HBase最佳實(shí)踐-寫性能優(yōu)化策略
本篇文章來說道說道如何診斷HBase寫數(shù)據(jù)的異常問題以及優(yōu)化寫性能。和讀相比,HBase寫數(shù)據(jù)流程倒是顯得很簡單:數(shù)據(jù)先順序?qū)懭際Log,再寫入對應(yīng)的緩存Memstore,當(dāng)Memstore中數(shù)據(jù)大小達(dá)到一定閾值(128M)之后,系統(tǒng)會(huì)異步將Memstore中數(shù)據(jù)flush到HDFS形成小文件。
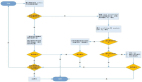
HBase數(shù)據(jù)寫入通常會(huì)遇到兩類問題,一類是寫性能較差,另一類是數(shù)據(jù)根本寫不進(jìn)去。這兩類問題的切入點(diǎn)也不盡相同,如下圖所示:
寫性能優(yōu)化切入點(diǎn)
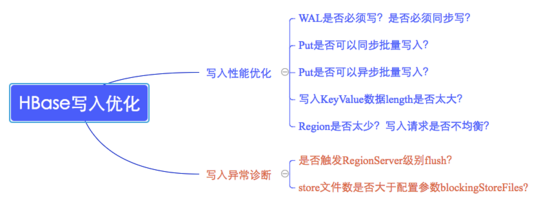
1. 是否需要寫WAL?WAL是否需要同步寫入?
優(yōu)化原理:數(shù)據(jù)寫入流程可以理解為一次順序?qū)慦AL+一次寫緩存,通常情況下寫緩存延遲很低,因此提升寫性能就只能從WAL入手。WAL機(jī)制一方面是為了確保數(shù)據(jù)即使寫入緩存丟失也可以恢復(fù),另一方面是為了集群之間異步復(fù)制。默認(rèn)WAL機(jī)制開啟且使用同步機(jī)制寫入WAL。首先考慮業(yè)務(wù)是否需要寫WAL,通常情況下大多數(shù)業(yè)務(wù)都會(huì)開啟WAL機(jī)制(默認(rèn)),但是對于部分業(yè)務(wù)可能并不特別關(guān)心異常情況下部分?jǐn)?shù)據(jù)的丟失,而更關(guān)心數(shù)據(jù)寫入吞吐量,比如某些推薦業(yè)務(wù),這類業(yè)務(wù)即使丟失一部分用戶行為數(shù)據(jù)可能對推薦結(jié)果并不構(gòu)成很大影響,但是對于寫入吞吐量要求很高,不能造成數(shù)據(jù)隊(duì)列阻塞。這種場景下可以考慮關(guān)閉WAL寫入,寫入吞吐量可以提升2x~3x。退而求其次,有些業(yè)務(wù)不能接受不寫WAL,但可以接受WAL異步寫入,也是可以考慮優(yōu)化的,通常也會(huì)帶來1x~2x的性能提升。
優(yōu)化推薦:根據(jù)業(yè)務(wù)關(guān)注點(diǎn)在WAL機(jī)制與寫入吞吐量之間做出選擇
其他注意點(diǎn):對于使用Increment操作的業(yè)務(wù),WAL可以設(shè)置關(guān)閉,也可以設(shè)置異步寫入,方法同Put類似。相信大多數(shù)Increment操作業(yè)務(wù)對WAL可能都不是那么敏感~
2. Put是否可以同步批量提交?
優(yōu)化原理:HBase分別提供了單條put以及批量put的API接口,使用批量put接口可以減少客戶端到RegionServer之間的RPC連接數(shù),提高寫入性能。另外需要注意的是,批量put請求要么全部成功返回,要么拋出異常。
