













從瀏覽器到服務端的中文亂碼深入分析
概述
前段時間陸陸續續有一些同事跟我詢問中文亂碼問題,每個人的問題也都大同小異。而我最早之前也一直想寫一篇這樣的文章,無奈都騰不出富裕的時間,或者說拖延癥比較嚴重(其實還是懶),這次就索性對自己狠一把,對這個問題做一個總結。
我們知道http協議是請求-響應式的,平常出現的亂碼問題也就都隱藏在這一問一答之中,如果能明白字符在這個期間所走的鏈路,以及在這個鏈路中都經歷了怎樣的字符轉換,那么遇到任何煩人的亂碼問題也能夠迎刃而解。
下面我會根據自身工作中的經歷,講述基于http協議在開發過程中遇到的字符亂碼問題。
響應(response)時遇到的亂碼問題
兩千多年前孔子看見顏回煮飯時先偷偷吃了一些,便用言語責怪了顏回。顏回解釋并沒有偷吃,是有臟東西掉進鍋里了,他把有臟東西的飯撈出來吃掉了。后來孔子感慨,所信者目也,而目猶不可信。
當你在瀏覽器里看到響應內容是亂碼時,你會認為一定是程序吐出的字符就是亂碼,解決這個問題的辦法就是修改程序。事實真的是這樣的嗎?為了說明這個問題,我寫了一段簡單的程序用來模擬web程序,這段程序的作用就是輸出utf-8編碼的“中國”兩個字符。下面我們用火狐和chrome訪問這個程序。
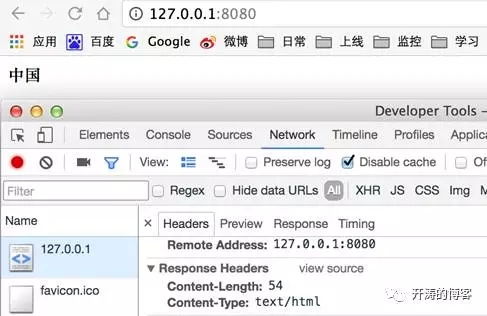
用火狐訪問http://localhost:8080
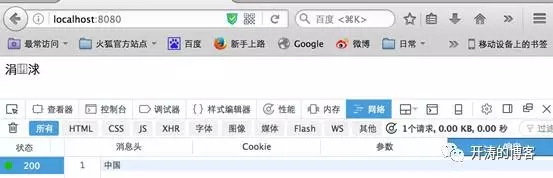
用chrome訪問http://localhost:8080
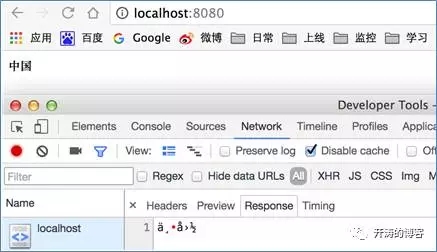
從上面可以看到,對于相同的輸出,不同的瀏覽器展現了不同的結果。Firefox在瀏覽器正文顯示的是亂碼,而在下面的“響應”標簽中顯示了正確的字符。Chrome則跟Firefox相反,正文顯示正確,標簽”response”顯示亂碼。并且兩個瀏覽器顯示的亂碼也是不一致的, firefox顯示成了三個字符,chrome則顯示成六個字符。
上面說過,我的這段web程序是將“中國”這兩個字符按照utf-8編碼輸出的,
難道是在輸出的過程中被轉換成了別的編碼?為了一探究竟我需要看到程序輸出的原始字節碼,原始字節碼用firefox和chrome自帶的工具是看不到的,這里我用wireshak分別對兩個兩個瀏覽器做了抓包。
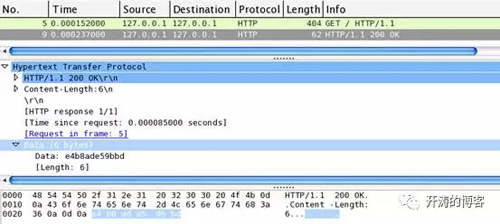
“中國”這兩個字符在utf-8編碼中對應的編碼為e4b8ad(中)、e59bbd(國),如果我們抓到的包中也看到的是這六個字節,那就說明程序的輸出是沒有問題。
對firefox的抓包:
對chrome的抓包:
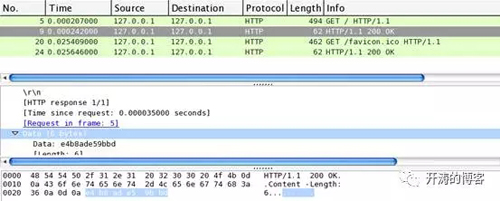
通過wireshak可以看到兩個瀏覽器的到的結果都是一樣的,Data部分都是e4b8ade59bbd,和我們的預期一致。不同的是firefox發送請求用了404個字節,chrome用了494個字節,這個其實是兩種瀏覽器在發送請求時,帶的請求頭不一樣,比如用來說明瀏覽器身份的User-Agent請求頭。
既然程序的輸出沒有問題,那就是瀏覽器為什么會展示成亂碼呢? 我們都知道http程序在吐出內容時還會攜帶一些響應頭,依次來對內容做一些說明,我們上面這段程序攜帶的響應頭如下:

可以看到只帶了一個Content-Length頭用來說明內容的字節長度,至于如何解釋這六個字節瀏覽器是不知道的,所以瀏覽器此時只能“猜測”了。首先http協議本身就是字符型協議,既然響應頭沒有更多的說明,那默認就認為輸出的內容也是字符內容了,剩下的問題就是“猜測”這六個字節是那種字符的編碼了。從chrome的顯示可以看到,chrome在瀏覽器窗口中顯示了正確的utf-8編碼,在”response”標簽中且使用了錯誤的編碼來解釋這六個字節。Firefox則正好相反,“響應”標簽中“猜”對了編碼,但是瀏覽器窗口中卻使用了錯誤的編碼。
