大數據平臺Docker應用之路
隨著大數據平臺型產品方向的深入應用實踐和Docker開源社區的逐漸成熟,業界有不少的大數據研發團隊開始擁抱Docker。簡單來說,Docker會讓Hadoop平臺部署更加簡單快捷、讓研發和測試團隊集成交付更加敏捷高效、讓產線環境的運維更加有質量保障,而這背后的業務場景和具體的實踐方法有哪些?在Docker容器服務逐步走向完善的過程中,大數據平臺產品Docker模式的應用又是如何解決的?正是本文所著重闡述的。
實踐中發現問題
場景一
在大數據平臺型產品的開發過程中,經常要跟許多模塊打交道,包括Hadoop、HBase、Hive、Spark、Sqoop、Solr、Zookeeper……等多達幾十個開源組件,為了不影響團隊成員間的工作任務協同,開發人員其實非常需要自己有一套獨立的集群環境,以便反復測試自己負責的模塊,可真實的企業開發環境往往只有一兩個大的虛擬集群,這可怎么辦?難道要給每個開發人員都配幾臺獨立的物理機器?
場景二
針對每一次新版本的發布,產品測試組都需要反復的重裝整個平臺以便發現問題,而正如本文前面所闡述的那樣,大數據平臺所依賴的組件繁多,不同組件模塊依賴的底層庫也不盡相同,經常會出現各種依賴沖突問題,而一旦安裝完成,就很難再讓Linux系統恢復到一個非常干凈的狀態,通過Remove、UnInstall、rpm -e等手動方式卸載,往往需要花費很長的時間,那如何才能快速地恢復大數據平臺集群的系統環境?
場景三
當測試人員在測試大數據平臺過程中發現了一個Bug,需要保存現場,這里面包括相關的大數據組件配置、進程狀態、運行日志、還有一些中間數據,可是,平臺集群服務器節點數量很多,針對每個進程的配置目錄和日志文件,都相對較獨立,一般都需要專業的開發工程師或者運維工程師進入相關服務器節點,按照不同組件的個性化配置信息,手工方式收集所需的各個條目信息,然后打包匯集到日志中心服務器進行統一分析,而目前業界并沒有一款能夠自動分布式收集故障相關的日志系統,但測試工作還要繼續,怎么辦?
場景四
如何把一個部署好的大數據平臺快速地遷移到其它地方?
你得注意以下幾點:
- 如果是關鍵業務系統,數據不能丟;
- 如果是遷移物理機,機器可能會壞;
- 如果是不間斷實時在線業務,要保證快速平穩切換。
傳統解決方案的缺陷
想要解決這些問題,第一個想到的方案當然是用虛擬機,而筆者經歷的團隊,之前也確實用的就是虛擬機,但這種方式并不能完美的解決以上問題,比如:
- 雖然虛擬機也可以完成系統環境的遷移,但這并不是它所擅長的,不夠靈活,很笨重。
- 虛擬機的快照可以保存當前的狀態,但要恢復回去,就得把當前正在運行的虛擬機關閉,所以并不適合頻繁保存當前狀態的業務場景。
- 雖然可以給每個人都分配幾個虛擬機用,但它是一個完整的系統,本身需要較多的資源,底層物理機的資源很快就被用完了,所以我們需要尋找其它方式來彌補這些不足。
Docker技術的引入
Docker 項目的目標是實現輕量級的操作系統虛擬化解決方案,換句話說,它可以讓我們把一臺物理機虛擬成多臺來使用,而且它還可以保存修改、完整遷移到其它地方、性能損耗小等等好處,能夠很好解決我們之前遇到的問題。
那為什么不用虛擬機方案?
簡單來說,因為它比虛擬機更輕便,啟動一個Docker容器只要幾秒種的時間,在一臺物理機上可以創建幾百上千個容器,而虛擬機做不到。
下面是虛擬機與Docker兩種方案的實現原理:

虛擬機實現資源隔離的方法是利用獨立的OS,并利用Hypervisor虛擬化CPU、內存、IO設備等實現的。例如,為了虛擬CPU,Hypervisor會為每個虛擬的CPU創建一個數據結構,模擬CPU的全部寄存器的值,在適當的時候跟蹤并修改這些值。需要指出的是在大多數情況下,虛擬機軟件代碼是直接跑在硬件上的,而不需要Hypervisor介入。只有在一些權限高的請求下,Guest OS需要運行內核態修改CPU的寄存器數據,Hypervisor會介入,修改并維護虛擬的CPU狀態。
Hypervisor虛擬化內存的方法是創建一個shadow page table。正常的情況下,一個page table可以用來實現從虛擬內存到物理內存的翻譯。在虛擬化的情況下,由于所謂的物理內存仍然是虛擬的,因此shadow page table就要做到:虛擬內存->虛擬的物理內存->真正的物理內存。

