透徹Linux(Unix)五種IO模型
IO模型
用一幅圖表示所支持的I/O模型
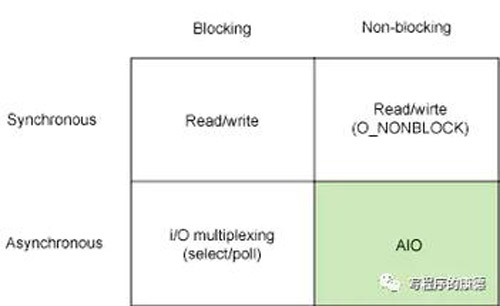
縱向維度是“阻塞(Blocking)”、“非阻塞(Non-blocking)”;橫向維度是“同步”、“異步”。總結(jié)起來是四種模型同步阻塞、同步非阻塞;異步阻塞、異步非阻塞。《Unix網(wǎng)絡(luò)編程》中劃分出了“第五種”模型——“信號驅(qū)動式IO”其實屬于異步阻塞類型,這種模型的通知方式有多種多樣后面展開說明。
同步/異步、阻塞/非阻塞
從內(nèi)核角度看I/O操作分為兩步:用戶層API調(diào)用;內(nèi)核層完成系統(tǒng)調(diào)用(發(fā)起I/O請求)。所以“異步/同步”的是指API調(diào)用;“阻塞/非阻塞”是指內(nèi)核完成I/O調(diào)用的模式。用一幅圖表示更加明顯
同步是指函數(shù)完成之前會一直等待;阻塞是指系統(tǒng)調(diào)用的時候進程會被設(shè)置為Sleep狀態(tài)直到等待的事件發(fā)生(比如有新的數(shù)據(jù))。明白這一點之后再看這五種模型相信就會清晰很多,我們挨個分析:
同步阻塞
這種模型最為常見,用戶空間調(diào)用API(read、write)會轉(zhuǎn)化成一個I/O請求,一直等到I/O請求完成API調(diào)用才會完成。這意味著:在API調(diào)用期間用戶程序是同步的的;這個API調(diào)用會導(dǎo)致系統(tǒng)以阻塞的模式執(zhí)行I/O,如果此時沒有數(shù)據(jù)則一直“等待”(放棄CPU主動掛起——Sleep狀態(tài))(注意,對于硬盤來說是不會出現(xiàn)阻塞的,無論是什么時候讀它總是有數(shù)據(jù)。常見的阻塞設(shè)備是終端、網(wǎng)卡之類的)。
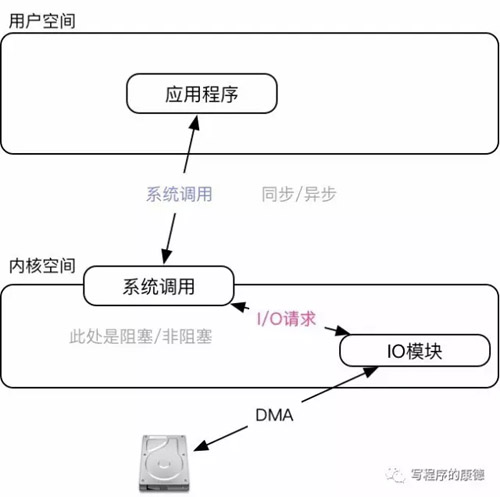
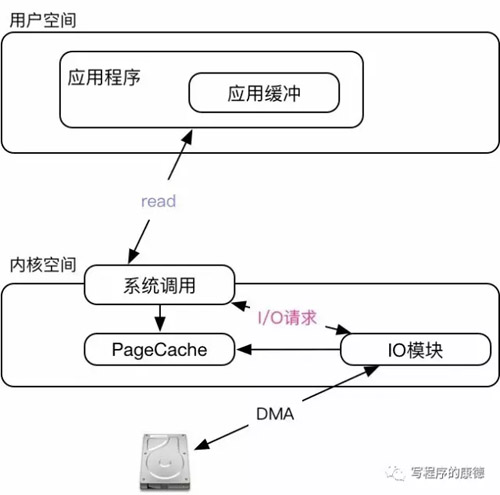
以read為例子,它由三個參數(shù)組成,***個函數(shù)是文件描述符;第二個是應(yīng)用緩沖;第三個參數(shù)是需要讀取的字節(jié)數(shù)。經(jīng)過系統(tǒng)調(diào)用會以阻塞模式執(zhí)行I/O,I/O模塊讀取數(shù)據(jù)后會放入到PageCache中;***一步是把數(shù)據(jù)從PageCache復(fù)制到應(yīng)用緩沖。如果I/O請求無法得到滿足——沒有數(shù)據(jù),則主動讓出CPU直到有數(shù)據(jù)(注意,即便系統(tǒng)調(diào)用讓出CPU也未必真的就讓出。read函數(shù)是同步的,所以CPU還是會被用戶空間代碼占用)。
同步非阻塞
這種模式通過調(diào)用read、write的時候指定O_NONBLOCK參數(shù)。和“同步阻塞”模式的區(qū)別在于系統(tǒng)調(diào)用的時候它是以非阻塞的方式執(zhí)行,無論是否有數(shù)據(jù)都會立即返回。
以read為例,如果成功讀取到數(shù)據(jù)它返回讀取到的字節(jié)數(shù);如果此時沒有數(shù)據(jù)則返回-1,同時設(shè)置errno為EAGAIN(或者EWOULDBLOCK,二者相同)。所以這種模式下我們一般會用一個“循環(huán)”不停的嘗試讀取數(shù)據(jù),處理數(shù)據(jù)。