需要注意的是這里用“猜測”這個詞其實是不準確的,實際上每個字符編碼都有其特定的規則,如果對所有字符編碼規則都很熟悉,給一段字節序,是可以推導出它的字符編碼的。
知道了問題所在解決起來就很容易了,在http協議中有一個Content-Type頭,用它可以指定內容的類型和內容的字符編碼。現在我們為輸出加上響應頭Content-Type:text/plain; charset=utf-8,分別用兩種瀏覽器訪問http://localhost:8080,看到的響應頭如下:

此時firefox的瀏覽器窗口和chrome的“response”標簽都顯示了正確的字符。
截止到目前我們得到的結論應該是這樣的,charset指定的編碼需要和輸出內容保持一致,這樣在顯示的時候才不會出現亂碼。下面我們換一種方式來訪問我們的資源,我們分別使用telnet和curl來訪問http://localhost:8080
通過Telnet來訪問:

因為我這段web程序并沒有處理任何http的請求頭,它的默認動作是只要建立好tcp連接后就直接輸出內容,所以看到在telnet的時并沒有發送任何http協議需要的請求頭,且依然可以輸出內容。
從圖中可以看到,charset=utf-8沒錯,并且我對程序沒有做任何的改動,也就是說程序輸出的編碼和Content-Type指定的編碼是一致的,但我們并沒有看到正確的字符。
通過curl來訪問:
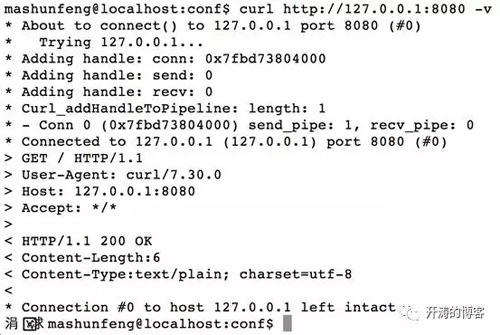
可以看到響應頭和內容顯示,跟使用telnet訪問時是一樣的,內容都出現了亂碼。
所以我們上面通過瀏覽器訪問資源所得到的,關于輸出編碼和charset保持一致就不會出現亂碼的結論是錯誤的嗎?當然不是,不過前提是結論前必須加上“瀏覽器”這個限定詞。實際上我們把http的響應分成數據獲取和數據解釋這兩個步驟就會很容易理解這問題,首先在數據獲取這個步驟中,瀏覽器、telnet、curl是沒有區別的,都是和web程序先建立tcp連接,然后獲取web程序返回的數據。不同的是在數據解釋這個步驟中,瀏覽器是符合http規范的,http規范中說響應頭Content-Type中的charset指定的編碼,就是響應內容的實際編碼,所以瀏覽器正確的顯示了字符。我們用telnet和curl演示的例子只是負責獲取數據這一個步驟,對于數據解釋這個步驟是有發起命令的終端來負責的,而終端跟http協議沒有半毛錢關系,終端只會只用預先設定的編碼規則來顯示內容。
下面是我把終端的編碼設置為utf-8,然后用curl訪問的結果:
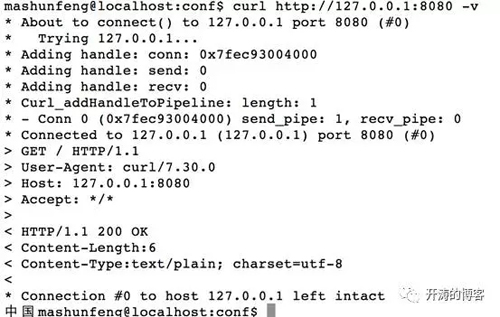
程序沒有做任何改動,但是亂碼消失了。
不在響應頭中指定編碼規則就真的不行嗎?
將程序的響應頭Content-Type設置為text/html,不設置charset,然后分別在兩個瀏覽器中訪問。
在firefox中訪問:
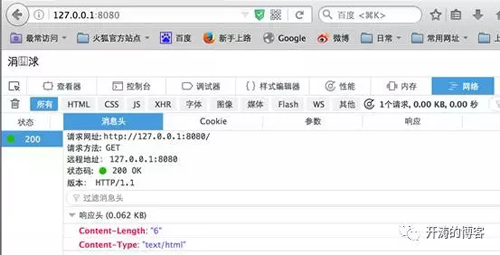
在chrome中訪問:
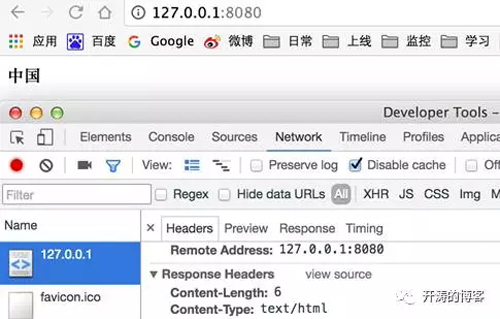
可以看到firefox中出現了亂碼,chrome中沒有。現在我們改動一下程序的輸出內容,輸出內容為:
<html><head><metacharset=”utf-8”></head>中國</html>
然后再用兩個瀏覽器分別訪問。
Firfox的訪問:

亂碼消失了。
Chrom的訪問:
顯示正確。