優(yōu)化建議:使用批量put進(jìn)行寫入請求
3. Put是否可以異步批量提交?
優(yōu)化原理:業(yè)務(wù)如果可以接受異常情況下少量數(shù)據(jù)丟失的話,還可以使用異步批量提交的方式提交請求。提交分為兩階段執(zhí)行:用戶提交寫請求之后,數(shù)據(jù)會(huì)寫入客戶端緩存,并返回用戶寫入成功;當(dāng)客戶端緩存達(dá)到閾值(默認(rèn)2M)之后批量提交給RegionServer。需要注意的是,在某些情況下客戶端異常的情況下緩存數(shù)據(jù)有可能丟失。
優(yōu)化建議:在業(yè)務(wù)可以接受的情況下開啟異步批量提交
使用方式:setAutoFlush(false)
4. Region是否太少?
優(yōu)化原理:當(dāng)前集群中表的Region個(gè)數(shù)如果小于RegionServer個(gè)數(shù),即Num(Region of Table) < Num(RegionServer),可以考慮切分Region并盡可能分布到不同RegionServer來提高系統(tǒng)請求并發(fā)度,如果Num(Region of Table) > Num(RegionServer),再增加Region個(gè)數(shù)效果并不明顯。
優(yōu)化建議:在Num(Region of Table) < Num(RegionServer)的場景下切分部分請求負(fù)載高的Region并遷移到其他RegionServer;
5. 寫入請求是否不均衡?
優(yōu)化原理:另一個(gè)需要考慮的問題是寫入請求是否均衡,如果不均衡,一方面會(huì)導(dǎo)致系統(tǒng)并發(fā)度較低,另一方面也有可能造成部分節(jié)點(diǎn)負(fù)載很高,進(jìn)而影響其他業(yè)務(wù)。分布式系統(tǒng)中特別害怕一個(gè)節(jié)點(diǎn)負(fù)載很高的情況,一個(gè)節(jié)點(diǎn)負(fù)載很高可能會(huì)拖慢整個(gè)集群,這是因?yàn)楹芏鄻I(yè)務(wù)會(huì)使用Mutli批量提交讀寫請求,一旦其中一部分請求落到該節(jié)點(diǎn)無法得到及時(shí)響應(yīng),就會(huì)導(dǎo)致整個(gè)批量請求超時(shí)。因此不怕節(jié)點(diǎn)宕掉,就怕節(jié)點(diǎn)奄奄一息!
優(yōu)化建議:檢查RowKey設(shè)計(jì)以及預(yù)分區(qū)策略,保證寫入請求均衡。
6. 寫入KeyValue數(shù)據(jù)是否太大?
KeyValue大小對寫入性能的影響巨大,一旦遇到寫入性能比較差的情況,需要考慮是否由于寫入KeyValue數(shù)據(jù)太大導(dǎo)致。KeyValue大小對寫入性能影響曲線圖如下:
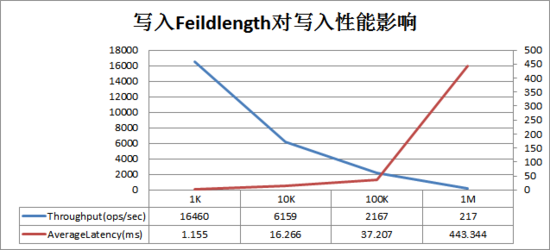
圖中橫坐標(biāo)是寫入的一行數(shù)據(jù)(每行數(shù)據(jù)10列)大小,左縱坐標(biāo)是寫入吞吐量,右坐標(biāo)是寫入平均延遲(ms)。可以看出隨著單行數(shù)據(jù)大小不斷變大,寫入吞吐量急劇下降,寫入延遲在100K之后急劇增大。
說到這里,有必要和大家分享兩起在生產(chǎn)線環(huán)境因?yàn)闃I(yè)務(wù)KeyValue較大導(dǎo)致的嚴(yán)重問題,一起是因?yàn)榇笞侄螛I(yè)務(wù)寫入導(dǎo)致其他業(yè)務(wù)吞吐量急劇下降,另一起是因?yàn)榇笞侄螛I(yè)務(wù)scan導(dǎo)致RegionServer宕機(jī)。
案件一:大字段寫入導(dǎo)致其他業(yè)務(wù)吞吐量急劇下降
部分業(yè)務(wù)反饋集群寫入忽然變慢、數(shù)據(jù)開始堆積的情況,查看集群表級別的數(shù)據(jù)讀寫QPS監(jiān)控,發(fā)現(xiàn)問題的***個(gè)關(guān)鍵點(diǎn):業(yè)務(wù)A開始寫入之后整個(gè)集群其他部分業(yè)務(wù)寫入QPS都幾乎斷崖式下跌,初步懷疑黑手就是業(yè)務(wù)A。
下圖是當(dāng)時(shí)業(yè)務(wù)A的寫入QPS(事后發(fā)現(xiàn)腦殘忘了截取其他表QPS斷崖式下跌的慘象),但是***感覺是QPS并不高啊,憑什么去影響別人!