異步阻塞
同步模型最主要的問題是占用CPU,阻塞I/O會主動讓出CPU但是用戶空間的系統(tǒng)調(diào)用還是不會返回依然耗費CPU;非阻塞I/O必須不停的“輪詢”不斷嘗試讀取數(shù)據(jù)(會耗費更多CPU更加低效)。如果仔細(xì)分析同步模型霸占CPU的原因不難得出結(jié)論——都是在等待數(shù)據(jù)到來。異步模式正是意識到這一點所以把I/O讀取細(xì)化為訂閱I/O事件,實際I/O讀寫,在“訂閱I/O事件”事件部分會主動讓出CPU直到事件發(fā)生。異步模式下的I/O函數(shù)和同步模式下的I/O函數(shù)是一樣的(都是read、write)唯一的區(qū)別是異步模式“讀”必有數(shù)據(jù)而同步模式則未必。
常見的異步阻塞函數(shù)包括select,poll,epoll,這些函數(shù)的用法需要花費相當(dāng)大的篇幅介紹而這篇文章我想集中精力介紹“I/O模型”。以select為例我們看一下大致原理
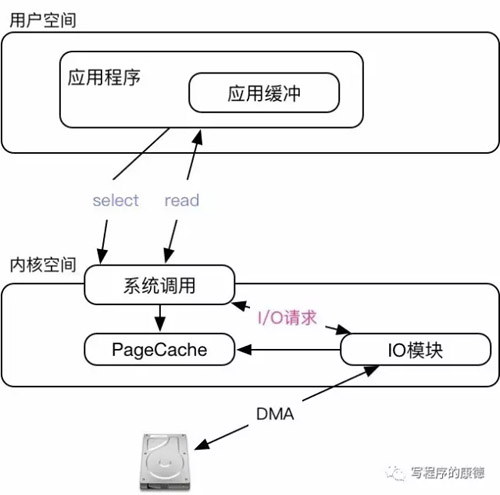
異步模式下我們的API調(diào)用分為兩步,***步是通過select訂閱讀寫事件這個函數(shù)會主動讓出CPU直到事件發(fā)生(設(shè)置為Sleep狀態(tài),等待事件發(fā)生);select一旦返回就證明可以開始讀了所以第二部是通過read讀取數(shù)據(jù)(“讀”必有數(shù)據(jù))。
異步阻塞模型之信號驅(qū)動
“***主義者”看了上面的select之后會有點不爽——我還要“等待”讀寫事件(即便select會主動讓出CPU),能不能有讀寫事件的時候主動通知我啊?。借助“信號”機制我們可以實現(xiàn)這個,但是這并不***而且有點弄巧成拙的意思。
具體用法:通過fcntl函數(shù)設(shè)置一個F_GETFL|O_ASYNC( 曾經(jīng)信號驅(qū)動I/O也叫“異步I/O”所以才有O_ASYNC的說法),當(dāng)有I/O時間的時候操作系統(tǒng)會觸發(fā)SIGIO信號。在程序里只需要綁定SIGIO信號的處理函數(shù)就可以了。但是這里有個問題——信號處理函數(shù)由哪個進程執(zhí)行呢?,答案是:“屬主”進程。操作系統(tǒng)只負(fù)責(zé)參數(shù)信號而實際的信號處理函數(shù)必須由用戶空間的進程實現(xiàn)。(這就是設(shè)置F_SETOWN為當(dāng)前進程PID的原因)
信號驅(qū)動性能要比select、poll高(避免文件描述符的復(fù)制)但是缺點是致命的——*Linux中信號隊列是有限制的如果操過這個數(shù)字問題就完全無法讀取數(shù)據(jù)。
異步非阻塞
這種模型是最“省事”的模型,系統(tǒng)調(diào)用完成之后就只要坐等數(shù)據(jù)就可以了。是不是特別爽?其實不然,問題出在實現(xiàn)上。Linux上的AIO兩個實現(xiàn)版本,POSIX的實現(xiàn)最爛(藍色巨人的鍋)性能很差而且是基于“事件驅(qū)動”還會出現(xiàn)“信號隊列不足”的問題(所以它就偷偷的創(chuàng)建線程,導(dǎo)致線程也不可控了);一個是Linux自己實現(xiàn)的(redhat貢獻)Native AIO。Native AIO主要涉及到的兩個函數(shù)io_submit設(shè)置需要I/O動作(讀、寫,數(shù)據(jù)大小,應(yīng)用緩沖區(qū)等);io_getevents等待I/O動作完成。沒錯,即便你的整個I/O行為是非阻塞的還是需要有一個辦法知道數(shù)據(jù)是否讀取/寫入成功。