從上面的四張圖可以看到,我們沒有在響應頭中指定內容的編碼,但仍然沒有出現亂碼問題,原因就在Content-Type:text/html和響應內容中的<meta charset=”utf-8”>標簽,這個標簽對html內容本身做了一個自描述。想xml這種標簽語言也可以像html這樣進行自描述,也就是說對于響應是xml的內容,即使沒有charset指定編碼,xml也可以通過自描述對指定正確的編碼。
***需要注意的是,在處理不帶charset的字符內容時,瀏覽器不同處理方式也不同,即使相同瀏覽器但版本不一樣,處理方式也不一定一樣。所以我這里介紹的亂碼在你本地不一定會出現,但是為了確保所有瀏覽器不出問題,***在響應頭上加上charset并讓其和內容的實際編碼保持一致。如果提供的http資源并不是用在瀏覽器中直接訪問的,而是用來提供接口供各個系統調用的,沒有指定charset時就需要用其它方式來告知對方內容編碼。
請求(Request)過程中出現的亂碼問題
請求過程中出現亂碼時主要出現在兩個地方,一個是請求發送時所用的編碼,另一個是web應用接收到請求后解碼時所有的編碼。請求發送時用什么編碼,主要取決于發送請求所用的客戶端,這里我們以瀏覽器和telnet為客戶端來說明。Web應用層我們使用個tomcat來舉例說明,所以如果你在工作中用的不是tomcat,那么在解碼請求時會和這里介紹的解碼行為不一致,但是原理是一樣的,原理明白了也就可以觸類旁通了。
開始之前先解釋下URL的組成:
- {http://localhost:8080[/app/servletpath]}?(name=xxx)
- {}:代表URL
- []:代表URI
- ():代表查詢參數
對tomcat使用默認設置,使用如下的代碼來接收請求
- @Override
- public void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- System.out.println("name: "+req.getParameter("name"));
- System.out.println("queryString: "+req.getQueryString());
- System.out.println("pathInfo: "+req.getPathInfo());
- System.out.println("requestURL:"+req.getRequestURL());
- }
直接在chrome中輸入http://localhost:8080/app/中國?name=中國 得到的結果如下:
name: ä¸å›½
queryString:name=%E4%B8%AD%E5%9B%BD
pathInfo:/app/ä¸å›½/
requestURL: http://localhost:8080/app/%E4%B8%AD%E5%9B%BD/
從打印的信息可以知道,queryString和請求URL在發送之前chrome先把中文按照utf-8進行了百分號編碼,關于百分號編碼可以看http://deyimsf.iteye.com/blog/2312462:
從里這判斷出請求發送的時候編碼是正確的,但是在使用Request.getParameter()和Request.getPathInfo()的時候出現了解碼錯誤。在tomcat文檔中可以看到有URIEncoding一個參數,文檔對它的解釋如下:
This specifies the characterencoding used to decode the URI bytes, after %xx decoding the URL. If notspecified, ISO-8859-1 will be used.
