和[Fei14]給出了具體的處理步驟:
事實表明循環似乎對Use-After-Free的存在沒有很大的影響。因此,在著手處理二進制代碼時,一個強制性的步驟就是利用第一次迭代展開循環。就像我們前面剛剛解釋的那樣,這個步驟可以避免停機問題。第一次迭代
為了簡化前面提到的內存表示問題,我們可以使用中間表示形式(IR),因為這種表示形式可以獨立于具體的處理器架構。例如,x86匯編代碼就過于復雜,因為它有太多的指令。一個解決辦法是對小型的指令集進行分析。使用中間表示形式的時候,每個指令都被轉換為幾個原子指令。至于選擇哪種中間表示形式,則取決于分析的類型。在大多數情況下,我們都會選擇逆向工程中間語言(REIL),但是在一些學術文獻中也有使用其他IR的,例如BAP([Bru11])或Bincoa([Bar11])等。
REIL IR只有17種不同的指令,并且每個指令最多有一個結果值。我們可以使用像BinNavi這樣的工具將本機x86匯編代碼轉換為REIL代碼,BinNavi是由Google(以前是Zynamics)開發的一個開源工具。BinNavi可以將IDA Pro的數據庫文件作為輸入,這一特性給我們帶來了極大的便利。
符號執行與抽象解釋
一旦將二進制代碼轉換為中間表示形式,我們就可以通過兩種方法來分析這些二進制代碼的行為了,即抽象解釋([Gol10]和[Fei14])或符號執行([Ye14])。
符號執行使用符號值作為程序的輸入,將程序的執行轉變為相應符號表達式的操作,通過系統地遍歷程序的路徑空間,實現對程序行為的精確分析。因此,符號執行不會使用輸入的實際值,而是采用抽象化符號的形式來表示程序中的表達式和變量。因此,這種分析方法不是跟蹤變量的值,而是用代表變量值的符號來生成算術表達式,這些表達式可以用于檢查條件分支等。
另一方面,抽象解釋是基于這樣的思想的——程序的分析可以在一定抽象級別上進行。因此,不需要跟蹤每個變量的精確值,并且語義可以替換為描述指令對變量的影響的抽象語義。例如,變量可以由它們的符號來定義。對于加法指令來說,可以通過檢查操作數的符號來設置結果的符號。因此,如果操作數的符號是+,那么結果的符號也是+,但是永遠不會計算變量的確切值。除符號之外,我們還可以定義其他各種抽象域。例如,可以通過一個內存位置(全局,堆和棧)上的值區間來跟蹤變量的值。值集分析(VSA)就是一種基于這種表示方法的分析技術。
舉例來說,monoREIL框架就是一個基于REIL IR的VSA引擎。它極大地簡化了VSA算法的開發工作,使開發人員能夠在自己的抽象域上執行VSA。
分析中間表示形式
下一個問題是如何通過CFG時實現分析算法。同樣,這里也有兩種方式:
- 過程內分析,限于當前函數的范圍
- 過程間分析,能夠進入子函數
不用說,程序內分析要比程序間分析簡單得多。然而,當一個人想要檢測UAF漏洞時,他必須能夠一直跟蹤內存塊:從這些內存塊的分配到釋放...,所以,有時候會涉及多個函數。
這就是為什么論文[Gol10]提出首先進行過程內分析,然后將其擴展到全局的過程間分析的原因。如圖2所示,對于每個函數,都創建一個相應的方框。這些方框用來總結函數的行為,連接它們的輸出與輸入。因此,當將分析擴展到過程間分析時,每個函數調用都會被這個函數的過程內分析的結果代替。這種方法的主要優點是函數只需要分析一次即可,即使它們被調用了很多次也是如此。此外,在進行過程內分析時,即使非常小的代碼塊也不會放過,因此這種方法是非常精確的。
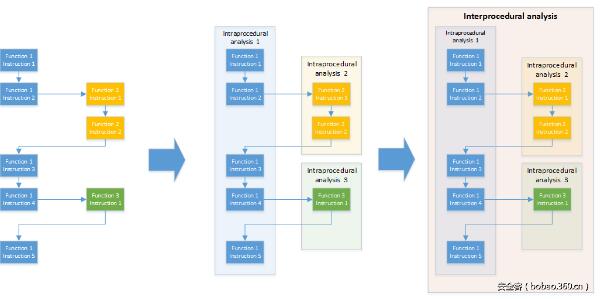
圖2:由諸多過程內分析合并而成的過程間分析