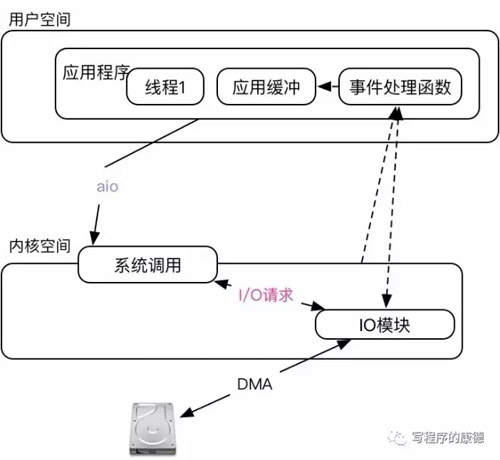
注意圖中,內(nèi)核不再為I/O分配PageCache,所有的數(shù)據(jù)必須有用戶自己讀取到應(yīng)用緩沖中維護。所以AIO一定是和“直接I/O”配合使用。
AIO針對網(wǎng)卡設(shè)備的意義不大,首先它的實現(xiàn)本質(zhì)上和epoll差不多;其次它在Linux中的作用更多的是用于磁盤I/O(異步非阻塞可以不用多線程就造成大量的I/O請求便于I/O模塊“合并”優(yōu)化會提高整體I/O的吞吐率——而且對CPU開銷比較少)。
在Nginx中用了一個技巧,可以實現(xiàn)AIO和epoll聯(lián)動,AIO讀取到數(shù)據(jù)后觸發(fā)epoll發(fā)送數(shù)據(jù)。(這個特性是非常尷尬的,如果是磁盤文件完全可以用sendfile搞定)。
Direct I/O和Buffered I/O
Linux在進行I/O操作的時候會先把數(shù)據(jù)放到PageCache中然后通過“內(nèi)存映射”的方式返回給應(yīng)用程序,這樣做的好處是可以預(yù)讀數(shù)據(jù)也能在多個進程讀取相同數(shù)據(jù)的時候起到Cache的作用。應(yīng)用程序不能直接使用PageCache中的數(shù)據(jù),通常是復(fù)制到一塊“用戶空間”的內(nèi)存中再使用。
- Direct I/O是指數(shù)據(jù)不落在PageCache,直接從設(shè)備讀取到數(shù)據(jù)后放到用戶空間中
- Buffered I/O是指數(shù)據(jù)競購PageCache
同步I/O只能使用Buffered I/O;異步阻塞I/O可以Buffered I/O也可以使用Direct I/O;異步非阻塞I/O只能使用Direct I/O
Zero Copy
考慮從磁盤讀取文件經(jīng)過網(wǎng)卡發(fā)送出去,會有四次內(nèi)存復(fù)制:1. DMA會復(fù)制磁盤數(shù)據(jù)到內(nèi)核空間,2. 應(yīng)用程序復(fù)制內(nèi)核空間的數(shù)據(jù)到用戶空間;3. 應(yīng)用程序用戶空間的數(shù)據(jù)復(fù)制到Socket緩沖(內(nèi)核空間);4. 協(xié)議棧把數(shù)據(jù)復(fù)制到網(wǎng)卡的中發(fā)送。
簡單來說Zero Copy就是節(jié)省這個過程中的內(nèi)存復(fù)制次數(shù)。有幾種做法:
- Direct I/O直接把磁盤數(shù)據(jù)復(fù)制到內(nèi)核空間;但是Direct I/O沒有辦法直接把數(shù)據(jù)放到網(wǎng)卡中——必須要經(jīng)過協(xié)議棧。所以可以節(jié)省一次內(nèi)存復(fù)制;
- sendfile,磁盤數(shù)據(jù)通過DMA讀取到內(nèi)核空間后直接交給TCP/IP協(xié)議棧;真正的不需要內(nèi)存復(fù)制;
除此之外還可以利用splice、mmap做一些優(yōu)化,根據(jù)不同的設(shè)備需要采用不同的方式此處不再展開。
【本文是51CTO專欄作者邢森的原創(chuàng)文章,轉(zhuǎn)載請聯(lián)系作者本人獲取授權(quán)】