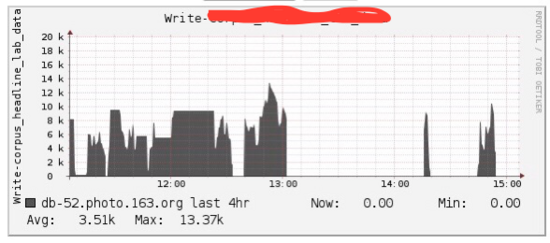
于是就繼續(xù)查看其他監(jiān)控信息,首先確認(rèn)系統(tǒng)資源(主要是IO)并沒有到達(dá)瓶頸,其次確認(rèn)了寫入的均衡性,直至看到下圖,才追蹤到影響其他業(yè)務(wù)寫入的第二個(gè)關(guān)鍵點(diǎn):RegionServer的handler(配置150)被殘暴耗盡:
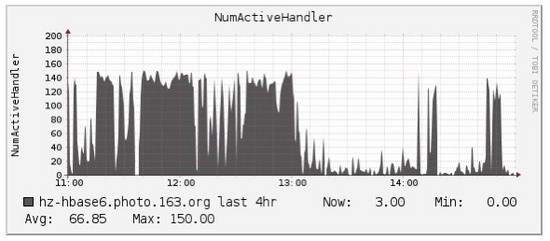
對比上面兩張圖,是不是發(fā)現(xiàn)出奇的一致,那就可以基本確認(rèn)是由于該業(yè)務(wù)寫入導(dǎo)致這臺(tái)RegionServer的handler被耗盡,進(jìn)而其他業(yè)務(wù)拿不到handler,自然寫不進(jìn)去。那問題來了,為什么會(huì)這樣?正常情況下handler在處理完客戶端請求之后會(huì)立馬釋放,唯一的解釋是這些請求的延遲實(shí)在太大。
試想,我們?nèi)h堡店排隊(duì)買漢堡,有150個(gè)窗口服務(wù),正常情況下大家買一個(gè)很快,這樣150個(gè)窗口可能只需要50個(gè)服務(wù)。假設(shè)忽然來了一批大漢,要定制超大漢堡,好了,所有的窗口都工作起來,而且因?yàn)榇鬂h堡不好制作導(dǎo)致服務(wù)很慢,這樣必然會(huì)導(dǎo)致其他排隊(duì)的用戶長時(shí)間等待,直至超時(shí)。
可回頭一想這可是寫請求啊,怎么會(huì)有這么大的請求延遲!和業(yè)務(wù)方溝通之后確認(rèn)該表主要存儲(chǔ)語料庫文檔信息,都是平均100K左右的數(shù)據(jù),是不是已經(jīng)猜到了結(jié)果,沒錯(cuò),就是因?yàn)檫@個(gè)業(yè)務(wù)KeyValue太大導(dǎo)致。KeyValue太大會(huì)導(dǎo)致HLog文件寫入頻繁切換、flush以及compaction頻繁觸發(fā),寫入性能急劇下降。
目前針對這種較大KeyValue寫入性能較差的問題還沒有直接的解決方案,好在社區(qū)已經(jīng)意識到這個(gè)問題,在接下來即將發(fā)布的下一個(gè)大版本HBase 2.0.0版本會(huì)針對該問題進(jìn)行深入優(yōu)化,詳見 HBase MOB ,優(yōu)化后用戶使用HBase存儲(chǔ)文檔、圖片等二進(jìn)制數(shù)據(jù)都會(huì)有***的性能體驗(yàn)。
案件二:大字段scan導(dǎo)致RegionServer宕機(jī)