大概意思是tomcat會使用URIEncoding指定的編碼對URI部分進行百分解碼,如果沒有指定則使用ISO-8859-1對其進行解碼。通過這段解釋可以知道,出現亂碼的原因是未用URIEncoding指定正確的編碼。下面我們將URIEncoding設置為utf-8看會出現什么結果,在tomcat的server.xml文件中配置如下:
- <Connectorport="8080" protocol="HTTP/1.1"
- connectionTimeout="20000"
- redirectPort="8443"URIEncoding="utf-8"/>
直接在chrome中輸入http://localhost:8080/app/中國?name=中國,結果如下:
name: 中國
queryString:name=%E4%B8%AD%E5%9B%BD
pathInfo: /app/中國/
requestURL:http://localhost:8080/app/%E4%B8%AD%E5%9B%BD/
可以看到亂碼消失了,并且入參name的亂碼也消失了,這說明URIEncoding對QueryString也是起作用的。
在上面的例子中我們可以看到chrome在發送請求之前,會把所有中文進行百分號編碼再發送出去,并且字符編碼使用的utf-8。實際上在生產過程中為了保證不出現亂碼,對請求進行百分號編碼(又叫URL編碼)是必須的,至于為什么要進行百分號編碼,可以看我早前寫的一遍文章http://deyimsf.iteye.com/admin/blogs/1776082:
這篇文章對為什么要百分號編碼做了一個簡單的解釋。
由于http協議只規定請求發送時應該進行編碼,并沒有規定使用哪種編碼,所以chrome的這種處理方式,并不能代表所有的瀏覽器。僅同一個請求中的URI部分和Query String部分,有些瀏覽器的編碼方式也有可能是不一樣的。比如我在工作中就遇到過URI 部分使用GBK編碼(沒有進行百分號編碼),而Query String使用的是utf-8進行百分號編碼的瀏覽器。解決這個問題的辦法就是我們在發送任何請求之前,一定要對有中文的地方使用某種字符編碼(比如utf-8)對其進行百分號編碼。
關于請求體中字符編碼的問題
我們上面說的亂碼問題都出現在URL和Query String中,還有一種容易出現亂碼的問題是在http的請求體中。使用http中的post方法提交表單就可以將入參放入到請求體中。
服務端用于接收post請求的代碼很簡單,如下:
- @Override
- public void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- System.out.println("name:"+ req.getParameter("name"));
- }
非常簡單,接收到入參之后直接在控制臺輸出。
Firefox中進行post訪問:
Chrome中進行post訪問:
然后在兩個瀏覽器中分別點擊提交按鈕。
Firefox中提交后,后臺獲得結果如下:
name: Öйú
Chrome中提交后,后臺后的結果如下:
name: 中國
兩個瀏覽器再提交后都出現了亂碼,并且出現了兩種亂碼,因為服務端的程序是一樣的,所以從這個現象我們可以推測出,兩個瀏覽器在發送請求時使用的編碼肯定是不一樣的,暫時還看不出是客戶端問題還是服務端的問題。下面我們使用wireshark來看看兩個瀏覽器在發送請求體時,使用的原始編碼是什么。
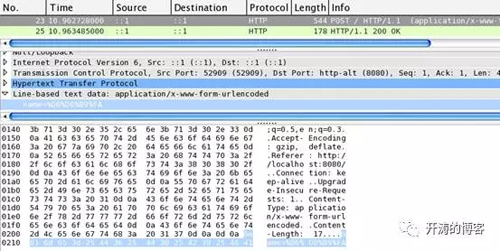
Firefox發送請求的wireshark截圖:
Chrome發送請求的wireshark截圖:
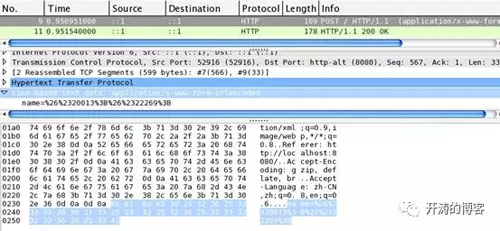