對比虛擬機實現資源和環境隔離的方案,docker就顯得簡練很多。docker Engine可以簡單看成對Linux的NameSpace、Cgroup、鏡像管理文件系統操作的封裝。docker并沒有和虛擬機一樣利用一個完全獨立的Guest OS實現環境隔離,它利用的是目前Linux內核本身支持的容器方式實現資源和環境隔離。簡單的說,docker利用namespace實現系統環境的隔離;利用Cgroup實現資源限制;利用鏡像實現根目錄環境的隔離。
當新建一個容器時,docker不需要和虛擬機一樣重新加載操作系統內核。我們知道,引導、加載操作系統內核是一個比較費時費資源的過程,當新建一個虛擬機時,虛擬機軟件需要加載Guest OS,這個新建過程是分鐘級別的。而docker由于直接利用宿主機的操作系統,則省略了這個過程,因此新建一個docker容器只需要幾秒鐘。另外,現代操作系統是復雜的系統,在一臺物理機上新增加一個操作系統的資源開銷是比較大的,因此,docker對比虛擬機在資源消耗上也占有比較大的優勢。事實上,在一臺物理機上我們可以很容易建立成百上千的容器,而只能建立幾個虛擬機。
可見容器是在操作系統層面上實現虛擬化,直接復用本地主機的操作系統,而傳統方式則是在硬件層面實現。當然,一些容器核心模塊依賴于高版本內核,存在部分版本兼容問題。
如何基于Docker實現大數據平臺的敏捷部署與運維?
第一步:搭建基礎的Docker環境
在實踐過程中,部署一套可用的大數據平臺Docker環境,必需做好以下前提工作:
- 搭建私有鏡像倉庫,用來統一存放構建好的鏡像文件
- 搭建一個安裝包倉庫,用來存放我們發布的各種版本的大數據組件安裝包
- 配置多個物理機上的Dcoker容器可以相互通信,可參考官方給出的方案
第二步:為大數據平臺定制基礎鏡像
1.既然要在Docker容器內安裝我們的大數據平臺,那就需要一個統一的Linux系統做為我們的Dcoker容器,像Ubuntu、CentOS等發行商都會發布自己的Docker基礎鏡像到Docker Hub上,如果Docker Hub上恰好沒有你需要的鏡像,也可以自己制作。
2.比如用CentOS6.8做為我們的基礎鏡像,那么請先把它pull下來

3.然后我們用這個鏡像創建一個容器,并在里面配置一些我們大數據平臺依賴的參數,比如ntpd、httpd服務等等,最終生成我們平臺專屬的基礎鏡像。

4.這是很關鍵的一步,有了它以后,所有人員可以隨時創建一個自己需要的Linux環境出來,以便在其內進行產品的研究和實驗,且每個人的環境互不相干,當容器內的環境被破壞后,可以刪掉再創建,這樣一來,場景一和場景二所遇到的問題也就迎刃而解。
第三步:將已經部署好的集群做成鏡像
我們可以把已經部署了集群的容器保存成多種鏡像,如:只包含了Hadoop的集群、同時包含Hadoop、Zookeeper、Hbase的集群,或安裝了所有組件的集群等等,然后上傳到私有倉庫,其它人需要的時候,直接啟動自已需要的集群就可以了,因為免去了部暑與配置等步驟,因而大幅度提高了工作效率,也提高了產品迭代速度。

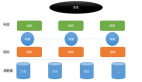
上圖是已經做好的鏡像,圖中共三種類型的鏡像:
- 第一個箭頭指基礎鏡像
- 第二個箭頭指的是已經安裝了大數據平臺的鏡像,因為是分布式,所以有五個
- 第三個是單節點版的大數據集群,所以只有一個鏡像
第四步:鏡像的修改與保存
Docker提供了commit功能可以將一個正在運行的容器保存起來,假如在測試過程中遇到一個Bug并且需要先保存下來,執行一條簡單的命令即可,如:
- # docker commit container_name image:v2
在以后需要復現的時候用這個鏡像創建容器即可,像下面這樣
- # docker run -tid –name c1 image:v2 bash
但注意,并不是所有狀態都能被保存下來,它只保存文件層面的狀態,不能保存內存中的狀態,所以再次啟動容器的時候,容器內的所有服務都已經變成了停止狀態,需要再手動啟動一次,這樣就導致有些類型的Bug不能復現。
不過欣慰的是,Docker官方打算在后面的版本中加入checkpiont功能,它可以保存容器中的所有狀態,這樣就可以完整地復現Bug,這個新功能的用法就像下面這樣:

這個功能對很多人來說,絕對是個好消息!
第五步:腳本化部署、監視、刪除
當然了,每個人都不應該把過多的精力放在怎么使用Docker的問題上,這樣會為團隊帶來額外的工作量,最簡單的辦法當然是把所有重復性的工作腳本化,向每個人提供最簡便的使用接口,只需要一條簡單的命令就可以創建自己想要的集群環境,當不需要的時候一條命令即可刪除,這樣即降低了學習成本又解決了容器管理問題。
根據筆者的實踐經驗,腳本化的實現應該著重考慮幾個方面:
- 多種類型集群的創建
- 記錄每個集群的所屬者,容器所屬的物理機,創建時間等等
- 可實時查看所有容器的運行狀態,物理機資源使用情況
- 刪除指定的集群
結語
現在已經有很多開源的Docker容器管理框架,但需求總是復雜多變的,并不能適用所有的場景。比如筆者所負責的大數據平臺就需要為每個容器做端口映射、內含大數據組件的鏡像在啟動后還需做Hostname與IP映射等,總之,目前開源容器框架的易用性還有很大的改進空間,都存在一些手動配置的工作。
關于容器服務,在具體的實踐過程中,一定還會遇到很多問題,比如服務發現和編排。當下在應用層面雖還算不上特別的成熟,但已經使原本部署與配置很復雜的大數據平臺變得簡單快速,讓一部分研發團隊的產品迭代得到加速。當然,不管是大數據平臺產品,還是Docker開源社區本身,都還在不斷的完善中。
本文由 聯想大數據團隊 投稿至36大數據,并經由36大數據編輯發布,轉載必須獲得原作者和36大數據許可,并標注來源36大數據http://www.36dsj.com/archives/75999,任何不經同意的轉載均為侵權。