此外,在論文[Fei14]中還提出了另一種解決方案。第二種方法(如圖3所示)會將被調用函數內聯到調用函數中。因此,函數調用不再是一個問題。雖然該解決方案更加容易實現,但是它有一個缺點,即如果一個函數被調用兩次的話,則該函數將被分析兩次。因此,該方法更加耗時,對內存的需求也更大。
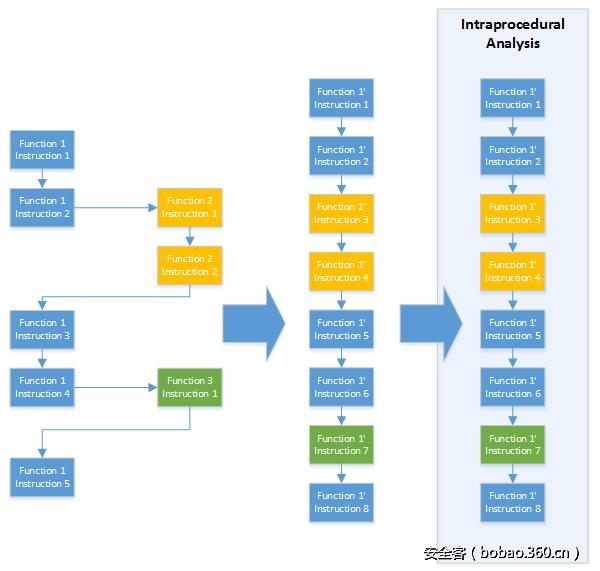
圖3:通過將函數內聯到單一函數中的過程間分析
檢測UAF漏洞
在上文中,我們介紹了分析二進制代碼語義的不同方法,以及遍歷控制流圖的各種方法。下面,我們開始介紹如何檢測UAF模式。首先讓我們UAF的定義,我們知道UAF是通過兩個不同的事件來進行刻畫的:
- 創建一個懸空指針,
- 訪問該指針指向的內存。
為了檢測這種模式,論文[Fei14]跟蹤所有已經釋放的內存堆區域,并且在每次使用指針時都會檢查它是否指向這些已經釋放的內存區。
下面,讓我們拿下面的偽代碼為例進行說明。注意,為了簡單起見,該示例沒有提供復雜的CFG。事實上,CFG的處理方法取決于所選擇的分析方法及其實現...這個例子的目的,只是展示一種通過分析代碼檢測Use-After-Free的方法。
1. malloc(A);
2. malloc(B);
3. use(A);
4. free(A);
5. use(A);
上面的偽代碼分配了兩個內存塊,并且可以通過名稱A和B來引用這兩個內存塊。然后,訪問(Use(A))了一次內存塊A之后,接著釋放(Free(A))該內存塊。之后,又再次訪問了該內存塊。
通過定義兩個域(一組分配的堆元素和一組釋放的堆元素),可以在每個指令處更新這些集合,并檢查它訪問的內存是否屬于已分配的內存塊集合,具體如圖4所示。
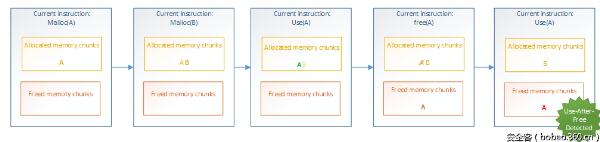
圖 4:通過域檢測機制挖掘Use-After-Free漏洞
當內存塊A被再次訪問時,它已經在上一步中被注冊為已釋放的內存塊,因此分析程序就會發出警報:檢測到Use-After-Free漏洞。
在論文[Ye14]中,它提出的另一種檢測目標模式的方法,但是它使用的是簡單狀態機。該方法的思路是,在分配內存之后,指向該內存塊的指針被設置為“分配”狀態,并且該狀態在相應的內存塊未被釋放之前保持不變。當內存塊被釋放時,它們就會轉換為“釋放”狀態。當處于釋放狀態的指針被使用的時候,就會導致“Use-After-Free”狀態。然而,如果指針及其別名被刪除并且不再引用內存塊的話,則它們就是無害的,這時就會進入“結束”狀態。這個簡單的狀態機如圖5所示。

圖5:用于檢測Use-After-Free漏洞的簡單狀態機
此外,在論文[Gol10]中也提出一個不同的解決方案,但是它使用的工具是圖論。在這篇論文中,作者會對使用指針的語句進行檢查,看看它是在釋放內存的語句之后還是之前。如果是之后的話,就檢測出了UAF漏洞。
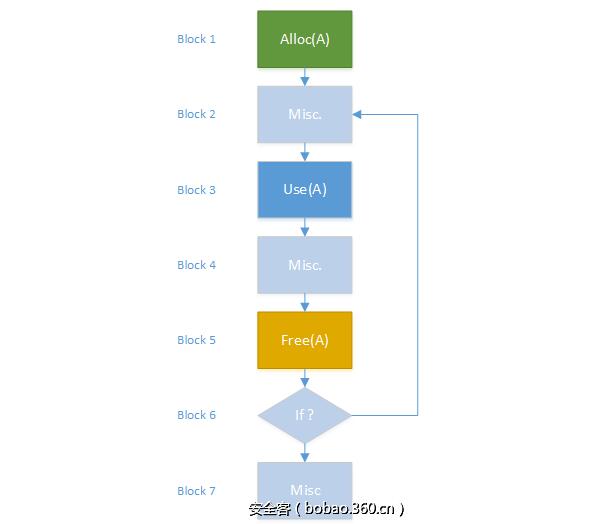
圖6:具有潛在Use-After-Free漏洞的圖
在任何情況下,只要檢測到懸空指針,分析的最后階段必須通過提取導致該指針的子圖來表征UAF漏洞。這個子圖必須包含所有必要的元素,來讓人類手動檢查,以避免真陽性。
總結
我們在這里介紹了幾種通過基于靜態分析的二進制代碼Use-After-Free漏洞檢測方法。同時,我們也對這種分析觸發器的不同問題進行了詳細的介紹,閱讀之后您就不難理解為什么在檢測這種bug的時候沒有簡單的解決方案了。
我們在開展這項工作中還發現,只有少數研究人員將其成果作為開源項目發布。Veribag團隊的Josselin Feist開發的GUEB項目就是其中之一。如果對這個課題感興趣的話,我們鼓勵你訪問他的Github。