分別看兩張圖的最下面藍色區域,可以看到firefox部分是
name=%D6%D0%B9%FA
chrome的部分是
name=%26%2320013%3B%26%2322269%3B
相同的地方是兩個瀏覽器都對入參name的值做了百分號編碼,不同的是使用的字符編碼不一樣,兩個瀏覽器發送請求時,分別使用了自己認為是“正確”的字符編碼對入參做了百分號編碼。有沒有辦法讓不同的瀏覽器在發送post請求時使用同一的編碼呢?一種簡單粗暴的辦法是,我們用js來控制post提交,并且在提交前將所有的入參都按照統一的字符編碼(如utf-8編碼)做百分號編碼。
現在來看看另一種辦法,上面我們在對請求提交之前為兩個瀏覽器分別截了兩張圖,可以看到在firefox和chrome獲取表單后的http響應頭,這兩張圖的分別只有三個同樣的響應頭Server、Content-Length、Date,現在我們為這個http響應增加一個Content-Type:text/html; charset=utf-8,然后分別在兩個瀏覽器中輸入”中國”并按提交按鈕。
此時可以看到,兩個瀏覽器發送的請求提都變成了
name=%E4%B8%AD%E5%9B%BD
即urf-8形式的百分號編碼。
兩個瀏覽器提交后,后臺獲得的數據是
name:ä¸å›½
還是亂碼,只不過現在亂的一樣了。
這里我們后臺獲取入參值的時候,使用了和前面獲取Query String中的入參時一樣的方法, Request.getParameter(),tomcat中的URIEncoding設置和前面是一致的,用的是utf-8編碼。瀏覽器發送請求使用的是同樣編碼規則,后臺接收參數也是使用的同樣的方法,唯一不同的是http請求方法不一樣,一個get,一個是post。所以到這里可以得出一個結論,URIEncoding對post方式不起作用。這里需要用到Request.setCharsetEncoding()方法,這個方法只對請求體起作用。
服務端代碼變成如下形式:
- @Override
- public void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- req.setCharacterEncoding("utf-8");
- System.out.println("name: "+req.getParameter("name"));
- }
注意Request.setCharsetEncoding()方法一定要放在所有Request.getParameter()等方法之前。
使用Content-Type請求頭指定字符編碼
前面我們一直使用Content-Type作為響應頭,來明確響應內容的字符編碼,其實這http協議頭也可以用在請求中,可以用來指定請求體中的字符編碼。
現在我們將服務端的中的Request.setCharacterEncoding()部分注釋掉,我們使用telnet程序來模擬瀏覽器發送請求,模擬操作如下:
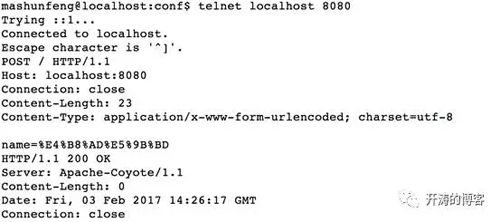
可以看到為Content-Type頭增加了charset=utf-8設置。
這時候在看后端打印出了正確的編碼:
name:中國
***的出的結論是,http使用post方式提交表單時,發送請求所使用的編碼由響應頭Content-Type中的charset決定,如果在獲取表單的響應中沒有設置charset,則瀏覽器根據自身“喜好”來決定。服務器端在解析請求體內容時,解碼編碼用Request.setCharsetEncoding()方法(j2ee)或者請求頭Content-Type來指定。
關于ISO8859-1的問題
