雅虎BigML團隊開源大數據分布式深度學習框架TensorFlowOnSpark
近幾年,深度學習發展的非常迅速。在雅虎,我們發現,為了從海量數據中獲得洞察力,需要部署分布式深度學習。現有的深度學習框架常常要求為深度學習單獨設定集群,迫使我們要為一個機器學習流程(見下圖 1)創建多個程序。
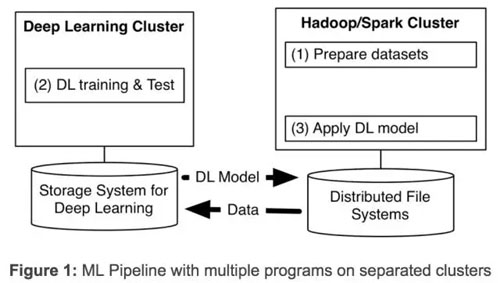
設定獨立的集群則需要我們轉移大數據集,帶來了不必要的系統復雜性和端到端的學習延遲。
去年我們通過開發和公開 CaffeOnSpark 解決了 scaleout 的問題,我們開源的框架支持在相同的 Spark 和 Hadoop 集群上進行分布式深度學習和大數據處理。我們在雅虎內部使用 CaffeOnSpark 改善了我們的 NSFW 圖像檢測,自動從實況錄像中識別電競比賽片段等等。在社區大量有價值的反饋和貢獻下,CaffeOnSpark 已經得到了更新,現在可以支持 LSTM,有了一個新的數據層,可以訓練與測試交錯,有了一個 Python API,和 Docker container 的部署。這些都提升了我們的用戶體驗。但是那些使用 TensorFlow 框架的人怎么辦?于是我們效仿了之前的做法,開發了 TensorFlowOnSpark。
TensorFlow 公開后,谷歌于 2016 年 4 月就開放了一個帶有分布式學習功能的增強版 TensorFlow。2016 年 10 月,TensorFlow 開始支持 HDFS。然而在谷歌云之外,用戶仍然需要一個 TensorFlow 應用的專用集群。TensorFlow 程序無法在現有的大數據集群上部署,這樣一來,那些想大規模使用這個技術的人就需要花更多的成本和時間。
為了打破這個限制,幾個社區項目將 TensorFlow 連接到 Spark 集群上。SparkNet 讓 Spark 執行器獲得了可以運行 TensorFlow 網絡的能力。DataBricks 提出 tensorframe,用來使用 TensorFlow 程序操縱 Apache Spark 的數據幀。雖然這些方法都朝著正確的方向邁出了一步,但是我們檢查他們的代碼后發現,我們無法讓多個 TensorFlow 過程直接相互溝通,我們也無法實現異步分布式學習,并且我們需要在遷移現有的 tensorflow 程序上花大功夫。
TensorFlowOnSpark
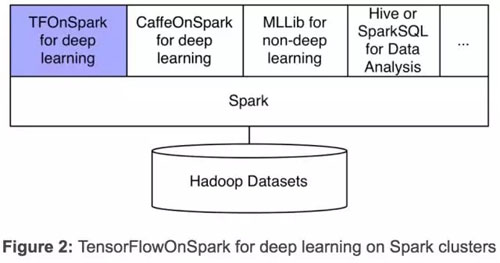
我們的新框架,TensorFlowOnSpark(TFoS),支持 TensorFlow 在 Spark 和 Hadoop 上的分布式運行。如上圖(圖 2)所示,TFoS 與 SparkSQL、MLlib 以及其他的 Spark 庫一起在一個項目或線程(pipeline)中運行。
TFoS 支持所有類型的 TensorFlow 程序,能實現同步和異步的訓練與推理。并且支持模型和數據的平行處理,以及 TensorFlow 工具(如 TensorBoard)在 Spark 群集上使用。
任何 TensorFlow 程序都能夠很容易通過修改實現在 TFoS 上運行的。通常情況下,只需要修改少于 10 行的 Python 代碼。很多在雅虎平臺上使用 TensorFlow 的開發者,已經輕松將 TensorFlow 項目轉移到 TFoS 上執行了。
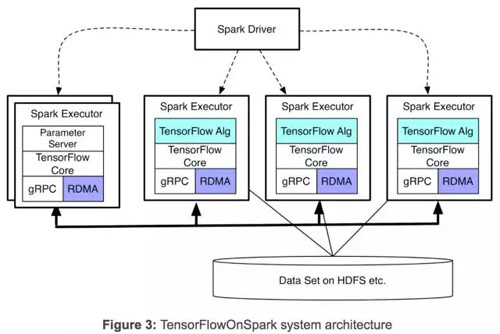
TFoS 支持張量(tensor)在 TensorFlow 處理過程中(計算節點和參數服務節點)信息的直接溝通。過程到過程(Process-to-process)的直接溝通機制使 TFoS 項目很容易在增加的機器上進行擴展。如圖 3 所示,TFoS 不需要 Spark 驅動器(driver)參與到張量溝通中來,因此也就與具備類似于獨立 TensorFlow 群集的擴展能力。
TFoS 提供兩種不同模式來「吞入」用于訓練和推理的數據 :
1. TensorFlow QueueRunners:TFoS 利用 TensorFlow 的文件讀取(file readers)和 QueueRunners 來直接從 HDFS 文件中讀入數據。在數據獲取過程中不需要 Spark 參與。
2. Spark 供給:Spark RDD 數據將會被傳輸至每一個 Spark 執行器里,Spark 執行器會進一步將數據傳入 TensorFlow 圖(通過 feed_dict 參數)。
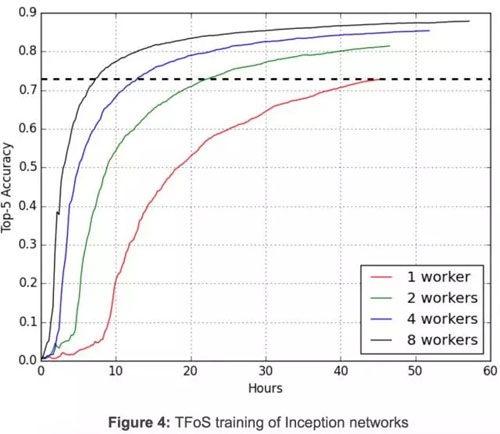
圖 4 展示了 Inception 圖像分類網絡中同時進行的分布式訓練如何在 TFoS 中通過 QueueRunners 的一個簡單設置進行擴展:將每個計算節點設置為 1 個 GPU,一個讀入(reader)以及批處理數為 32。四個 TFoS 的任務同時進行以用于訓練 10 萬步。兩天多后,當這些任務完成時,top-5 精確度(accuracy)分別為 0.730, 0.814, 0.854,0.879。0.730 的精確度需要單計算節點運行 46 小時得到,雙計算節點需要 22.5 個小時,4 計算機點需要 13 小時,8 計算節點需要 7.5 個小時。在 Inception 模型訓練上,TFoS 幾乎能達到線性擴展。這是很鼓舞人心的,雖然 TFoS 在不同模型和超參數上的擴展能力不同。