案件現(xiàn)場:有段時(shí)間有個(gè)0.98集群的RegionServer經(jīng)常頻繁宕機(jī),查看日志是由于”java.lang.OutOfMemoryError: Requested array size exceeds VM limit”,如下圖所示:

原因分析:通過查看源碼以及相關(guān)文檔,確認(rèn)該異常發(fā)生在scan結(jié)果數(shù)據(jù)回傳給客戶端時(shí)由于數(shù)據(jù)量太大導(dǎo)致申請的array大小超過JVM規(guī)定的***值( Interge.Max_Value-2)。造成該異常的兩種最常見原因分別是:
表列太寬(幾十萬列或者上百萬列),并且scan返回沒有對列數(shù)量做任何限制,導(dǎo)致一行數(shù)據(jù)就可能因?yàn)榘罅苛卸鴶?shù)據(jù)超過array大小閾值
KeyValue太大,并且scan返回沒有對返回結(jié)果大小做任何限制,導(dǎo)致返回?cái)?shù)據(jù)結(jié)果大小超過array大小閾值
有的童鞋就要提問啦,說如果已經(jīng)對返回結(jié)果大小做了限制,在表列太寬的情況下是不是就可以不對列數(shù)量做限制呢。這里需要澄清一下,如果不對列數(shù)據(jù)做限制,數(shù)據(jù)總是一行一行返回的,即使一行數(shù)據(jù)大小大于設(shè)置的返回結(jié)果限制大小,也會(huì)返回完整的一行數(shù)據(jù)。在這種情況下,如果這一行數(shù)據(jù)已經(jīng)超過array大小閾值,也會(huì)觸發(fā)OOM異常。
解決方案:目前針對該異常有兩種解決方案,其一是升級集群到1.0,問題都解決了。其二是要求客戶端訪問的時(shí)候?qū)Ψ祷亟Y(jié)果大小做限制(scan.setMaxResultSize(2*1024*1024))、并且對列數(shù)量做限制(scan.setBatch(100)),當(dāng)然,0.98.13版本以后也可以對返回結(jié)果大小在服務(wù)器端進(jìn)行限制,設(shè)置參數(shù)hbase.server.scanner.max.result.size即可
寫異常問題檢查點(diǎn)
上述幾點(diǎn)主要針對寫性能優(yōu)化進(jìn)行了介紹,除此之外,在一些情況下還會(huì)出現(xiàn)寫異常,一旦發(fā)生需要考慮下面兩種情況(GC引起的不做介紹):
Memstore設(shè)置是否會(huì)觸發(fā)Region級別或者RegionServer級別flush操作?