前面我們介紹了三種設置服務端解析字符的編碼方式,以此來避免解碼過程中出現的亂碼問題,分別是URIEncoding、setCharsetEncoding()、Content-Type。如果不用這三種方式,那么對于tomcat來說,它會默認使用ISO8859-1對字符做解碼。
服務端程序做如下改造:
- @Override
- public void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- System.out.println("name: "+newString(req.getParameter("name").getBytes("iso8859-1"),"utf-8"));
- }
- @Override
- public void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- doGet(req, resp);
- }
客戶端我們使用chrome瀏覽器:
![]()
其它地方用默認值,這其中包括tomcat中不設置URIEncodng,代碼中沒有Reqeust.setCharsetEncodnig(),請求頭Content-Type中沒有charset。然后用我們前面提到的所有訪問方式,比如多種瀏覽器的get請求、多種瀏覽器的post請求,前提是發送請求時一定要對中文做百分號編碼。所有這些方式都試過一遍之后你會發現,不管哪種方式,只要入參name的值使用的是utf-8編碼(后臺的doGet方法里用的是utf-8,需要和這里保持一致),后臺都不會出現亂碼。是不是感覺很神(詭)奇(異)。下面我們通過走進字符編碼的***層,來一起剖析這個神奇的現象。
如果一個字符從輸入到輸出出現了亂碼,那么在這個輸入輸出的中間過程中一定發生過編碼轉換。對于我們當前的測試用例,發生了六次編碼轉換:
- 瀏覽器對字符做百分號編碼
- Tomcat解百分號編碼
- ISO8859-1編碼轉Java內碼
- Java內碼轉ISO8859-1編碼
- 把字節數組當成utf-8編碼轉Java內碼
- Java內碼轉輸出編碼
開始解釋這六次編碼轉換之前,先明確一些描述規則。
- 字符:直接用其字面意思來書寫,比如字符”a”、”中”等
- 字節:用16進制加上前綴0x表示,比如ascii字符”a”字節表示就是0x61
- String.getBytes(“utf-8”):把java內碼轉成utf-8編碼
- newString(bytes[],”utf-8”): 把字節數組當成utf-8編碼-轉成java內碼
瀏覽器對字符做百分號編碼
前面我們已經知道,對于”中國”這兩個字符,他們的utf-8編碼分別是0xE4B8AD、0xE59BBD,每個字符占用三個字節。經過百分號編碼后變成了%E4%B8%AD、%E5%9B%BD,可以看到百分號編碼對原始編碼是無損的,它只是把原始字節變成了%+原始字節的16進制表示。比如字節0xE4,轉成百分號編碼為%E4,有一個字節變成了三個字節。
Tomcat解碼百分號編碼
解碼百分號編碼也很簡單,其實就是去掉百分號,然后將百分號后的兩個字節合并成一個字節,如百分號編碼%E4,解碼后變為字節0xE4。到這一步“中國”這兩個字符就變成了0xE4B8AD、0xE59BBD。
ISO8859-1轉java內碼
ISO8859-1可以簡單理解為ascii的升級版本,我們知道ascii只用到了一個字節中的后7位,高位始終是0,所以它最多可以表示128個字符。ISO8859-1可ascii一樣都是單字節字符集,不同的是它把***位利用起來了,增加了一些西方字符(如±、÷等字符)。