用于分布式 TensorFlow 的 RDMA
在雅虎的 Hadoop 集群上,GPU 節點通過以太網和無線寬帶相互連接。無線寬帶提供了高速的連接,并支持在 RDMA 中直接訪問其他服務器的存儲。然而目前 TensorFlow 僅支持在以太網上使用 「gRPC」 的分布式學習。為了加速分布式學習,我們增強了 TensorFlowC++層,實現了無線寬帶上的 RDMA。
為了結合我們發布的 TFoS,我們在 default「gRPC」協議之外,引進了一個新的 TensorFlow 服務器協議。任何分布式 tensorflow 程序都能通過指定 protocol=「grpc_rdma」in tf.train.ServerDef()or tf.train.Server() 來使用我們的增強版的 TensorFlow。
有了這個新協議后,就需要一個 RDMA 匯集管理器(rendezvous manager)來確保張量直接寫入遠程服務器的內存。我們最大限度地減少張量緩沖的創建:張量緩沖器在開始時分配一次,然后在一個 TensorFlow 工作任務的所用訓練步驟中重復使用。從我們早期的大型模型實驗,比如 VGG-19 開始,我們的就已經證明了,與現有的 gRPC 相比,我們的 RDMA 實現在訓練時間上帶來了顯著的提速。
由于 RDMA 支持對性能要求很高(見 TensorFlow issue#2916),我們決定讓我們現有的實現版本作為一個預覽版向 TensorFlow 社區開放。在未來的幾周內,我們將會進一步優化我們的 RDMA 實現,并分享一些基準結果細節。
簡單的 CLI 和 API
TFoS 程序是通過標準的 ApacheSpark 命令 spark-submit 運行的。如下所示,用戶可以在 CLI 中指定 Spark 執行器的數目,每個執行器所用的 GPU 數目以及參數服務節點數。用戶還可以表明愿意使用 TensorBoard(–tensorboard)還是 RDMA(–rdma)。
- spark-submit –master ${MASTER} \
- ${TFoS_HOME}/examples/slim/train_image_classifier.py \
- –model_name inception_v3 \
- –train_dir hdfs://default/slim_train \
- –dataset_dir hdfs://default/data/imagenet \
- –dataset_name imagenet \
- –dataset_split_name train \
- –cluster_size ${NUM_EXEC} \
- –num_gpus ${NUM_GPU} \
- –num_ps_tasks ${NUM_PS} \
- –sync_replicas \
- –replicas_to_aggregate ${NUM_WORKERS} \
- –tensorboard \
- –rdma
TFoS 提供高層次的 Python API(在 Python notebook 的范例中有顯示):
- TFCluster.reserve()... 從 Spark 執行器構建一個 TensorFlow 群集
- TFCluster.start()... 在執行器上加載 TensorFlow 程序
- TFCluster.train() or TFCluster.inference() …將 RDD 數據傳入 TensorFlow 處理
- TFCluster.shutdown() …在執行器中結束 TensorFlow 的運行
開源
- TensorFlowOnSpark 開源地址: github.com/yahoo/TensorFlowOnSpark
- RDMA 增強版開源地址: github.com/yahoo/tensorflow/tree/yahoo
- 提供多示例程序(包括 MNIST,Cifar10,Inception,and VGG)以說明 TensorFlow 程序到TensorFlowOnspar轉換過程,并且利用 RDMA。地址:https://github.com/yahoo/TensorFlowOnSpark/tree/master/examples
- 提供一張亞馬遜機器圖像用于在 AWS EC2 上應用 TensorFlowOnSpark。接著,與 CaffeOnSpark 一樣,我們會推進 TensorFlowOnSpark。地址:https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_EC2
【本文是51CTO專欄機構機器之心的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】