問題解析:以RegionServer級別flush進(jìn)行解析,HBase設(shè)定一旦整個(gè)RegionServer上所有Memstore占用內(nèi)存大小總和大于配置文件中upperlimit時(shí),系統(tǒng)就會(huì)執(zhí)行RegionServer級別flush,flush算法會(huì)首先按照Region大小進(jìn)行排序,再按照該順序依次進(jìn)行flush,直至總Memstore大小低至lowerlimit。這種flush通常會(huì)block較長時(shí)間,在日志中會(huì)發(fā)現(xiàn)“ Memstore is above high water mark and block 7452 ms”,表示這次flush將會(huì)阻塞7s左右。
問題檢查點(diǎn):
Region規(guī)模與Memstore總大小設(shè)置是否合理?如果RegionServer上Region較多,而Memstore總大小設(shè)置的很小(JVM設(shè)置較小或者upper.limit設(shè)置較小),就會(huì)觸發(fā)RegionServer級別flush。集群規(guī)劃相關(guān)內(nèi)容可以參考文章《》
列族是否設(shè)置過多,通常情況下表列族建議設(shè)置在1~3個(gè)之間,***一個(gè)。如果設(shè)置過多,會(huì)導(dǎo)致一個(gè)Region中包含很多Memstore,導(dǎo)致更容易觸到高水位upperlimit
Store中HFile數(shù)量是否大于配置參數(shù)blockingStoreFile?
問題解析:對于數(shù)據(jù)寫入很快的集群,還需要特別關(guān)注一個(gè)參數(shù):hbase.hstore.blockingStoreFiles,此參數(shù)表示如果當(dāng)前hstore中文件數(shù)大于該值,系統(tǒng)將會(huì)強(qiáng)制執(zhí)行compaction操作進(jìn)行文件合并,合并的過程會(huì)阻塞整個(gè)hstore的寫入。通常情況下該場景發(fā)生在數(shù)據(jù)寫入很快的情況下,在日志中可以發(fā)現(xiàn)” Waited 3722ms on a compaction to clean up ‘too many store files “
問題檢查點(diǎn):
參數(shù)設(shè)置是否合理? hbase.hstore.compactionThreshold表示啟動(dòng)compaction的***閾值,該值不能太大,否則會(huì)積累太多文件,一般建議設(shè)置為5~8左右。 hbase.hstore.blockingStoreFiles默認(rèn)設(shè)置為7,可以適當(dāng)調(diào)大一些。
寫性能還能再提高么?
上文已經(jīng)從寫性能優(yōu)化以及寫異常診斷兩個(gè)方面對HBase中數(shù)據(jù)寫入可能的問題進(jìn)行了詳細(xì)的解釋,相信在0.98版本的基礎(chǔ)上對寫入來說已經(jīng)是***的解決方案了。但是有些業(yè)務(wù)可能依然覺得不夠快,畢竟”更快”是所有存儲(chǔ)系統(tǒng)活著的動(dòng)力,那還有提高空間嗎?當(dāng)然,接下來簡單介紹HBase之后版本對寫性能優(yōu)化的兩點(diǎn)核心改進(jìn):
Utilize Flash storage for WAL(HBASE-12848)
這個(gè)特性意味著可以將WAL單獨(dú)置于SSD上,這樣即使在默認(rèn)情況下(WALSync),寫性能也會(huì)有很大的提升。需要注意的是,該特性建立在HDFS 2.6.0+的基礎(chǔ)上,HDFS以前版本不支持該特性。具體可以參考官方j(luò)ira: https://issues.apache.org/jira/browse/HBASE-12848
Multiple WALs(HBASE-14457)
該特性也是對WAL進(jìn)行改造,當(dāng)前WAL設(shè)計(jì)為一個(gè)RegionServer上所有Region共享一個(gè)WAL,可以想象在寫入吞吐量較高的時(shí)候必然存在資源競爭,降低整體性能。針對這個(gè)問題,社區(qū)小伙伴(阿里巴巴大神)提出Multiple WALs機(jī)制,管理員可以為每個(gè)Namespace下的所有表設(shè)置一個(gè)共享WAL,通過這種方式,寫性能大約可以提升20%~40%左右。具體可以參考官方j(luò)ira: https://issues.apache.org/jira/browse/HBASE-14457
好了,這篇文章和大家一起分享了個(gè)人對HBase寫入性能優(yōu)化以及寫入異常問題的一些理解,如有紕漏,還望指正!另外,如果大家有任何關(guān)于此話題的案例也很歡迎一起討論~