我們這里說的java內碼是java程序運行時,在內存中存儲字符的編碼,用的是unicode標準中定義的utf-16編碼。在java中處理字符就是各種字符編碼轉java內碼,java內碼再轉各種字符編碼。舉一個簡單的例子,java處理字符類似翻譯官翻譯語言。比如一個母語是漢語,精通日語和英語的翻譯官,他在將日語轉成英語或英語轉成日語時,一定會先別他們轉成母語,然后再轉成其它語言。看到這里你有可能會說,厲害的翻譯官不需要轉成母語,或者翻譯官的母語也不是一種,有可能好多種。但是目前我們的大部分計算機語言就只有一種母語。
ISO8859-1和java內碼(utf-16)介紹完了就可以說轉換的問題了。utf-16是一個把Unicode碼點值編碼成16位(兩個字節)整數的序列,它會把unicode字符編碼成2字節或四字節。前面說了ISO8859-1是8位長的單字節字符編碼,所以utf-16編碼和ISO8859-1編碼是不兼容的,但是utf-16包含ISO8859-1中的所有字符,所以他們的編碼之間也是有對應關系的。
在上面第2步(Tomcat解碼百分號編碼)后,“中國”這兩個字符在內存中是這樣的0xE4B8ADE59BBD,正好六個字節。我們知道這其實是這兩個字符的utf-8編碼序列,但是由于我們并沒有告訴tomcat這是什么字符編碼序列,所以tomcat就認為這是一個ISO8859-1編碼序列,并把它告訴了java程序,java程序要做的就是把這個字節序列按照ISO8859-1轉換成utf-16,轉換成功后的對應關系是這樣的:
|
ISO8859-1 |
0xE4 |
0xB8 |
0xAD |
0xE5 |
0x9B |
0xBD |
|
UTF-16 |
0x00E4 |
0x00B8 |
0x00AD |
0x00E5 |
0x009B |
0x00BD |
可以看到原本的兩個字符,在java中變成了六個字符;原本的六個字節,在java中變成了12個字節。
Java內碼轉換成ISO8859-1編碼
這一步驟實際上是在執行我們例子程序中
- System.out.println("name: "+newString(req.getParameter("name").getBytes("iso8859-1"),"utf-8"));
getBytes(“iso8859-1”)這個方法,也就是把utf-16轉換成ISO8859-1。有第三步(ISO8859-1轉java內碼)中的對應表格可以看到,utf-16轉ISO8859-1只需要把每個字符前面的8位0去掉就可以了,轉換成功后倆個字符就又變成了0xE4B8ADE59BBD。雖然兩次轉換過程中,對字節的解釋是錯誤的,但是并沒有丟失原始字節信息。
把字節數組當成utf-8編碼轉java內碼
這一步執行的是上面例子程序中的new String(0xE4B8ADE59BBD,”utf-8”)方法,因為我們的字節數組本來就是utf-8編碼,所以按照utf-8來轉碼肯定是沒問題的,轉換成功后的對應關系是這一樣的:
|
UTF-8 |
0xE4B8AD |
0xE59BBD |
|
UTF-16 |
0x4E2D |
0x56FD |
到這里“中國”這兩個字符在java內部才得到了正確的表示。
Java內碼轉輸出編碼
這一步執行的是上面例子程序中的System.out.println(“中國”)方法,現在“中國”這兩個字符在java內部用utf-16得到了正確的表示,剩下的***一步就是對外輸出,也就是對外翻譯的過程,我們這里用的java自帶的println方法,這個方法會根據當前平臺的自身編碼進行輸出,比如你的平臺環境是中文,那輸出的可能就是GBK編碼。如果你不想用平臺編碼,想自己決定輸出編碼,很簡單
System.out.write(“中國”.getByte(“字符編碼”));
這樣就可以了。
【本文來自51CTO專欄作者張開濤的微信公眾號(開濤的博客),公眾號id: kaitao-1234567】












